

Почему и как мы разделяем набор данных
1 марта 2022 г.Набор данных — одна из важных частей проекта машинного обучения. Без данных машинное обучение — это просто машина, а обучение вычеркнуто из названия. Чего машины и люди с глубоким обучением не выдержат и будут протестовать за данные 😅 .
Введение
Поскольку данные настолько важны, когда у нас есть набор данных, содержащий несколько сотен или меньше строк данных, мы должны сохранить некоторую часть данных для целей тестирования. Как только программное обеспечение будет готово, мы должны протестировать его, прежде чем выводить на рынок, где оно будет принимать решения и влиять на жизнь людей. поэтому ожидается, что модель не будет делать ошибок или если, то по крайней мере.
Таким образом, тестирование становится важной частью разработки и машинного обучения, поскольку мы работаем с данными, поэтому у нас также должны быть некоторые данные для целей тестирования.
Цель тестовых данных такова, что, будучи отложенными, эти данные никогда не должны быть доступны для модели машинного обучения до тех пор, пока обучение не будет завершено, и тогда и только тогда мы должны ввести тестовые данные в модель машинного обучения, которая была обучен на некоторых данных, частью которых являются данные тестирования.
Поскольку мы поняли, «зачем» данные тестирования, давайте посмотрим, «как» мы сохраняем эти данные для целей тестирования?
мы будем работать с «калифорнийским набором данных» из [Kaggle] (https://kaggle.com), мы загрузим набор данных с «пандами», а затем сделаем «разделение». Мы можем сделать разбиение двумя способами:
- Вручную путем выбора диапазонов показателей
- Использование функции Sklearn.
```питон
импортировать панд как pd
набор данных = pd.read_csv (жилье.csv)
набор данных.голова()
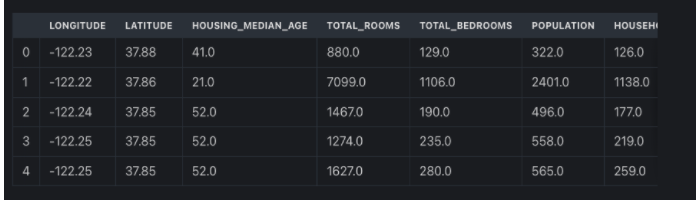
![Набор данных о жилье в Калифорнии] (https://cdn.hackernoon.com/images/-oo93ht0.png)
После загрузки данных мы можем увидеть с помощью head() первые 5 строк набора данных, чтобы получить представление о наборе данных. Теперь, когда у нас есть полный набор данных в переменной набора данных, мы готовы сделать разделение. Но сначала давайте посмотрим длину набора данных, чтобы мы могли снова увидеть эту длину после «разделения» и убедиться, что разделение было успешным.
```питон
len(набор данных)
Эта простая функция len () дает нам количество строк, присутствующих в наборе данных, которое составляет «20640».
Теперь мы увидим, как сделать разбиение «вручную с помощью индексации».
Использование ручного индексирования
Здесь, в этом методе, идея состоит в том, что мы хотим указать, до какого индекса мы хотим «обучение» и от какого индекса мы хотим «набор для тестирования» или наоборот.
Синтаксис прост и понятен: dataset_variable[strat:end]
```питон
поезд = набор данных [: 16000]
тест = набор данных [16000:]
В приведенном выше примере мы просто говорим следующее:
- От начала, т.е. 0 индекса до 16000 индексов, получите строки данных и поместите их в обучающую переменную, т.е. мы создаем обучающий набор, содержащий первые 16000 строк.
- С 16000 до конца поместите строки в тестовый набор.
После запуска этой строки кода, если мы теперь увидим длину «train» и «test», мы получим «16000» и «4640».
лен (поезд)
16000
Лен(тест)
4640
Дело в том, что здесь мы должны знать индексы, до которых или от которых мы хотим разделить, а также еще один недостаток заключается в том, что мы не можем перемешивать строки данных здесь. Если нам нужно перетасовать, мы должны добавить еще один шаг к процессу. То есть перед разделением мы должны вручную перетасовать набор данных, а затем выполнить разделение на основе индекса.
Теперь, когда мы используем sklearn, эти шаги выполняются всего одним параметром, и нам не нужно беспокоиться об индексах и других вещах.
Теперь давайте посмотрим, как сделать то же самое, используя функцию Sklarn train_test_split.
train_test_split от Sklearn
```питон
из sklearn.model_selection импорта train_test_split
Итак, эта потрясающая и небесная функция импортирована из модуля sklearn model_selection и проста как пирог. После импорта все, что нам нужно сделать, это передать набор данных и размер «тестового набора», который мы хотим, и все готово.
