
Что показывают 34 модели на языке зрения о мультимодальном обобщении
9 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
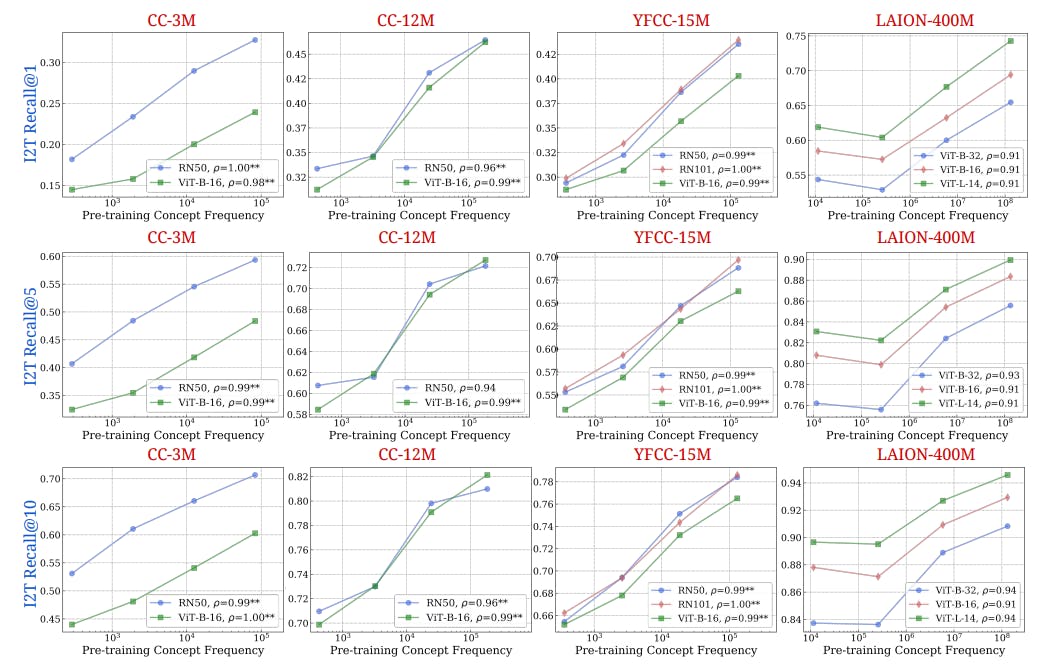
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
8 выводов и открытых проблем
В этой работе мы углубились в пять наборов данных из 34 мультимодальных моделей языка зрений, анализируя распределение и состав концепций внутри, генерируя более 300 ГБ артефактов данных, которые мы публично выпускаем. Наши результаты показывают, что в разных концепциях значительные улучшения в производительности с нулевым выстрелом требуют экспоненциально большего количества данных, после того, как логарифмическая линейная тенденция масштабирования. Этот шаблон сохраняется, несмотря на контролирование сходства между предварительной подготовкой и нисходящими наборами данных или даже при тестировании моделей на полностью синтетических распределениях данных. Кроме того, все протестированные модели последовательно не работали на«Пусть это виляет!»Набор данных, который мы систематически построили из наших выводов для проверки на длинные концепции. Это подчеркивает критическую переоценку того, что влечет за собой обобщение «нулевого выстрела» для мультимодальных моделей, подчеркивая ограничения в их текущих возможностях обобщения. Мы выделяем несколько захватывающих направлений для будущих исследований, чтобы преодолеть эти пробелы или получить дальнейшее понимание:
Понимание смещений изображения.Можно исследовать происхождение смещения между изображениями и текстами, такими как ограничения точного сопоставления для идентификации концепции в подписи, неточности от модели тега RAM ++ или подписи, которые либо слишком шумные, либо неактуальные.
Исследование композиционного обобщения.Термин «обобщение с нулевым выстрелом» часто относится к способности моделей к композиционному обобщению, что означает способность понимать новые комбинации концепций, которые ранее не сталкивались. Это отличается от традиционного обучения с нулевым выстрелом и представляет интригующую, но неразрешенную проблему: анализ композиционного обобщения с точки зрения ориентированной на данные.
Методы преодоления разрыва в обобщении.Решение проблем, связанных с распределением длинного хвоста, включает в себя улучшение обобщения модели для преодоления ограниченного улучшения по сравнению с предварительной подготовкой, которую мы обнаружили в нашем исследовании. Механизмы извлечения могут компенсировать недостатки, связанные с вооруженными обобщениями, обеспечивая жизнеспособный путь к смягчению последствий распределения данных с длиннохвостыми предварительными данными.
