
Что происходит, когда ваша подсказка слишком неясна?
10 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
H T2I Модели: оценка
Мы предоставляем дополнительные количественные и качественные результаты в этом разделе для моделей T2I, оцениваемых на«Пусть это виляет!”Набор данных.
H.1 Количественные результаты по поиску
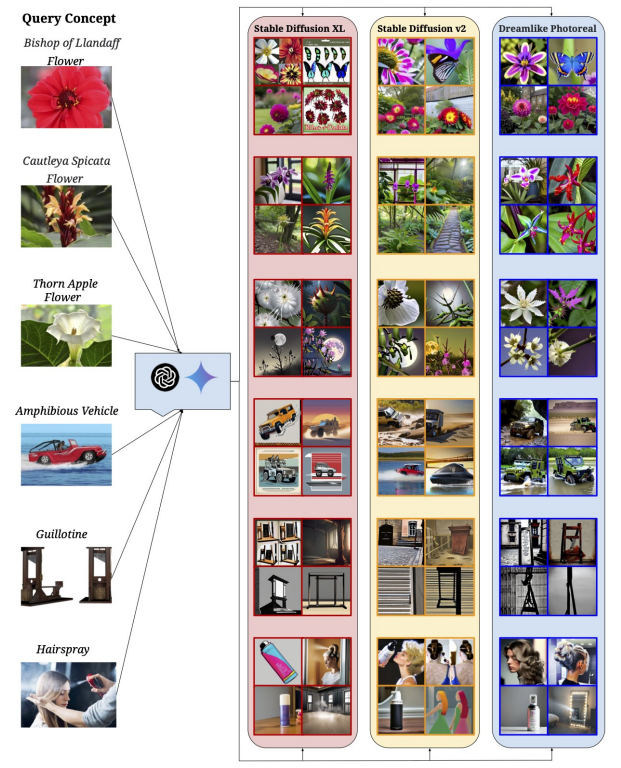
Мы предоставляем дальнейший анализ о том, как современные модели T2I работают на длиннохвостых концепциях, включающих«Пусть это виляет!»набор данных. Как подробно описано в гл. 6, мы генерируем 4 изображения для каждой концепции, используя стабильную диффузию XL [89], стабильную диффузию V2 [96] и сказочный фотореал [1].
Стратегия подсказки.Используемая стратегия подсказки (роль системы), адаптирована из Shahmohammadi et al. [105], было:

С помощью этого пула сгенерированных изображений мы проводим контролируемый эксперимент на длиннохвостых концепциях, используя извлечение ближайшего соседа в качестве показателя оценки, запрашивая сгенерированное изображение и получая результаты Top-K из галереи изображений, взятых из«Пусть это виляет!»набор данных. Общий трубопровод заключается в следующем:
Настраивать. МыОпределите запрос и галерею для концепций головы и хвоста. Для концепций хвоста мы выбираем 25 концепций с самой низкой частотой от«Пусть это виляет!»набор данных. Для концепций головы мы выбираем 25 наиболее частых концепций для сравнения. Мы используем ту же стратегию подсказок с выбранными 25 концепциями во всех 3 моделях T2I. Чтобы создать набор галереи, мы случайным образом выбираем 100 изображений для каждой из этих концепций. Мы используем DINOV2 [85] VIT-S/14 в качестве экстрактора функции.
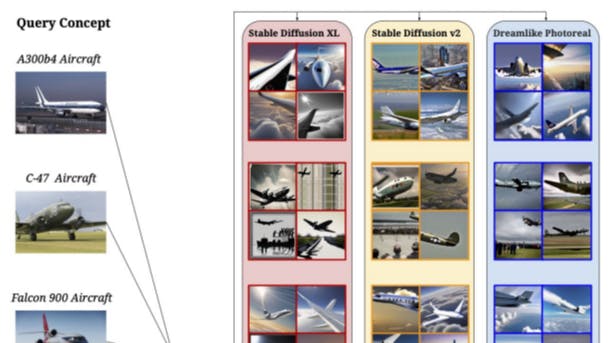
РезультатыПолем В таблице 5 мы предоставляем результаты совокупной характеристики соответствия (CMC@K) для всех 3 моделей T2I, используемых в нашем эксперименте. CMC@K был выбран, поскольку мы заинтересованы в измерении дельты между концепциями головы и хвоста для успешных поисков в топ-K, полученных реальными изображениями для данного сгенерированного изображения. Мы наблюдаем большой разрыв в производительности междуГоловаиХвостКонцепции, обеспечивая количественную оценку производительности генерации моделей T2I.
