

Где происходит контекстный перевод в больших языковых моделях: дополнительный анализ
2 сентября 2024 г.Авторы:
(1) Сюзанна Сиа, Университет Джонса Хопкинса;
(2) Дэвид Мюллер;
(3) Кевин Да.
Таблица ссылок
- Аннотация и 1. Фон
- 2. Данные и настройки
- 3. Где происходит контекстный машинный перевод?
- 4. Характеристика избыточности в слоях
- 5. Эффективность вывода
- 6. Дальнейший анализ
- 7. Заключение, благодарности и ссылки
- А. Приложение
6. Дальнейший анализ
В следующих разделах мы сосредоточимся на GPTNEO и BLOOM, чтобы провести более глубокий анализ основных явлений, представленных в статье.
6.1 Влияет ли количество подсказок на распознавание задачи?
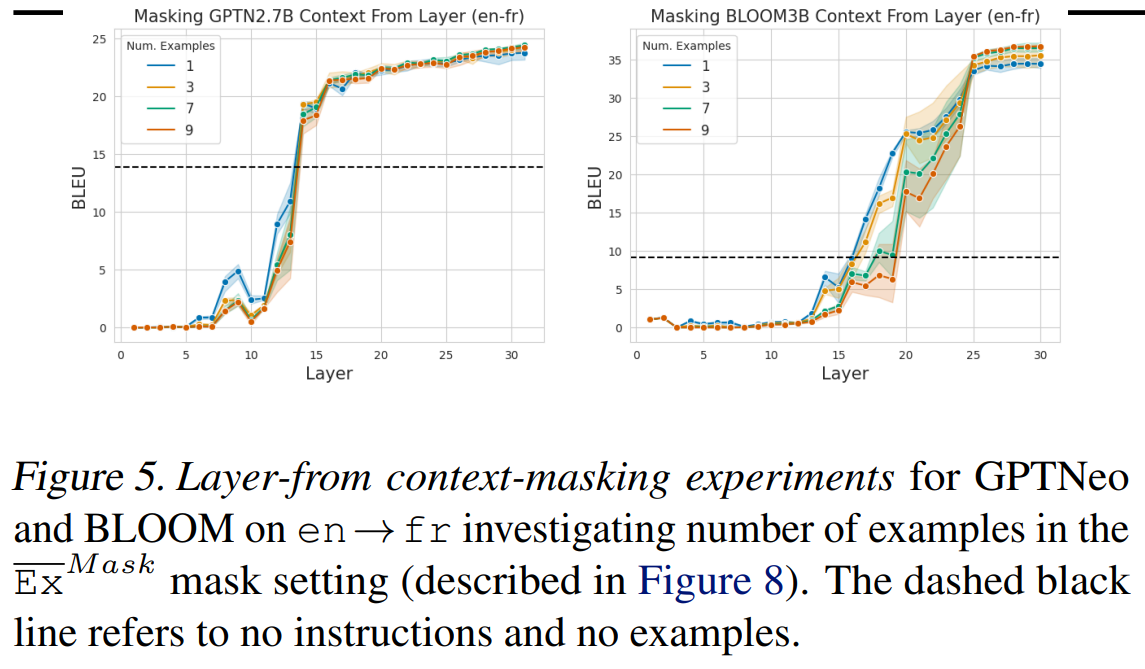
В разделе 3 мы изучаем маскировку контекста с фиксированным количеством подсказок. Однако неясно, влияет ли количество подсказок на то, насколько быстро, по слоям, модель способна распознавать задачу. Мы отобразили эти результаты для en→fr на рисунке 5 как для GPTNEO, так и для BLOOM. В целом мы обнаружили, что количество примеров подсказок мало влияет на то, на каком слое распознается задача. Хотя есть некоторые различия в производительности, когда контекст маскируется вокруг средних слоев модели, окончательное плато производительности происходит на том же слое независимо от количества подсказок.