Благодарности
Авторы хотели бы поблагодарить (в алфавитном порядке): Джонатан Робертс, Карстен Рот, Мехди Черти, Прасанна Майлваханан, Шьямгопал Картик и Тао Нгуен для полезных отзывов и обеспечения доступа к различным ресурсам на протяжении всего проекта. YS хотел бы поблагодарить Николаса Карлини, Дафны Ипполито, Кэтрин Ли, Мэтью Джагельски и Милада Насра. AP финансируется Meta AI Grant № DFR05540. Vu и YS благодарят Международной исследовательской школе Max Planck за интеллектуальные системы (IMPS-IS). VU также благодарит Европейскую лабораторию за обучение и интеллектуальные системы (ELLIS) PhD Program за поддержку. PT благодарит Королевскую инженерную академию за поддержку. AB признает награду Amazon Research. SA поддерживается грантом Newton Trust. MB признает финансовую поддержку через Фонд открытой филантропии, финансируемый Фондом Good Ventures. Эта работа была поддержана Немецким исследовательским фондом (DFG): SFB 1233, надежное видение: принципы вывода и нейронные механизмы, TP4, Номер проекта: 276693517 и грант UKRI: Turing AI Fellowship EP/W002981/1. MB является членом кластера машинного обучения превосходства, финансируемого Deutsche Forschungsgemeinschaft (DFG, Германский исследовательский фонд) в рамках стратегии превосходства Германии - Excure 2064/1 - № 390727645 проекта 390727645.
Ссылки
[1] Поиск лексики со стабильной диффузией v1.5 (1b). https://lexica.art/?q=stable+diffusion+1.5. 5, 16
[2] Сказочная диффузия v1.0. https://huggingface.co/dreamlize-art/dreamlike-diffusion-1.0 ,. 5
[3] Сказочный фотореал v2.0. https://huggingface.co/dreamliky-art/dreamlike-photoreal-2.0 ,. 5, 10
[4] OpenJourney v1. https://huggingface.co/prompthero/openjourney ,. 5
[5] OpenJourney v2. https://huggingface.co/prompthero/openjourney-v4 ,. 5
[6] Диффузия красного смещения. https://huggingface.co/nitrosocke/redshift-diffusion. 5
[7] Диффузионная модель Vintedois (22H) V0.1. https://huggingface.co/22h/vintedois-diffusion-v0-1. 5
[8] Человек (Q5). https://www.wikidata.org/wiki/q5. 5
[9] DeepFloyd if. https://github.com/deep-floyd/if, 2023. 5
[10] Amro Abbas, Kushal Tirumala, D´aniel Simig, Surya Ganguli и Ari S Morcos. SEMDEDUP: эффективное обучение данных в веб-масштабе через семантическую дедупликацию. Достижения в области систем обработки нейронной информации, 2023. 7, 11
[11] Амро Аббас, Евгения Русак, Кушал Тирумала, Виланд Брендель, Камалика Чаудхури и Ари Соркой. Эффективная обрезка наборов данных по веб-масштабам на основе сложности концептуальных кластеров. В Международной конференции по обучению представлений (ICLR), 2024. 2, 11
[12] Джош Ачиам, Стивен Адлер, Сандхини Агарвал, Лама Ахмад, Ильге Аккайя, Флоренсия Леони Алеман, Диого Алмейда, Янко Алтеншмидт, Сэм Альтман, Шьямал Анадкат и др. GPT-4 Технический отчет. Arxiv Preprint arxiv: 2303.08774, 2023. 10
[13] Экин Акирек, Толга Болукбаси, Фредерик Лю, Бинбин Сионг, Ян Тенни, Джейкоб Андреас и Кельвин Гу. Отслеживание знаний в языковых моделях обратно к данным обучения. В результатах Ассоциации вычислительной лингвистики: EMNLP, 2022. 11
[14] Марко Беллагенте, Мануэль Брэк, Ханна Теуфель, Феликс Фридрих, Бьжорн Дейзрот, Константин Эйхенберг, Эндрю М. Дай, Роберт Балдок, Сурадеп Нанда, Коэн Оостермайер и др. Multifusion: слияние предварительно обученных моделей для многоязычной многомодальной генерации изображений. В достижениях в системах обработки нейронной информации (Neurips), 2023. 5
