Более 80% передач, которые люди смотрят на Netflix, обнаруживаются через система рекомендаций. Это означает, что большая часть того, что бросается в глаза, является результатом решений, принятых сложной машиной.
Потоковая служба полагается на искусственный интеллект, чтобы анализировать нюансы в контенте и углубляться в предпочтения зрителей. И можно с уверенностью сказать: усилия окупаются!
Если вы все еще отстаете, но хотите улучшить впечатление клиентов от вашего бизнеса, продолжайте читать. В этой записи блога мы расскажем вам о процессе создания механизма рекомендаций и расскажем обо всем, что вам нужно знать, прежде чем обращаться к поставщикам услуг ИИ.
Системы рекомендаций 101: что нужно знать перед тем, как приступить к разработке
Прежде чем мы приступим к созданию механизма рекомендаций, давайте рассмотрим его типы, варианты использования и варианты реализации.
Типы систем рекомендаций
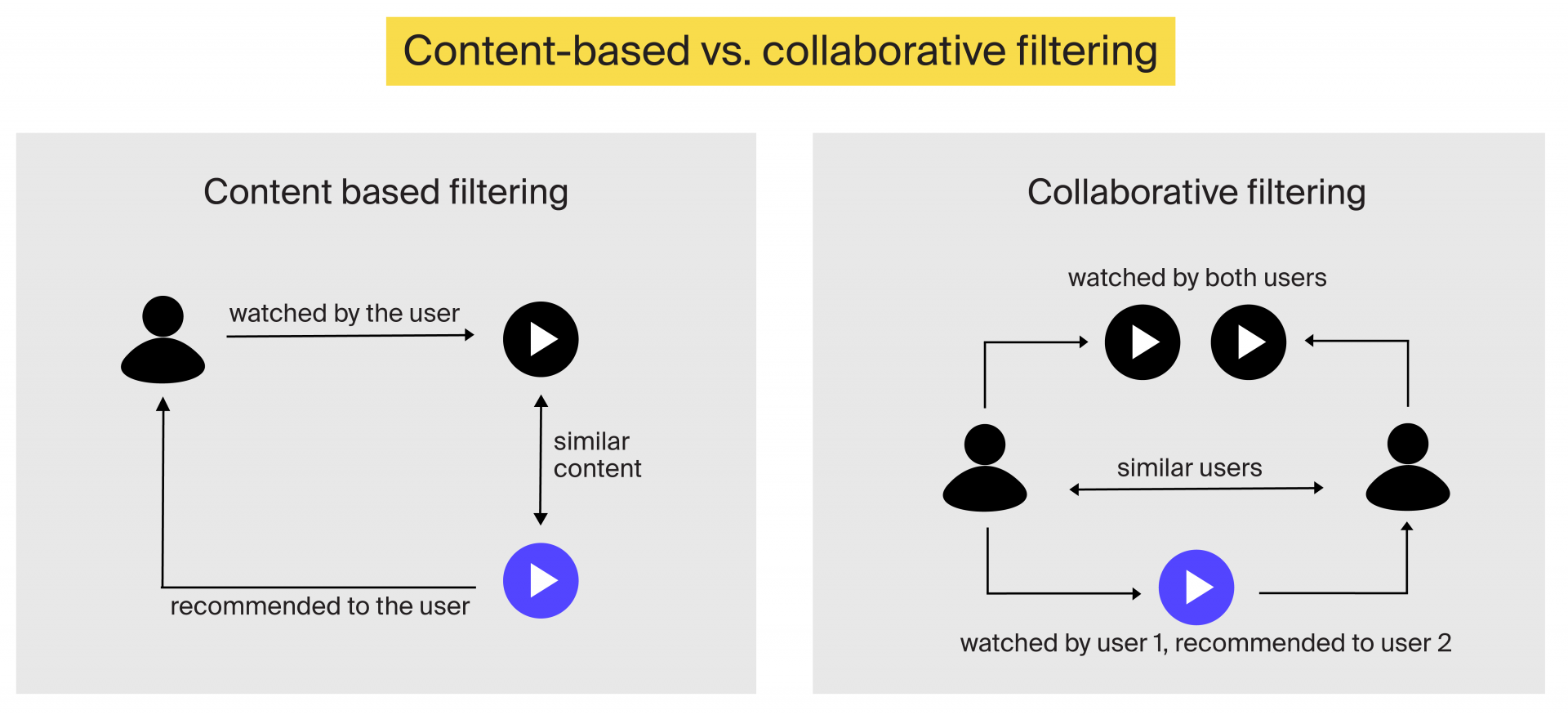
Традиционно рекомендательные системы делятся на две большие категории: фильтрация на основе контента и системы совместной фильтрации.