H.2 Качественные результаты
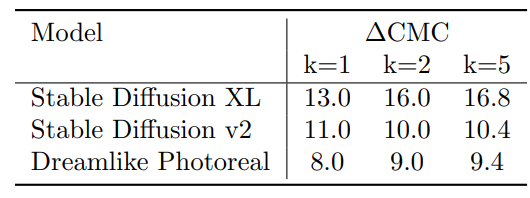
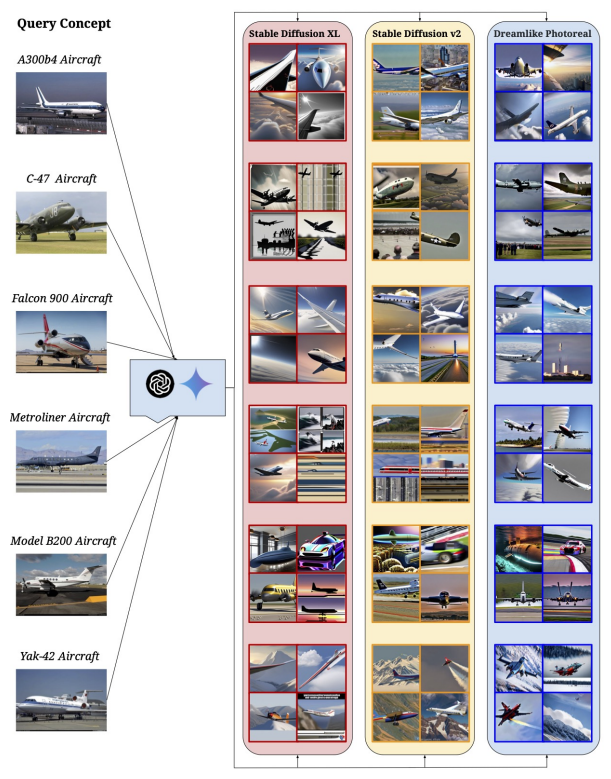
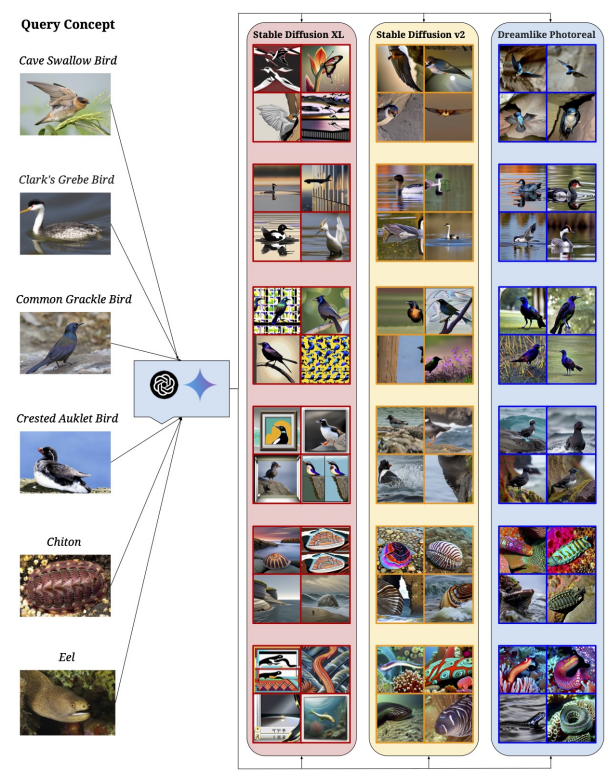
На рис. 7 основного текста мы даем первоначальное представление о качественной производительности моделей T2I на«Пусть это виляет!»концепции. Для простоты понимания и сравнения мы разделяем концепции на 4 кластера: самолет (рис. 23), активность (рис. 24), животное (рис. 25) и другие (рис. 26).
РезультатыПолем На рис. 23 показаны модели T2I, испытывающие трудности с представлением самолета в полной форме в большинстве случаев в дополнение к искажению конкретной модели на сгенерированных изображениях. На рис. 24 демонстрируется сложность моделей T2I, с которыми сталкиваются модели при представлении действий или действий из подсказок. Рис. 25 иллюстрирует ту же неспособность моделей T2I точно представлять виды животных. Наконец, оставшаяся часть набора запросов показана на рис. 26 и включает в себя неспособность классифицировать и впоследствии генерировать определенные виды цветов и объектов.

Я классификации результаты:Пусть это виляет!