[15] Томас Берг, Джионгсин Лю, Сейунг Ву Ли, Мишель Л. Александр, Дэвид В. Джейкобс и Питер Н. Белхуумер. Birdsnap: крупномасштабная мелкозернистая визуальная категоризация птиц. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2014. 4
[16] Ян Берлот-Аттвел, Майкл Каррелл, Кумар Кришна Агравал, Яш Шарма и Наоми Сафра. Разнообразие атрибутов определяет системный разрыв в VQA. Arxiv Preprint arxiv: 2311.08695, 2023. 11
[17] Джеймс Беткер, Габриэль Го, Ли Цзин, Тим Брукс, Цзянфенг Ванг, Линджи Ли, Лонг Оуян, Хунтанг Чжуан, Джойс Ли, Юфэй Го и др. Улучшение генерации изображений с лучшими подписями. В информатике, 2023. 1, 11
[18] Абеба Бирхане и Винай Удай Прабху. Большие наборы данных изображения: пиррическая победа для компьютерного зрения? В 2021 году IEEE Winter Conference по приложениям Computer Vision (WACV), 2021. 11
[19] Abeba Birhane, Sanghyun Han, Vishnu Boddeti, Sasha Luccioni, et al. В логово Лайон: расследование ненависти в мультимодальных наборах данных. Достижения в системах обработки нейронной информации, 2023. 11
[20] Лукас Боссард, Маттиу Гильямин и Люк Ван Гул. Food-101-мчин-дискриминационные компоненты со случайными лесами. В Европейской конференции по компьютерному видению (ECCV), 2014. 4
[21] Макс Ф. Бург, Флориан Венцель, Доминик Зитлоу, Макс Хорн, Усама Маканси, Франческо Локателло и Крис Рассел. Понимание изображения превосходит диффузионные модели по увеличению данных. Транзакции по исследованиям машинного обучения (TMLR), 2023. 11
[22] Николас Карлини, Дафна Ипполито, Мэтью Ягельски, Кэтрин Ли, Флориан Трамер и Чиюан Чжан. Количественная оценка запоминания в моделях нейронного языка. В Одиннадцатой Международной конференции по обучению, 2023. 5
[23] Николас Карлини, Джейми Хейс, Милад Наср, Мэтью Ягельски, Викаш Сехваг, Флориан Трамер, Борха Балл, Дафна Ипполито и Эрик Уоллес. Извлечение учебных данных из диффузионных моделей. На 32 -м симпозиуме USENIX Security (USENIX Security 23), стр. 5253–5270, 2023. 5
[24] Сантьяго Кастро и Фабиан Каба Хейлброн. FitClip: уточнение крупномасштабных моделей с образованием изображений для задач понимания с нулевым выстрелом. Британская конференция машинного видения (BMVC), 2022. 1
[25] Стефани Чан, Адам Санторо, Эндрю Лампинен, Джейн Ван, Аадита Сингх, Пьер Ричемонд, Джеймс Макклелланд и Феликс Хилл. Свойства распределения данных стимулируют возникающее встроенное обучение в трансформаторах. Конференция по системам обработки нейронной информации (Neurips), 2022. 8
[26] Кент К Чанг, Маккензи Крамер, Сандип Сони и Дэвид Бамман. Говорите, память: археология книг, известных Chatgpt/GPT-4. Arxiv Preprint arxiv: 2305.00118, 2023. 11
[27] Soravit Changpinyo, Piyush Sharma, Nan Ding и Radu Soricut. Концептуальная 12m: подтолкнуть предварительное обучение в виде веб-масштаба для распознавания визуальных концепций длинного хвоста. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2021. 2, 4, 22
[28] Лин Чен, Джисонг Ли, Сяайи Донг, Пан Чжан, Конгуи Х. Х., Цзяки Ванг, Фенг Чжао и Дахуа Лин. ShareGPT4V: улучшение крупных мультимодальных моделей с лучшими подписями. Arxiv Preprint arxiv: 2311.12793, 2023. 11
[29] Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. Пали: совместно масштабируемая многоязычная модель языка. Arxiv Preprint arxiv: 2209.06794, 2022. 2, 22
[30] Jaemin Cho, Abhay Zala и Mohit Bansal. Dall-eval: исследование навыков рассуждений и социальных предубеждений моделей генерации текста до изображения. В материалах Международной конференции IEEE/CVF по компьютерному видению, страницы 3043–3054, 2023. 5