Контентная фильтрация
Системы фильтрации на основе контента генерируют рекомендации на основе характеристик или особенностей контента. Другими словами, они рекомендуют продукты или контент, похожие на те, которые понравились пользователю или с которыми он взаимодействовал ранее. Таким образом, система рекомендаций может предложить «Прощай, оружие» читателю, которому понравились «На Западном фронте без перемен» и «Уловка-22».
Но как движок узнает, какие элементы похожи? Давайте посмотрим на подход Netflix к созданию механизма рекомендаций, чтобы понять это. Хотя система рекомендаций Netflix носит гибридный характер, она в значительной степени зависит от схожести контента.
В стриминговом сервисе есть команда тегеров, которые просматривают каждый новый фрагмент контента и маркируют его. Теги варьируются в широком диапазоне от того, насколько экшн произведение, до того, происходит ли оно в космосе или в нем играет конкретный актер. Анализ данных тегов в сравнении с поведением зрителей с помощью алгоритмов машинного обучения позволяет потоковой платформе определить, что действительно важно для каждого пользователя.
Совместная фильтрация
Системы совместной фильтрации дают рекомендации на основе пользователя. отзыв. Такие системы предполагают, что пользователи, которым понравились похожие товары, скорее всего, будут одинаково реагировать на новые продукты и контент.
Существует два подхода к созданию системы рекомендаций на основе совместной фильтрации: на основе пользователей и на основе элементов.
С фильтрацией на основе пользователей вы создаете сегменты похожих пользователей с общими предпочтениями. Так, пользователю, скорее всего, порекомендуют товар, который понравился другим пользователям из этого сегмента. Особенности контента не учитываются.
При фильтрации на основе элементов механизм создает рекомендации на основе сходства элементов, которые понравились пользователю, с предложенными. Звучит похоже на фильтрацию на основе контента, не так ли? Хотя системы фильтрации на основе контента и совместной фильтрации на основе элементов используют сходство элементов для выдачи рекомендаций, они различаются в том, как они определяют сходство.
Системы фильтрации на основе контента просто рекомендуют элементы, похожие на те, которые уже понравились пользователю. Благодаря совместной фильтрации на основе элементов вам будет рекомендован элемент, похожий на то, что вам понравилось, и который нравится пользователям вашего сегмента.
Случаи использования систем рекомендаций
Высокая степень персонализации стала необходимостью, которую ожидают пользователи, побуждая компании обогатить свой опыт работы в Интернете с помощью систем рекомендаций. Секторы, в которых механизмы рекомендаций стали довольно распространенными, охватывают:
* Розничная торговля и электронная коммерция. Механизмы рекомендаций в электронной коммерции могут делать все что угодно: от категоризации продуктов до предложения покупателям новых товаров для покупки. Воздействие, вызванное внедрением рекомендательного механизма в электронной коммерции и улучшенным обслуживанием клиентов, улучшенным маркетингом и более широкими возможностями для дополнительных продаж, трудно переоценить. Например, известный магнат электронной коммерции Amazon приносит 35 % своего дохода с помощью системы рекомендаций.
