
Почему обнаружение мутаций TP53 на цифровых слайдах остается проблемой
18 июля 2025 г.Таблица ссылок
Аннотация и I. Введение
Материалы и методы
2.1. Multiple Instance Learning
2.2. Модель архитектуры
Результаты
3.1. Методы обучения
3.2. Наборы данных
3.3. WSI предварительно обработайте трубопровод
3.4. Результаты классификации и обнаружения ROI
Дискуссия
4.1. Задача обнаружения опухоли
4.2. Задача обнаружения мутаций генов
Выводы
Благодарности
Авторская декларация и ссылки
4.2. Задача обнаружения мутаций генов
Для уровня увеличения 5x производительность моделей была плохой (таблица 2). Модель Amil показала наилучшую производительность со средним AUC 0,605. Гипотеза, которая уже была подтверждена результатами в предыдущей работе [24], все еще поддерживается здесь: плитки при увеличении 5 -кратного увеличения, уровень, на котором видна только ткань, не может показать заметных доказательств мутаций TP53 для большинства случаев. Следовательно, что касается способности модели идентифицировать мутации для этого гена, невозможно сделать выводы из этого уровня увеличения.
На уровне 10x мы получили гораздо лучшие результаты AUC (таблица 2). Модель Amil по -прежнему показывает наилучшую производительность с точки зрения его среднего AUC (0,711), но модель Admil также представляет разумную оценку (0,624). Однако наша версия Admil не улучшилась для большинства пробежек со средним баллом 0,547.
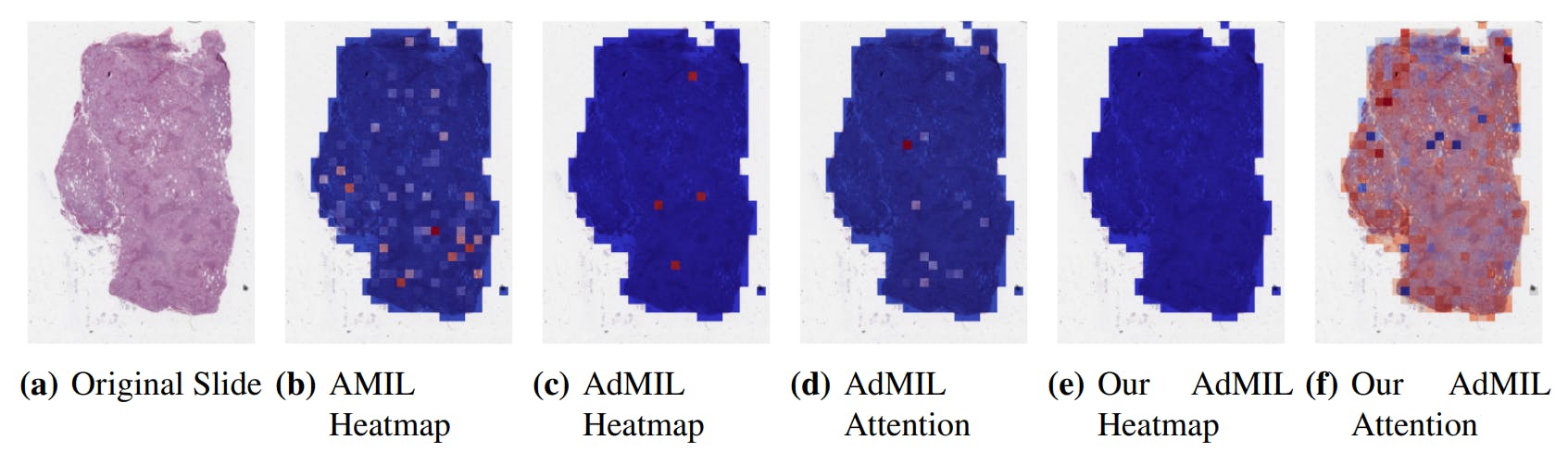
Для этой задачи, на этом уровне количество пятен, выделенных в тепловых картах, далеко. В случае модели Amil, в отличие от предыдущей задачи, механизм внимания больше внимания уделял внутренним пятнам (рис. 8 (b)). Это может быть связано с тем, что он ищет другую схему в морфологии, которая может не присутствовать в границах, но также верно, что на этих уровнях увеличения количество пятен с фоном более скудно, в отличие от предыдущей задачи.