6.2. Адаптивность слоев задач
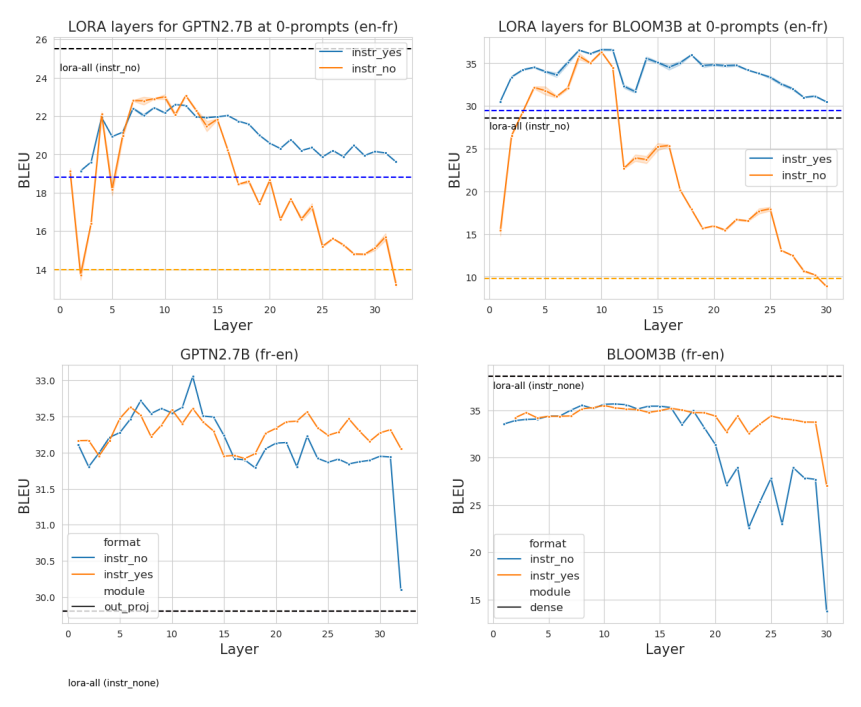
Интуитивно понятно, что слои до «распознавания задачи» должны содержать информацию о местоположении задачи MT. Чтобы проверить эту интуицию, мы дополнительно изучаем адаптивность этих слоев с помощью легких экспериментов по тонкой настройке. Мы обучили одну матрицу адаптации низкого ранга (LoRA; Hu et al. (2021)) для каждого слоя выходной проекции, оставив остальную часть сети замороженной.[4] Модели были показаны параллельные предложения в качестве входных данных, и слои были обучены без явных инструкций по переводу. Мы разделили набор разработки FLORES на 800 обучающих примеров и 200 примеров разработки. Обратите внимание, что эта настройка предназначена для настройки слоев на местоположение задачи. Крайне маловероятно, что модель может изучить знания о переводе из этого небольшого количества надзора. Слои LoRA были обучены в течение 50 эпох с терпением ранней остановки = 5 и порогом = 0,001, с α = 32, r = 32 и отсевом = 0,1. Потеря перекрестной энтропии была рассчитана только для целевого предложения (подробности см. в разделе A.5), и для оценки мы использовали лучшую контрольную точку из 200 сохраненных примеров разработки.
Результаты этого эксперимента показаны на рисунке 6; хотя каждый слой можно обучить работать лучше, чем без тонкой настройки, настройка разных слоев по-разному влияет на производительность. В частности, мы обнаружили, что высокопроизводительные слои находятся в более ранних и средних частях сети, а пик часто приходится на начало слоев «распределения задач» из раздела 3. В отличие от общепринятого мнения о тонкой настройке, дополнительная настройка на более поздних слоях оказывает гораздо меньшее влияние на конечную производительность для en → fr.
6.3. Существуют ли специальные головы для наблюдения?
В разделе 3 мы обнаружили, что более ранняя часть модели имеет решающее значение для локализации задачи из контекста подсказки, а в разделе 4.1 мы обнаружили как критические, так и избыточные слои для задачи MT. В этом разделе мы увеличиваем уровень детализации до уровня головок внимания вместо слоев.