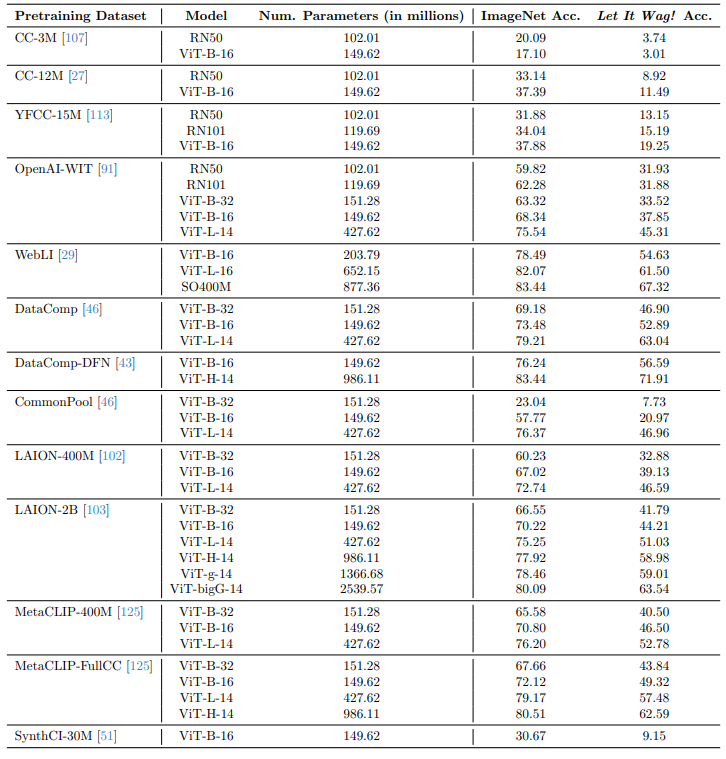
Здесь мы представляем необработанные значения точности 40 протестированных моделей на обоихПусть это виляет!и ImageNet в табле. 6. Для справки, мы также сообщаем о наборах данных, на которые были обучены эти модели, и количество параметров для каждой модели. Мы видим четкие падения в производительности по сравнению с ImageNet, по размерам моделей, архитектурам и наборам данных предварительного подготовки.
Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал
Recent Post
-
Когда ИИ становится посредником в семейных спорах о наследстве
20 августа 2025 г. -
Конец общей аннотации в здравоохранении: визуализация сердца показывает, почему
20 августа 2025 г. -
5 Рабочие процессы агента AI для повторяемого успеха (включен код)
20 августа 2025 г. -
Почему OCR борется со страницами с несколькими колоннами
20 августа 2025 г. -
Все, что я узнал (трудный путь) как начинающий основатель AI SaaS
20 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Астрофизика
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика
- Развлечения
- ИТ и автоматизация
- Криптовалюты и блокчейн
- История и идеология
- Медицина и политика
- Личная жизнь миллиардеров
- Образование и Политика
- Туризм и отдых
- Психология и искусственный интеллект
- Удаленная работа и производительность
- Выживание
- Управление командами
- Разработка
- Международная торговля
- Корпоративная ответственность
- Социальные сети и общество
- Управление серверами
- Индустрия компьютерных игр
- Политика и климат
- Онлайн-игры
- Медицинская отрасль
- Искусственный интеллект и технологии
- Религия и мораль
- Путешествия
- Социальные сети и информация
- Технологии и медиа
- Технологии и свобода
- Электронная коммерция
- Бизнес и управление
- Психическое здоровье и технологии
- Технологии и устойчивое развитие
- Технологии и социальные сети
- Профессии
- Экономика и промышленность
- Технологии и трудоустройство
- Иммиграционная политика
- Продуктивность и фокус
- Технологии и робототехника
- Свобода слова
- Психология и власть
- Социальные сети и онлайн-платформы
- Технологии и Права Человека
- СМИ и журналистика
- Окружающая среда и здоровье
- Технологии и сервисы
- Индустрия игр
- Программирование и ИИ
- Медиа и пропаганда
- Социальная сфера
- Социальные сети и общественное мнение
- Поп-культура
- Сервисы потокового вещания
- Рынок развлечений
- Социальные медиа и политика
- Технологии и информация
- Медиа и развлечения
- Квантовая криптография
- Искусственный интеллект в индустрии развлечений
- Технологии и коммуникация
- Индустрия программирования
- Финансовая безопасность
- Международные отношения
- Бизнес и лидерство
- Технологические новости и аналитика
- Программное обеспечение и технологии
- Предпринимательство и малый бизнес
- Политика и общественный контроль
- Здравоохранение и политика
- Управление персоналом и эффективность разработки
- Технологии и ИТ‑управление
- Свобода слова и дезинформация
- Веб-дизайн и разработка
- Веб‑разработка и карьера