[31] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed и Andrea Vedaldi. Описывая текстуры в дикой природе. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2014. 4
[32] Колин Конвелл и Томер Уллман. Тестирование реляционного понимания в генерации изображений, управляемого текстами. Arxiv Preprint arxiv: 2208.00005, 2022. 5
[33] DailyDalle2023. Instagram Account Daily Dall-E. https://www.instagram.com/dailydall.e/, 2024. Доступ: 2024-04-03. 4
[34] Борис Дейма, Сурадж Патил, Педро Куэнда, Халид Сайфулла, Таниш Абрахам, Фук Ле Ххак, Люк Мелас и Ритобрата Гош. Dall · E Mini, 7 2021. URL https://github.com/borisdayma/dalle-mini. 5
[35] Цзя Дэн, Вэй Донг, Ричард Сохер, Ли-Цзия Ли, Кай Ли и Ли Фей-Феи. ImageNet: крупномасштабная иерархическая база данных изображений. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2009. 3, 4
[36] Алексей Досовицкий, Лукас Бейер, Александр Колесников, Дирк Вайссенборн, Сяохуа Чжай, Томас Унтертинер, Мостафа Дехгани, Матиас Миндерер, Георг Хейголд, Сильвен Гелли и др. Изображение стоит 16x16 слов: трансформаторы для распознавания изображений в масштабе. Arxiv Preprint arxiv: 2010.11929, 2020. 4
[37] Лин Дю, Энтони Т.С. Хо и Ранмин Конг. Восприятие хеширования для аутентификации изображения: опрос. Обработка сигнала: Image Communication, 2020. 11
[38] Янаи Элазар, Нора Касснер, Шаули Равфогель, Амир Федер, Абхилаша Равичандер, Мариус Мосбах, Йонатан Белинков, Хинрих Шуцце и Йоав Голдберг. Измерение причинно -следственных эффектов статистики данных на языковую модель -фактические предложения. Arxiv Preprint arxiv: 2207.14251, 2022. 11
[39] Янай Элазар, Акшита Бхагия, Ян Магнуссон, Абхилаша Равичандер, Дастин Швенк, Алан Сур, Пит Уолш, Дирк Гроневельд, Лука Слайняни, Самиер Сингх и др. Что в моих больших данных? Arxiv Preprint arxiv: 2310.20707, 2023. 11
[40] Рахим Энтезари, Митчелл Вортсман, Ольга Саук, М. Моиин Шариания, Хани Седги и Людвиг Шмидт. Роль данных перед обучением в обучении передачи. Arxiv Preprint arxiv: 2302.13602, 2023. 11
[41] Патрик Эссер, Сумит Кулал, Андреас Блаттманн, Рахим Энтезари, Джонас Мюллер, Гарри Саини, Ям Леви, Доминик Лоренц, Аксель Сауэр, Фредерик Бозель, et al. Масштабирование выпрямленных трансформаторов потока для синтеза изображения с высоким разрешением. Arxiv Preprint arxiv: 2403.03206, 2024. 1
[42] Алекс Фанг, Габриэль Илхарко, Митчелл Вортсман, Юхао Ван, Вайшаал Шанкар, Ахал Дейв и Людвиг Шмидт. Данные определяют устойчивость к распределению в противоположном языковом изображении перед тренировкой (CLIP). Arxiv Preprint arxiv: 2205.01397, 2022. 2, 11
[43] Алекс Фанг, Альбин Мадаппалли Хосе, Амит Джайн, Людвиг Шмидт, Александр Тошев и Вайшаал Шанкар. Сети фильтрации данных, 2023. 22
[44] Ли Фей-Фей, Роб Фергус и Пьетро Перона. Обучение генеративным визуальным моделям из нескольких примеров обучения: инкрементный байесовский подход, протестированный на 101 категориях объектов. В конференции по компьютерному видению и распознаванию схем (CVPR-W), 2004. 4
[45] Джерри А. Фодор и Зенон В. Пилишин. Консингизм и когнитивная архитектура: критический анализ. Познание, 28 (1-2): 3–71, 1988. 11
[46] Самир Ицхак Гадре, Габриэль Илхарко, Алекс Фанг, Джонатан Хаясе, Джорджиос Смирнис, Тао Нгуен, Райан Мартен, Митчелл Вортсман, Дхруба Гош, Цзею Чжан, et al. DATACOMP: В поисках следующего поколения мультимодальных наборов данных. Arxiv Preprint arxiv: 2304.14108, 2023. 1, 2, 11, 22