* Медиа и развлечения: от курирования плейлистов до предоставления персонализированных предложений на основе прошлых взаимодействий, системы рекомендаций помогают медиа и развлекательным платформам дольше привлекать пользователей, показывая им контент, который они иначе не обнаружили бы. Крупнейшие медиа- и развлекательные платформы, такие как YouTube, Netflix и Spotify в значительной степени полагаются на персонализированные рекомендации, созданные искусственным интеллектом, для привлечения и удержания новых пользователей. .
* Социальные сети. Сектор социальных сетей также использует технологии для предоставления персонализированных предложений. Помогая пользователям находить похожие страницы и аккаунты, платформы социальных сетей подталкивают своих пользователей к тому, чтобы они тратили больше времени на взаимодействие с контентом, что повышает рейтинг кликов и увеличивает доходы.
* Банковское дело и финансы: рекомендательные системы на основе искусственного интеллекта позволяют банкам анализировать транзакции пользователей и повышать продажи для увеличения доходов. Например, когда пользователь покупает билет на самолет стоимостью 500 долл. США, система рекомендаций автоматически предполагает, что он летит за границу, и предлагает купить туристический пакет со страховкой.

Варианты реализации на выбор
Приступая к созданию системы рекомендаций, вы столкнетесь с несколькими вариантами реализации со своими преимуществами и соображениями, а именно:
Системы рекомендаций Plug-and-play
Системы рекомендаций Plug-and-play предлагают удобный и простой способ включения персонализированных рекомендаций в ваш продукт или платформу. Они поставляются в готовом виде и предназначены для полной интеграции в существующую инфраструктуру.
Ключевое преимущество механизмов рекомендаций plug-and-play заключается в их простоте и удобстве использования. Обычно они разрабатываются так, чтобы быть удобными для пользователя, что позволяет даже нетехнической аудитории настраивать их с минимальными усилиями. Примеры готовых к работе систем рекомендаций относятся к таким платформам, как Recombee, Seldon и LiftIgniter.
Недостатком механизмов рекомендаций plug-and-play являются ограниченные возможности настройки и адаптации. Хотя они обеспечивают удобство и скорость, они могут не обеспечивать такой уровень гибкости и точной настройки, который предлагают индивидуальные решения.
Предварительно обученные облачные сервисы рекомендаций
Облачные рекомендательные механизмы позволяют использовать огромные вычислительные ресурсы и опыт поставщиков облачных услуг. Эти службы рекомендаций обычно предоставляют простые в использовании API, которые позволяют разработчикам легко интегрировать функции рекомендаций в свои приложения.
Облачные рекомендательные механизмы также обладают высокой масштабируемостью, что позволяет им обрабатывать большие базы пользователей и высокие нагрузки трафика. Еще одним преимуществом является постоянное совершенствование, поскольку базовые модели обновляются и уточняются поставщиками услуг.
Ведущие поставщики облачных услуг, такие как Amazon Web Services, Google Cloud Platform и Microsoft Azure, предлагают услуги предварительно обученных рекомендаций.
Факторы, которые следует учитывать при выборе предварительно обученных облачных сервисов рекомендаций, охватывают конфиденциальность данных, привязку к поставщику и требования к настройке. Хотя эти сервисы удобны и масштабируемы, они могут иметь ограничения в плане настройки алгоритмов рекомендаций в соответствии с конкретными потребностями вашего бизнеса.
Системы пользовательских рекомендаций
Механизмы пользовательских рекомендаций обеспечивают высочайшую степень гибкости и контроля, позволяя вам использовать проприетарные алгоритмы, использовать знания, относящиеся к предметной области, и учитывать нюансы ваших данных. Использование индивидуального подхода позволяет вам учитывать тонкости пользовательских предпочтений, характеристик элементов и контекстуальных факторов, что обычно приводит к более точным и актуальным рекомендациям.
Однако, хотя механизмы пользовательских рекомендаций обеспечивают наибольшую гибкость, они также требуют значительных ресурсов разработки, опыта в области машинного обучения и постоянного обслуживания. Поэтому, прежде чем создавать собственную систему рекомендаций, тщательно оцените потребности своего бизнеса, доступные ресурсы и долгосрочные цели.