Хорошо зарекомендовавший себя вывод для контролируемых моделей MT кодера-декодера заключается в том, что до 90% голов внимания могут быть отсечены при минимизации падения производительности перевода (Voita et al., 2019b; Behnke & Heafield, 2020; Michel et al., 2019). Мы отмечаем, что вопрос о степени отсечения является несколько плохо сформулированным исследовательским вопросом, поскольку он зависит от типа используемой техники отсечения. Однако в парадигме контролируемого MT наблюдались общие тенденции высокоотсекаемых моделей. В парадигме контекста явного контроля нет. Таким образом, неясно, распределены ли знания о задаче по гораздо большему количеству голов внимания или аналогичным образом специализированы для нескольких голов. Например, Бансал и др. (2023) изучали важность голов внимания для более широкого набора задач ICL, обнаружив, что наиболее важные головы для ICL находятся в средних слоях модели.
6.4 Тренировка внимания с регуляризацией L0

6.5 Изучение избыточности посредством сжатия
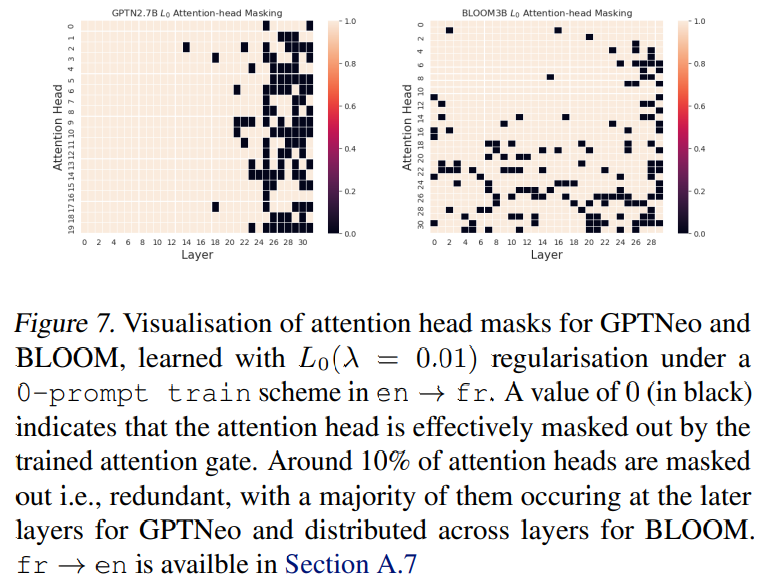
Мы отметили, что GPTNEO имеет некоторые критические отличия от BLOOM и LLAMA с точки зрения наличия критических слоев (см. Раздел 4.1). В какой степени существуют специализированные заголовки внимания для MT в моделях в стиле GPT? Если бы были специализированные заголовки, мы бы ожидали, что модель будет высокосжимаемой/обрезаемой до нескольких выбранных заголовков. Мы строим сетку карт изученных значений шлюза внимания для en → fr, где 0 указывает на то, что заголовок замаскирован (Рисунок 7). Мы обнаруживаем, что большинство замаскированных заголовков распределены на более поздних уровнях для GPTNeo и распределены по слоям для BLOOM. Это, по-видимому, согласуется с наблюдениями Раздела 4.1 о том, что избыточность более сосредоточена на определенных слоях в GPTNeo и более распределена по слоям для Bloom.
Кроме того, мы отмечаем, что нет «нескольких» специализированных голов, что прямо контрастирует с литературой по сжатию в контролируемых моделях MT (Voita et al., 2019b; Michel et al., 2019). Возможные причины этого различия могут включать распределение данных и архитектуру модели или потерю кросс-энтропии, связанную с настройкой задач для MT по сравнению с неспецифическим обучением на больших корпусах. Мы оставляем это как открытый вопрос для будущей работы.
Эта статьядоступно на arxivпо лицензии CC BY 4.0 DEED.
[4] Мы также экспериментировали с обучением отдельных слоев LoRA «Ключ», «Запрос» и «Значение», но обнаружили, что это менее эффективно.

[6] Класс конкретных распределений был изобретен для решения проблемы автоматической дифференциации графов стохастических вычислений.
Оригинал