Оригинальная модель Admil была сосредоточена на очень коротком количестве пятен (рис. 8 (c)). Несмотря на то, что он классифицирует слайды как демонстрации признаков мутации TP53, на этом уровне увеличения он, по -видимому, не может указывать на соответствующие области, только выделяя отдельные участки, которые являются отдаленными и изолированными друг от друга. Как и в задаче обнаружения опухоли, его механизм внимания сосредоточился только на небольшом количестве пятен (рис. 8 (d)).
Наша версия Admil, с другой стороны, не может идентифицировать любые возбуждающие участки из большинства WSI (рис. 8 (e)). Это может быть связано с тем фактом, что его механизм внимания не способен провести заметное различие между участками, приписывая очень похожие показатели внимания всем им (рис. 8 (f)). Это также объясняет низкий средний AUC, полученный этой моделью на этом уровне увеличения.
На уровне 20x результаты не сильно изменились для Амила и Амила, но значительно улучшились для нашей модифицированной версии Admil, с оценкой AUC 0,642. Для этого уровня произведенные тепловые карты также не показывали много изменений от увеличения 10x. Тем не менее, интересно заметить, что оценки внимания, созданные нашей версией Admil, в отличие от предыдущего уровня, сосредоточенные вокруг конкретной области на WSI (рис. 9 (f)). Тем не менее, эта модель продолжает производить только ингибирующие оценки.
Оценки AUC, полученные нашими моделями для уровней 10x и 20x, сопоставимы с тем, которые были получены в предыдущей работе [4, 17], хотя мы использовали более простые архитектуры. Тем не менее, это сравнение должно быть осторожно проходить, поскольку модели были обучены различным наборам данных (с различными методами предварительной обработки плитки) и часто для различного типа генной мутации.
В целом, количественные результаты для этой задачи не так хороши, как результаты задачи обнаружения опухоли. Производимые тепловые карты, по -видимому, не выделяют значительное количество пятен. Это может быть связано с тем, что признаки мутации TP53 могут показаться более изолированными на этих слайдах. Как и для предыдущей задачи, должна была бы быть сделана дальнейшая оценка тепловых карт специалистами, чтобы достичь определенного вывода.
Мы предполагаем, что способность моделей изучать шаблоны, связанные с мутацией TP53, могла повлиять на использованный набор данных. Хотя мы использовали только слайды FFPE, которые, как правило, лучше для вычислительного анализа WSI, тот факт, что из -за ограничений времени наши мешки WSI были построены с использованием случайного отбора проб, мог бы снизить качество их представления слайда. Кроме того, мы предположили, что все слайды, принадлежащие к положительному пациенту, также являются положительными. Все эти факторы могли бы ввести слишком много шума в набор данных.
Помимо возможности слишком большого количества шума, мы приходим к выводу, что обнаружение паттернов мутации TP53 на цифровых слайдах с помощью MIL и механизмов внимания является гораздо более сложной задачей, и результаты не так хороши, как при обнаружении наличия опухолей.
Авторы:
(1) Мармим Афонсо, институт Superior Técnico, Universidade de Lisboa, Av. Ровиско Паис, Лиссабон, 1049-001, Португалия;
(2) Praphulla M.S. Bhawsar, Отдел эпидемиологии и генетики рака, Национальный институт рака, Национальный институт здравоохранения, Bethesda, 20850, штат Мэриленд, США;
(3) Monjoy Saha, Отделение эпидемиологии и генетики рака, Национальный институт рака, Национальный институт здравоохранения, Bethesda, 20850, штат Мэриленд, США;
(4) Джонас С. Алмейда, Отделение эпидемиологии и генетики рака, Национальный институт рака, Национальный институт здравоохранения, Бетесда, 20850, штат Мэриленд, США;
(5) Арлиндо Л. Оливейра, Институт Верхний Течнико, Университет де Лисбоа, ав. Rovisco Pais, Лиссабон, 1049-001, Португалия и INESC-ID, R. Alves Redol 9, Lisbon, 1000-029, Португалия.
Эта статья есть
Оригинал