

Где происходит контекстный перевод в больших языковых моделях: данные и настройки
2 сентября 2024 г.Авторы:
(1) Сюзанна Сиа, Университет Джонса Хопкинса;
(2) Дэвид Мюллер;
(3) Кевин Да.
Таблица ссылок
- Аннотация и 1. Фон
- 2. Данные и настройки
- 3. Где происходит контекстный машинный перевод?
- 4. Характеристика избыточности в слоях
- 5. Эффективность вывода
- 6. Дальнейший анализ
- 7. Заключение, благодарности и ссылки
- А. Приложение
2. Данные и настройки
МоделиМы используем GPTNEO2.7B (Black et al., 2021), BLOOM3B (Scao et al., 2022), LLAMA7B и LLAMA7Bchat (Touvron et al., 2023), вариант с настройкой инструкций, во всех наших экспериментах. GPTNEO2.7B имеет 32 слоя и 20 головок, BLOOM3B имеет 30 слоев и 32 головки, а LLAMA7B имеет 32 слоя и 32 головки. Контрольные точки, которые мы используем, взяты из библиотеки transformers (Wolf et al., 2019).
GPTNEO обучался на The PILE (Gao et al., 2020), текстовом наборе данных объемом 825 ГБ, который состоит примерно из 98% данных на английском языке. Несмотря на то, что The PILE в основном одноязычный, он содержит Europarl, на котором GPTNEO обучался на уровне документа (а не на уровне предложения). Напротив, BLOOM обучался на корпусе ROOTS (Laurençon et al., 2022), составной коллекции из 498 наборов данных, которые были явно выбраны как многоязычные, представляющие 46 естественных языков и 13 языков программирования. Обучающие данные LLAMA в основном состоят из Common Crawl, C4, Wikipedia, Stack Exchange в качестве основных источников. Насколько нам известно, не было никаких сообщений о параллельных корпусах на уровне предложений в обучающих наборах данных этих моделей.
Данные Мы тестируем наши модели с помощью FLORES (Goyal et al., 2021) en ↔ fr, о котором мы сообщаем в основной статье, и небольшого исследования по расширению Раздела 3 до en ↔ pt в Приложении. Примеры-подсказки взяты из набора для разработки. Мы оцениваем поколения с помощью оценок BLEU, следуя реализации из Post (2018).
Формат подсказкиНаши подсказки могут состоять из инструкций, примеров, того и другого или ни одной. Важно, что мы используем нейтральные разделители, "Q:" и "A:", чтобы отделить подсказку от начала машинного текста. Это гарантирует, что модели не получат никакой информации от разделителей о том, в чем заключается задача. [1]
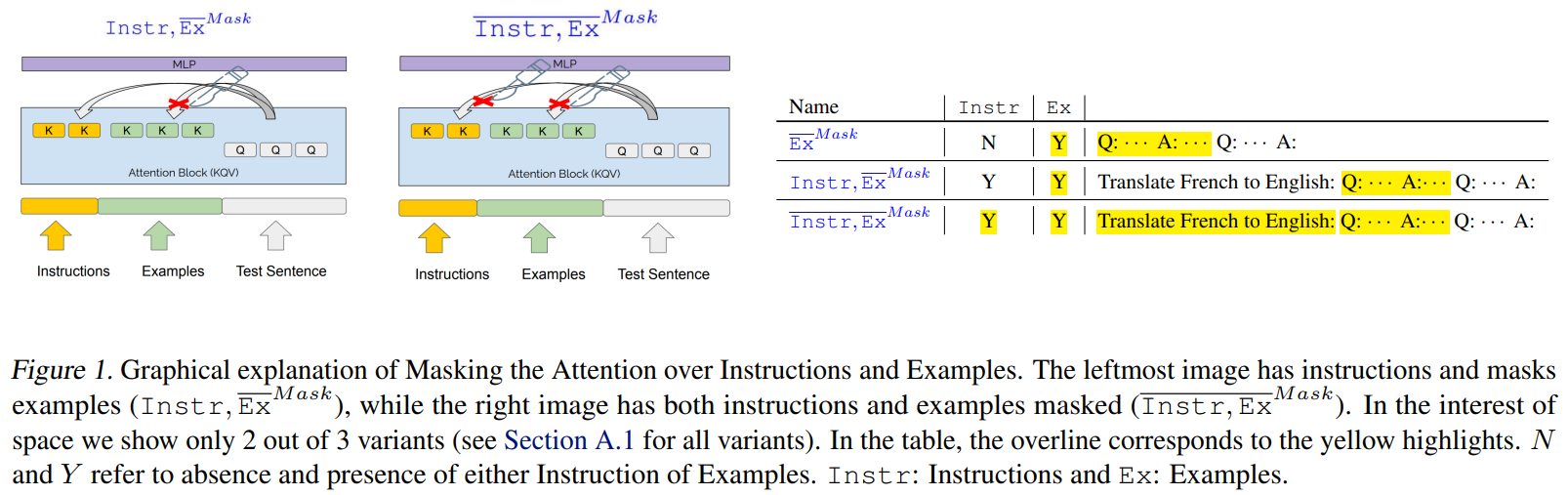
Если не используются инструкции на естественном языке, то входные данные модели будут Q: {source_sentence} A: Инструкции даются на естественном языке и имеют вид: Перевести с {L1} на {L2}: Q: {source_sentence} A:, где L1 = английский и L2 = французский, если исходный и целевой языки — английский и французский соответственно. Примеры приведены после инструкций и аналогичным образом разделены Q: и A:. См. Приложение: Таблица 1 для примера.