Эмпирическое правило заключается в том, чтобы использовать собственный маршрут в следующих случаях:
* У вас есть уникальные бизнес-потребности: если у вашего бизнеса есть уникальные требования, которые не могут быть удовлетворены с помощью готовых решений, используйте индивидуальные решения. Это позволит вам адаптировать алгоритм под вашу конкретную задачу. Скажем, вы нишевая платформа электронной коммерции, продающая ремесленные товары. Когда дело доходит до предложения продуктов, у вас могут быть определенные требования: механизм рекомендаций должен учитывать такие факторы, как редкость продукта, мастерство и предпочтения пользователя в отношении определенных стилей или материалов. Создание механизма рекомендаций с нуля, скорее всего, позволит вам генерировать рекомендации, соответствующие предпочтениям пользователей.
* Вам нужен полный контроль и право собственности. Создание собственного механизма рекомендаций дает вам полный контроль над всем процессом создания рекомендаций: от предварительной обработки данных до выбора алгоритма и тонкой настройки. Это позволяет вам полностью владеть системой и адаптировать ее по мере развития вашего бизнеса, не полагаясь на сторонние решения.
* Вы обладаете знаниями в предметной области. Если у вас есть опыт в конкретной области или доступ к специализированным данным, которые могут значительно повысить точность рекомендаций, создание индивидуального решения позволит вам эффективно использовать эти знания. Разработав специальный механизм рекомендаций, вы можете включить функции или ограничения, характерные для предметной области, которые могут быть недоступны в предварительно обученных решениях.
* Вашему приложению требуется высокая масштабируемость и производительность: если вы ожидаете большого количества пользователей или элементов, имеете строгие ограничения на задержку или вам необходимо обрабатывать большие и сложные наборы данных, создание собственного механизма рекомендаций обеспечит вам гибкость. разработать и оптимизировать систему для максимальной масштабируемости и производительности. То же самое применимо, если вы хотите генерировать рекомендации в режиме реального времени или почти в реальном времени.
* Вы хотите получить конкурентное преимущество: если точные рекомендации являются основным фактором, отличающим ваш продукт или услугу, создание собственного механизма рекомендаций может дать вам конкурентное преимущество. Инвестиции в индивидуальное решение в этом случае могут предоставить возможность предоставить уникальный и персонализированный опыт, повысить вовлеченность, лояльность и удовлетворенность клиентов.
Создание собственного механизма рекомендаций, шаг за шагом
Предоставление персонализированных рекомендаций — это задача, обычно решаемая с помощью машинного обучения. Также можно использовать нейронные сети. Однако их роль в основном ограничивается предварительной обработкой обучающих данных. Вот ключевые этапы процесса создания механизма рекомендаций, которым пользуются разработчики машинного обучения компании ITRex.
Шаг 1. Задание направления
Начните разработку, задав направление для остальной части проекта. На этом этапе необходимо сделать следующее:
* Постановка целей и определение масштаба проекта
Четко обозначьте, чего вы собираетесь достичь с помощью системы рекомендаций, и сопоставьте поставленную цель с ограничениями ресурсов и бюджета. Например, если вы хотите улучшить взаимодействие с клиентами и увеличить продажи в своем интернет-магазине, вы можете ограничить объем проекта рекомендациями продуктов клиентам, которые уже совершили покупку. Сохранение масштаба достаточно узким требует меньших усилий, чем создание системы рекомендаций, ориентированной на всех клиентов, при этом потенциал рентабельности инвестиций остается достаточно высоким.
* Оценка доступных источников данных
Эффективность рекомендательной системы сильно зависит от объемов и качества обучающих данных. Прежде чем приступить к обучению, внимательно оцените, достаточно ли у вас данных для создания рекомендаций.
* Определение показателей эффективности
Одной из ключевых проблем при создании системы рекомендаций, которую следует учитывать с самого начала, является определение показателей успеха. Прежде чем приступить к обучению алгоритмов машинного обучения, придумайте способ определить, действительно ли пользователям нравятся новые рекомендации.