Следует помнить, что если мы предоставляем набор данных в форме «DataFrame», мы получаем взамен два «фрейма данных», один для «обучения» и один для «тестирования».
```питон
обучение, тестирование = train_test_split (набор данных, test_size = 0,3, перемешивание = True, random_state = 32)
мы дали следующие параметры этой функции:
- «Набор данных» — весь набор данных, который у нас есть.
test_size– процент данных, которые мы хотим для тестового набора.
shuffle=True, хотим ли мы, чтобы наш набор данных был перемешан перед разделением или нет. ЕслиTrue, индексы будут перетасованы, а затем будет произведено разделение.
random_state=any_number– если установлено, то не имеет значения, сколько раз мы делаем сплит, каждый раз будет получаться один и тот же сплит.
Используя это, мы гарантируем, что тестовый набор всегда будет надежно защищен от модели.
Давайте посмотрим, что находится в переменных обучения и тестирования, которые были возвращены этой функцией. обучение содержит часть набора данных с 14448 строками, а индексы также перемешаны.
повышение квалификации
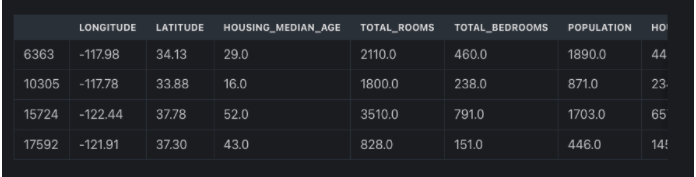
14448 строк × 10 столбцов
Аналогичным образом тестирование содержит 6192 строки, а также перемешанные индексы. Если мы посчитаем «30%» этого набора данных, получится 6192. Таким образом, «30%» наших данных находятся в тестовом наборе.
тестирование

6192 строки × 10 столбцов
Когда мы разделяем входные и выходные переменные.
Теперь, если мы разделим входные и выходные переменные на x как вход и y как выход. Затем в этом наборе данных у нас будет значение median_house_value в y, поскольку это выходная переменная, а остальные столбцы будут в «x» в качестве входных данных для модели.
Этот «x» будет вводом для модели, на которой модель будет обучаться вместе с «y». Но в будущем, когда модель будет делать прогнозы, она будет предсказывать «y» на основе «x». Давайте разделим набор данных на «x» и «y».
```питон
x = набор данных.drop ("median_house_value", ось = 1)
Здесь мы говорим: отбросьте median_house_value вдоль axis=1, то есть весь столбец или в направлении столбцов.
Примечание: «ось = 0» означает строку, а «ось = 1» — столбцы.
Таким образом, у нас будет x, в котором не будет median_house_value, а будут присутствовать все остальные столбцы.
Икс
20640 строк × 9 столбцов
Что действительно так.
Теперь давайте создадим наш y, написав следующий код.
```питон
у = набор данных['медианное_значение_дома']
Здесь мы говорим: возьмите этот столбец с именем median_house_value и поместите его в y. Просто, как это звучит.
у
0 452600.0 1 358500.0 2 352100.0 3 341300.0 4 342200.0 Имя: median_house_value, Длина: 20640, dtype: float64
Таким образом, у нас есть x и y.
Теперь, если мы передаем «x» и «y» в «train_test_split» вместо набора данных в целом, мы получим взамен 4 переменные. Две переменные для обучающего набора вводятся для обучения и выводятся для обучения и аналогично, две для набора для тестирования, а те вводятся для тестирования и выводятся для тестирования.
В приведенном ниже коде показан вывод функции с x и y.
```питон
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=0,3, shuffle=True, random_state=32)
Давайте посмотрим на «len» для «train_x», «train_y», «test_x» и «test_y».
```питон
print(fДлина Train_x: {len(train_x)} и длина train_y: {len(train_y)})
Длина Train_x: 14448 и длина train_y: 14448
```питон
print(fДлина Test_x: {len(test_x)} и длина test_y: {len(test_y)})
Длина Test_x: 6192 и длина test_y: 6192
Что действительно то же самое, что и выше, когда мы предоставили весь набор данных.
Заключение
В этом посте мы попытались понять необходимость разделения данных и как мы можем выполнить это разделение эффективным способом.
Мы изучаем руководство, а также современный, sklearn-способ, который делает большинство практиков машинного обучения. Я надеюсь, что вы поняли процесс и теперь сможете сделать то же самое и понять, почему и как этот процесс.
Это было все, спасибо. Пожалуйста, оставьте комментарий, а также поделитесь им.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27740)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)