Эта статьядоступно на arxivпо лицензии CC BY 4.0 DEED.
[1] В более раннем исследовании мы обнаружили, что предоставление модели только языковых индикаторов, например, «английский:», «французский:», было достаточным для того, чтобы сильные модели (llama7b, llama7b-chat) могли выполнить задачу без просмотра каких-либо инструкций или примеров в контексте.
Оригинал
Recent Post
-
Когда ИИ становится посредником в семейных спорах о наследстве
20 августа 2025 г. -
Конец общей аннотации в здравоохранении: визуализация сердца показывает, почему
20 августа 2025 г. -
5 Рабочие процессы агента AI для повторяемого успеха (включен код)
20 августа 2025 г. -
Почему OCR борется со страницами с несколькими колоннами
20 августа 2025 г. -
Все, что я узнал (трудный путь) как начинающий основатель AI SaaS
20 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Астрофизика
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика
- Развлечения
- ИТ и автоматизация
- Криптовалюты и блокчейн
- История и идеология
- Медицина и политика
- Личная жизнь миллиардеров
- Образование и Политика
- Туризм и отдых
- Психология и искусственный интеллект
- Удаленная работа и производительность
- Выживание
- Управление командами
- Разработка
- Международная торговля
- Корпоративная ответственность
- Социальные сети и общество
- Управление серверами
- Индустрия компьютерных игр
- Политика и климат
- Онлайн-игры
- Медицинская отрасль
- Искусственный интеллект и технологии
- Религия и мораль
- Путешествия
- Социальные сети и информация
- Технологии и медиа
- Технологии и свобода
- Электронная коммерция
- Бизнес и управление
- Психическое здоровье и технологии
- Технологии и устойчивое развитие
- Технологии и социальные сети
- Профессии
- Экономика и промышленность
- Технологии и трудоустройство
- Иммиграционная политика
- Продуктивность и фокус
- Технологии и робототехника
- Свобода слова
- Психология и власть
- Социальные сети и онлайн-платформы
- Технологии и Права Человека
- СМИ и журналистика
- Окружающая среда и здоровье
- Технологии и сервисы
- Индустрия игр
- Программирование и ИИ
- Медиа и пропаганда
- Социальная сфера
- Социальные сети и общественное мнение
- Поп-культура
- Сервисы потокового вещания
- Рынок развлечений
- Социальные медиа и политика
- Технологии и информация
- Медиа и развлечения
- Квантовая криптография
- Искусственный интеллект в индустрии развлечений
- Технологии и коммуникация
- Индустрия программирования
- Финансовая безопасность
- Международные отношения
- Бизнес и лидерство
- Технологические новости и аналитика
- Программное обеспечение и технологии
- Предпринимательство и малый бизнес
- Политика и общественный контроль
- Здравоохранение и политика
- Управление персоналом и эффективность разработки
- Технологии и ИТ‑управление
- Свобода слова и дезинформация
- Веб-дизайн и разработка
- Веб‑разработка и карьера
- Культура и общество
- Цифровые права и свобода слова
- Безопасность и искусственный интеллект
- Технологии и искусство
- Мобильные приложения
- Продуктивность
- Космические технологии и безопасность
- Технологические тренды и экономика
- Безопасность и конфиденциальность
- Продуктивность и личная эффективность
- Веб‑скрейпинг и автоматизация
- Политика и социальные сети
- Политика и безопасность
- Медиа и информационное пространство
- Медицина и Психология
- Интернет‑культура и медиа
- Технологии и разработка
- Сociety
- Развитие интеллекта и профессиональные навыки
- Linux, программирование