Шаг 2. Соберите данные для обучения
Следующим шагом в процессе создания пользовательской системы рекомендаций является сбор и подготовка данных для обучающей машины. алгоритмы обучения. Чтобы создать надежную систему рекомендаций, вам нужно достаточно данных о предпочтениях пользователей.
В зависимости от подхода к созданию механизма рекомендаций ваш фокус будет смещаться. При создании системы совместной фильтрации данные, которые вы собираете, сосредоточены вокруг поведение пользователей. С системами фильтрации на основе контента вы концентрируетесь на особенностях контента, которые нравятся пользователям.
Совместная фильтрация
Данные о поведении пользователей могут поступать в разных формах:
* Явная обратная связь с пользователем — это все, что требует от пользователя усилий, например написание отзыва, оценка контента или продукта, жалоба или инициирование возврата. * Скрытые отзывы пользователей, такие как история прошлых покупок, время, которое пользователь тратит на просмотр определенного предложения, привычки просмотра/слушания, отзывы, оставленные в социальных сетях, и многое другое.
При создании системы рекомендаций мы советуем сочетать явную и неявную обратную связь, поскольку последняя позволяет изучить предпочтения пользователей, которые они могут неохотно признавать, что делает систему более точной.

Контентная фильтрация
При сборе данных для систем фильтрации контента очень важно понимать, на какие функции продукта/контента следует полагаться при изучении того, что нравится пользователям.
Предположим, вы создаете систему рекомендаций для любителей музыки. Вы можете полагаться на анализ спектрограмм, чтобы понять, какую музыку любит конкретный пользователь, и порекомендовать мелодии с похожими спектрограммами.
Кроме того, вы можете выбрать тексты песен в качестве основы для своих рекомендаций и порекомендовать песни, затрагивающие схожие темы.
Главное — протестировать и настроить, чтобы понять, что лучше всего подходит для вас, и быть готовым постоянно улучшать исходную модель.
Шаг 3. Очистите и обработайте данные
Чтобы создать высокоэффективную систему рекомендаций, необходимо учитывать меняющиеся вкусы пользователей. В зависимости от того, что вы порекомендуете, старые отзывы или оценки могут стать неактуальными.
Во избежание неточностей рассматривайте только те функции, которые с большей вероятностью отражают текущие вкусы пользователей, удаляйте данные, которые больше не актуальны, и придавайте большее значение недавним действиям пользователей, а не более ранним.
Шаг 4. Выберите оптимальный алгоритм
Следующим шагом в процессе создания системы рекомендаций является выбор алгоритма машинного обучения, подходящего для вашей задачи. специалисты по данным ITRex рекомендуют рассмотреть следующие:
* Матричная факторизация разбивает большой набор данных на более мелкие части, чтобы выявить скрытые закономерности и сходства между пользователями и элементами.
* Тензорная факторизация — это расширение матричной факторизации, которое может обрабатывать многомерные структуры данных, называемые тензорами. Он фиксирует более сложные шаблоны, разлагая тензоры на скрытые факторы, обеспечивая более детальное понимание взаимодействия пользователя с элементом.
* Машины факторизации — это мощные модели, которые могут обрабатывать многомерные и разреженные данные. Они фиксируют взаимодействие между функциями и могут применяться к задачам рекомендаций. Принимая во внимание взаимодействие функций, они могут предоставить точные рекомендации, даже если данные неполны.
* Модели соседства находят сходство между пользователями или элементами на основе атрибутов или поведения. Особенно эффективны для совместной фильтрации, они устанавливают связи между пользователями или элементами в сети и дают рекомендации на основе предпочтений похожих пользователей или элементов.
* Random Walk – это алгоритм на основе графа, который исследует связи между элементами или пользователями в сети. Перемещаясь по сети, он фиксирует сходство между элементами или пользователями и дает рекомендации на основе зафиксированных связей.
* SLIM – это метод, используемый в системах рекомендаций для понимания того, как элементы связаны друг с другом. Основное внимание уделяется поиску закономерностей в отношениях между элементами и использованию этих закономерностей для выдачи рекомендаций.
