

Когда робот демонстрирует человеческое восстановление и безопасное поведение
4 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 предварительные
3 Transic: передача политики с рисованием в реальность путем обучения на онлайн-коррекции и 3.1 базовые политики обучения в моделировании с RL
3.2 ОБУЧЕНИЯ ОТРИЦИЯ ПОЛИТИКИ ОТНОВЛЕНИЯ НАУКЦИИ
3.3 Интегрированная структура развертывания и 3,4 Подробности реализации
4 эксперименты
4.1 Настройки эксперимента
4.2 Количественное сравнение по четырем задачам сборки
4.3 Эффективность в решении различных разрывов с рисунком (Q4)
4.4 Масштабируемость с человеческими усилиями (Q5) и 4,5 интригующих свойств и возникающего поведения (Q6)
5 Связанная работа
6 Заключение и ограничения, подтверждения и ссылки
А. Подробная информация об обучении симуляции
Б. Реальные детали обучения в реальном мире
C. Настройки эксперимента и детали оценки
D. Дополнительные результаты эксперимента
4.4 Масштабируемость с человеческими усилиями (Q5)
Масштабирование с человеческими усилиями-это желаемое свойство для методов обучения роботов человека в петле [70]. Мы показываем, что Transic имеет лучшую масштабируемость данных человека, чем лучший базовый IWR на рис. 6а и таблице A.XI. Если мы увеличим размер набора данных коррекции с 25% до 75% от полного размера набора данных, Transic достигнет относительного улучшения 42% в среднем уровне успеха. Напротив, IWR достигает только 23% относительного улучшения. Кроме того, для задач, отличных от вставки, IWR Performance Plateace на ранней стадии и даже начинает уменьшаться по мере того, как становится доступным больше человеческих данных. Мы предполагаем, что IWR страдает от катастрофического забывания и изо всех сил пытается правильно моделировать поведенческие способы людей и обученных роботов. С другой стороны, Transic обходит эти проблемы, изучая закрытую остаточную политику только от коррекции человека.
4.5 Интригующие свойства и возникающее поведение (Q6)
Наконец, мы рассмотрим дальнейшее транзик и обсуждаем несколько возникающих возможностей.
Обобщение на невидимые объектыМы показываем, что робот, обученный транспортом, может нулевой выстрел в новые объекты из новой категории. Как показано на рис. 6B, транзик может достичь средней скорости успеха 75%, когда нулевой выстрел оценивается при сборке лампы. Тем не менее, IWR может добиться успеха только один раз каждые три попытки. Эти данные свидетельствуют о том, что Transic не переполняется определенным объектом, вместо этого он изучил многократные навыки для обобщения объектов на уровне категории.
Влияние различных механизмов стробированияМы вводим ученую закрытую остаточную политику в гл. 3.3 где механизм стробирования контролирует при применении остаточных действий. Чтобы оценить качество изученного стробирования, мы сравниваем его производительность с реальным человеческим оператором, выполняющим стробирование. Результаты показаны в таблице 2. Очевидно, что ученый механизм стробирования вызывает лишь незначительные падения производительности по сравнению с стробированием человека. Это говорит о том, что транзик может надежно работать в полностью автономной настройке после изучения механизма стробирования.
Политическая надежностьМы исследуем надежность политики в отношении 1) облачных наблюдений точек с низким качеством, удаляя две камеры и 2) неоптимальные данные коррекции с инъекцией шума. См. Приложение Sec. C.4 для подробных экспериментальных настройков. Результаты показаны в таблице 2. Мы подчеркиваем, что транзик является устойчивым к входам облака частичных точек, вызванных уменьшенным числом камер. Мы приписываем это с тяжелым облаком, используемой во время обучения. Фишман и соавт. [91] эхо нашим обнаружением того, что политика, обученная с нисходящими входами в облако синтетических точек, может
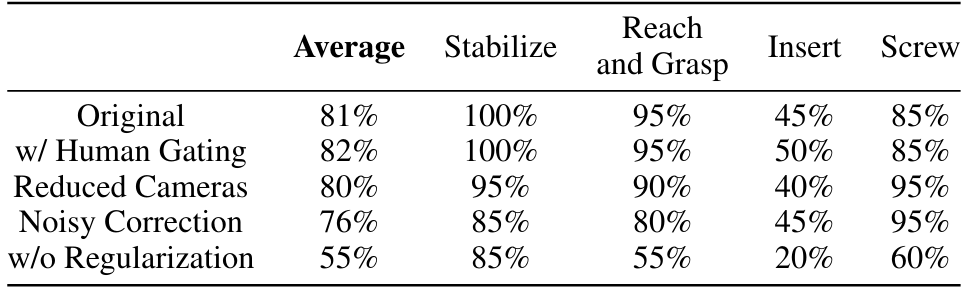
ОБЩИЙ ОБЩЕСТВЕННЫЕ ВСЕГО НАБОТА, ПОЛУЧЕННЫЕ В реальном мире без необходимости завершения формы. Между тем, когда данные по коррекции, используемые для изучения остаточных политик, являются неоптимальными, транзику показывает только относительное снижение на 6% в среднем уровне успеха. Мы связываем это с преимуществом нашего интегрированного развертывания - когда остаточная политика ведет себя неоптимально, базовая политика все еще может компенсировать ошибку в последующих шагах.
Важность регуляризации энкодера точечных облаковЧтобы изучить последовательные визуальные особенности между симуляцией и реальностью, мы предлагаем упорядочить энкодер облака точек на стадии дистилляции, как в уравнении. 1. Как показано в таблице 2, производительность значительно снижается без такой регуляризации, особенно для задач, которые требуют мелкозернистых визуальных особенностей. Без этого политики моделирования будут переоценены в синтетические наблюдения за точками облака и, следовательно, не идеальны для переноса SIM-креал.
Качественный анализ и возникающее поведениеСначала мы рассмотрим распределение собранного набора данных по коррекции человека. Во время сбора данных человеком в петле вероятность вмешательства и исправления достаточно низкая (PCorrection ≈ 0,20). Это согласуется с нашей интуицией, что с хорошей базовой политикой вмешательства не являются необходимыми в течение большей части времени. Тем не менее, они становятся критическими, когда робот имеет тенденцию вести себя ненормально из-за безделенных пробелов с рисованием с рисованием. Более того, как показано на рис. A.8, вмешательства происходят в разное время по задачам. Этот факт делает методы, основанные на эвристике [92] для решения, когда вмешиваться трудным, и еще больше требует нашей научной остаточной политики.
Удивительно, но Transic показывает несколько репрезентативных поведений, которые напоминают людей. Например, они включают в себя восстановление ошибок, откровение, действие по безопасности и профилактику сбоев, как показано на рис. 7.
Решение задач манипуляции с длинными горыНаконец, мы демонстрируем, что успешная передача индивидуальных навыков с рисунком может быть эффективно прикована вместе, чтобы обеспечить манипуляции с богатыми контактами с длинными гостями (рис. 8). См. Видео на Transic-robot.github.io для робота, собирающего квадратный стол и лампу с использованием транспорта.
Авторы:
(1) Юнфан Цзян, факультет информатики;
(2) Чен Ван, кафедра компьютерных наук;
(3) Руохан Чжан, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(4) Цзяджун Ву, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(5) Ли Фей-Фей, Департамент информатики и Институт ИИ, ориентированного на человека (HAI).
Эта статья есть
Оригинал