* Линейные модели предсказывают предпочтения пользователей в отношении элементов на основе линейных отношений между функциями. Хотя их легко понять и быстро обучить, они могут отражать сложные шаблоны не так эффективно, как другие подходы.
Кроме того, вы можете выбрать одну из следующих моделей глубокого обучения:
* DSSM (глубоко структурированные семантические модели) изучают представления текста или документов. Они сосредоточены на улавливании семантического значения слов и их взаимосвязей в рамках структурированной структуры.
* Сверточные сети на основе графов предназначены для данных, структурированных на основе графов. Они работают с графами, фиксируя взаимосвязи и взаимодействия между узлами графа.
* Variational Auto-Encoder – это генеративная модель, которая изучает представления данных, захватывая лежащее в их основе скрытое пространство. Эти модели используют архитектуру кодер-декодер для сжатия данных в пространство с меньшими размерностями и их реконструкции.
* Transformer — это модель, использующая механизмы внутреннего внимания для захвата контекстных отношений между словами в предложении или документе.
Важно отметить, что описанные выше методы редко используются изолированно. Вместо этого они объединяются с помощью следующих методов и алгоритмов:
* Ансемблирование предполагает независимое обучение нескольких моделей и последующее объединение их прогнозов с помощью различных методов. Каждая модель в равной степени влияет на окончательный прогноз, и их комбинация обычно проста и не требует обучения дополнительных моделей.
* Стекирование использует более продвинутый подход. Он включает в себя обучение нескольких моделей, называемых базовыми моделями, а затем объединение их прогнозов с помощью метамодели. Базовые модели делают прогнозы на основе входных данных, и их прогнозы становятся входными функциями для метамодели. Затем метамодель обучается, чтобы сделать окончательный прогноз.
* AdaBoost – это ансамблевый алгоритм обучения, который повышает точность базовых моделей за счет их итеративного обучения на различных подмножествах данных. Подход фокусируется на экземплярах, которые трудно правильно классифицировать, и уделяет им больше внимания в последующих итерациях обучения. В каждой итерации AdaBoost присваивает веса обучающим экземплярам на основе точности их классификации. Затем он обучает плохо работающие модели на взвешенных данных, где веса подчеркивают неправильно классифицированные экземпляры из предыдущих итераций.
* XGBoost – это ансамблевый метод, который итеративно объединяет слабые модели прогнозирования для создания более надежной модели. Он обучает модели последовательно, при этом каждая последующая модель исправляет ошибки, допущенные предыдущей.

Шаг 4. Обучение и проверка модели
После того как вы определились с алгоритмом системы рекомендаций, пришло время обучить и проверить модель. Вот как выглядит этот шаг в процессе создания системы рекомендаций:
Для начала вам нужно разделить ваши данные на два набора: обучающий набор и набор для тестирования. Обучающий набор, как следует из названия, учит вашу модель распознавать закономерности в пользовательских предпочтениях. Набор для тестирования помогает оценить производительность модели на новых данных.
Имея под рукой тренировочный набор, начните тренировать свою модель. Это предполагает взаимодействие алгоритма с данными, что позволяет ему изучить основные закономерности и взаимосвязи.
После этапа обучения пришло время оценить производительность модели с помощью тестового набора. Это поможет вам понять, насколько эффективно модель обобщает новые данные.
Кроме того, вы можете полагаться на обратную связь в режиме реального времени, чтобы понять, насколько хорошо работает модель. Таким образом, вы развертываете модель в рабочей среде и сопоставляете сгенерированные рекомендации с отзывами пользователей. Затем вы переходите к следующему шагу, где вы настраиваете модель на корректировку своих параметров посредством итеративного процесса обучения.
Шаг 5. Настройте гиперпараметры модели
После того, как вы оценили производительность модели, вы можете настроить ее по мере необходимости. Рассмотрим пример системы рекомендаций, построенной на алгоритме совместной фильтрации.
При совместной фильтрации количество соседей определяет, сколько похожих пользователей или элементов учитывается при выработке рекомендаций. Предположим, вы создаете механизм рекомендаций, основанный на совместной фильтрации и предлагающий новые фильмы. Изначально вы установили количество соседей равным 10, что означает, что модель учитывает предпочтения 10 наиболее похожих пользователей при создании рекомендаций.
Оценив производительность модели, вы обнаружите, что точность рекомендаций ниже желаемой. Чтобы улучшить это, вы решаете настроить модель, изменив количество соседей.
Чтобы изучить влияние различных размеров соседей, вы можете провести эксперименты со значениями диапазона. Например, уменьшение числа соседей до 5 может привести к значительному увеличению точности. Однако вы можете заметить небольшое снижение отзыва, указывающее на то, что модель упускает некоторые важные рекомендации. Увеличение числа 20, в свою очередь, может привести к небольшому улучшению запоминания, но предложения могут стать менее персонализированными.
Главное — найти компромисс между точностью и полнотой, а также найти баланс между учетом разнообразных пользовательских предпочтений и предоставлением точных рекомендаций.
Шаг 6. Внедрение, мониторинг и обновление модели
После того, как модель настроена и готова к работе, пришло время ее реализовать.
Чтобы обеспечить успешное внедрение, рассмотрите наиболее эффективный способ включения модели в существующую инфраструктуру. Например, вы можете встроить модель в серверную часть вашего веб-сайта, обеспечив беспрепятственное взаимодействие с пользовательским интерфейсом. Эта интеграция позволяет давать рекомендации в реальном времени, которые динамически адаптируются к предпочтениям пользователей.
В качестве альтернативы вы можете развернуть модель как службу, например API системы рекомендаций, к которой могут легко обращаться другие компоненты вашего приложения. Этот сервис-ориентированный подход обеспечивает гибкость и масштабируемость, позволяя вашему приложению легко использовать возможности системы рекомендаций.
Этап реализации также является хорошим моментом для рассмотрения того, как рекомендации будут представлены пользователям. Будут ли они отображаться в виде персонализированных предложений на главной странице веб-сайта, аккуратно распределенных по категориям в интуитивно понятном интерфейсе? Или они будут органично интегрированы в интерфейс приложения, появляясь в нужный момент, чтобы удивить пользователей? Выбор за вами, но всегда ставьте во главу угла удобство для пользователя.
Наконец, крайне важно тщательно протестировать реализованную модель, чтобы убедиться в ее бесперебойной работе. Проведите всестороннее тестирование, чтобы проверить его производительность и поведение при различных взаимодействиях с пользователем, чтобы убедиться, что рекомендации точны, своевременны и соответствуют ожиданиям пользователей.
Проблемы создания системы рекомендаций и способы их решения
Понимание сложностей создания механизма рекомендаций имеет решающее значение для предоставления персонализированных и релевантных рекомендаций. Вот краткое изложение наиболее распространенных:
Задача 1. Измерение успеха
Одной из ключевых проблем при создании системы рекомендаций, которую следует учитывать с самого начала, является определение показателей успеха. Другими словами, прежде чем вы приступите к сбору данных и обучению алгоритмов машинного обучения, вы должны разработать надежный способ определить, действительно ли пользователям нравятся вновь созданные рекомендации. Это поможет вам в процессе разработки.
Скажем, вы — стриминговая платформа. Вы можете подсчитать количество лайков или ежемесячных платных подписок, чтобы оценить, насколько хорошо работает ваш механизм рекомендаций. Однако есть вероятность, что ваши рекомендации верны, а пользователи не хотят явно заявлять о своих предпочтениях или платить за услугу.
Опыт наших специалистов по данным показывает, что поведение пользователей — более надежный способ измерения эффективности системы рекомендаций. Мы не сомневаемся, что пользователю понравилось шоу, если он посмотрел его за одну ночь, даже если не было явного отзыва.
Вызов 2. Проклятие размерности
Размерность данных относится к количеству объектов в наборе данных. Дополнительные входные функции часто усложняют создание точного механизма рекомендаций. Возьмем в качестве примера YouTube. На платформе сосуществуют миллиарды видео и пользователей, и каждый пользователь ищет персональные рекомендации. Однако человеческие и вычислительные ресурсы ограничены, и вряд ли кто-то захочет часами ждать загрузки рекомендаций.
Чтобы решить эту проблему, перед запуском алгоритма рекомендаций необходим дополнительный шаг — генерация кандидатов. Этот шаг позволяет сузить миллиарды видео, скажем, до десятков тысяч. Затем эта меньшая группа используется для создания рекомендаций.
Для генерации кандидатов используются различные стратегии, из которых поиск ближайшего соседа является наиболее популярным. Другие распространенные методы преодоления проблемы многомерности включают изучение популярных категорий или предпочтений, разделяемых людьми схожей возрастной группы.
Задание 3. Холодный старт
Еще одна распространенная проблема в процессе создания механизма рекомендаций — головоломка холодного запуска. Она возникает, когда системе не хватает достаточной информации о пользователе или элементе, что затрудняет предоставление точных рекомендаций. Для преодоления этого препятствия необходимо использовать такие методы, как совместная фильтрация, фильтрация на основе контента или гибридные подходы.
Задание 4. Длинный хвост
Системы рекомендаций могут страдать от явления, известного как "длинный хвост". Это означает, что популярные товары получают больше внимания и рекомендаций, а менее популярные остаются незамеченными пользователями. Для решения этой проблемы необходимо создавать персонализированные рекомендации и учитывать индивидуальные предпочтения пользователей.
Вызов 5. Холодный старт для новых предметов
Когда в систему добавляется новый элемент, у него практически нет исторических данных для создания рекомендаций, что затрудняет создание релевантных предложений. Одним из подходов к решению этой проблемы является использование фильтров контента и активное привлечение пользователей к взаимодействию с новыми элементами с помощью рекламных акций или рекламы.
Вызов 6. Холодный старт для новых пользователей
Точно так же новые пользователи могут не располагать достаточными историческими данными для получения точных рекомендаций. Чтобы решить эту проблему, можно использовать такие методы, как фильтрация контента, запросы обратной связи и первоначальные опросы пользователей.
Задача 7. Разреженность данных
В рекомендательных системах разреженность данных – обычное явление, когда многие пользователи оценивают небольшое количество элементов или взаимодействуют с ними. Это создает проблему в прогнозировании предпочтений пользователей. Для решения этой проблемы можно использовать методы матричной факторизации, включающие уменьшение размерности, регуляризацию и другие методы.
Подводя итог
Создание системы рекомендаций – это процесс, основанный на алгоритмах, данных пользователей и постоянном совершенствовании. От определения проблемы до выбора правильного подхода, тщательной предварительной обработки данных и обучения модели — каждый шаг способствует созданию мощной системы рекомендаций.
Способность механизма рекомендаций понимать предпочтения пользователей и предоставлять индивидуальные рекомендации может иметь огромный потенциал для вашего бизнеса. Amazon, YouTube, Spotify и многие другие менее известные, но не менее успешные компании произвели революцию в своих продуктах и впоследствии увеличили свои доходы за счет индивидуальных рекомендаций.
Например, Spotify, платформа для потоковой передачи музыки, которая полагается на персонализированные рекомендации как на ключевой отличительный фактор, продолжает ежегодно увеличивать свою пользовательскую базу и доходы. Только в четвертом квартале 2022 года обещание открыть для себя новую любимую песню привлекла к платформе на 20 % больше активных пользователей в месяц, что привело к 33 миллионам новых пользователей.
Если вы все еще отстаете, пришло время использовать возможности искусственного интеллекта и революционизировать ваш пользовательский интерфейс с помощью системы настраиваемых рекомендаций.
<цитата>Хотите усовершенствовать свое решение с помощью мощного механизма рекомендаций? Обратитесь к консультантам ITRex.
:::информация Также опубликовано здесь
:::