[47] Ноа Гарсия, Юсуке Хирота, Янкун Ву и Юта Накашима. Наборы данных о необращенных изображениях: пролить свет на демографический смещение. В материалах конференции IEEE/CVF по компьютерному зрению и распознаванию образцов, страницы 6957–6966, 2023. 11
[48] Шашанк Гоэль, Хритик Бансал, Сумит Бхатия, Райан Росси, Вишва Винай и Адитья Гровер. Cyclip: Циклическое контрастное языковое изображение предварительно предварительно. Arxiv Preprint arxiv: 2205.14459, 2022. 1, 4
[49] Грегори Гриффин, Алекс Холуб и Пьетро Перона. Caltech-256 Набор данных объектов. 2007. 4
[50] Дилан Джаспер Хэдфилд-Менелл. Основная проблема выравнивания основного агента в искусственном интеллекте. Калифорнийский университет, Беркли, 2021 год. 5
[51] Хасан Абед Аль Кадер Хаммуд, Хани Итани, Фабио Пиццати, Филип Торр, Адель Биби и Бернард Ганем. SynthClip: Готовы ли мы к полному синтетическому обучению клипам? Arxiv Preprint arxiv: 2402.01832, 2024. 1, 2, 8, 22
[52] Яру Хао, Зуен Чи, Ли Донг и Фуру Вэй. Оптимизация подсказок для генерации текста до изображения. Достижения в области систем обработки нейронной информации, 36, 2024. 5, 10
[53] Kaiming HE, Siangyu Zhang, Shaoqing Ren и Jian Sun. Глубокое остаточное обучение для распознавания изображений. В материалах конференции IEEE по компьютерному зрению и распознаванию образцов, страницы 770–778, 2016. 4
[54] Ruifei He, Shuyang Sun, Xin Yu, Chuhui Xue, Wenqing Zhang, Philip Torr, Song Bai и Xiaojuan Qi. Готовы ли синтетические данные из генеративных моделей для распознавания изображений? Arxiv Preprint arxiv: 2210.07574, 2022. 11
[55] Патрик Хелбер, Бенджамин Бишке, Андреас Денгель и Дамиан Борт. Eurosat: новый набор данных и тест глубокого обучения для классификации землепользования и землевладельца. IEEE Journal по выбранным темам в прикладных наблюдениях Земли и дистанционном зондировании, 12 (7): 2217–2226, 2019. 4
[56] Джек Хессель, Ари Хольцман, Максвелл Форбс, Ронан Ле Брас и Йецзин Чой. CLIPSCORE: беззаботная оценка показателя для подписания изображения. Arxiv Preprint arxiv: 2104.08718, 2021. 12
[57] Джек Хессель, Ари Хольцман, Максвелл Форбс, Ронан Ле Брас и Йецзин Чой. CLIPSCORE: бесстыдный показатель оценки для подписания изображения, 2022. 5
[58] Мэтью Хоннибал и Инес Монтани. SPACY 2: Понимание естественного языка с помощью Bloom Entricdings, сверточных нейронных сетей и постепенного анализа. Появиться, 7 (1): 411–420, 2017. 3
[59] Синью Хуанг, И-д-джи Хуанг, Юкай Чжан, Вейвей Тиан, Руи Фэн, Юэджи Чжан, Янчун Се, Якян Ли и Лей Чжан. Открытое изображение с помощью многоцелевого текстового надзора. arxiv E-Prints, страницы Arxiv-2310, 2023. 3, 12
[60] Dieuwke Hupkes, Verna Dankers, Mathijs Mul и Elia Bruni. Композиция разлагается: как обобщаются нейронные сети? Журнал исследований искусственного интеллекта, 67: 757–795, 2020. 11
[61] Габриэль Илхарко, Митчелл Вортсман, Росс Уайтман, Кейд Гордон, Николас Карлини, Рохан Таори, Ахал Дейв, Вайшаал Шанкар, Хонгсеок Намконг, Джон Миллер, Ханнанех Хаджирзи, Али Фардади и Лудвиг Шмитт. OpenClip, июль 2021 года. URL https://doi.org/10.5281/zenodo.5143773. Если вы используете это программное обеспечение, укажите его, как ниже. 4
[62] Нихил Кандпал, Хайканг Денг, Адам Робертс, Эрик Уоллес и Колин Раффель. Большие языковые модели борются за изучение знаний с длинными хвостами. На Международной конференции по машинному обучению (ICML), страницы 15696–15707. PMLR, 2023. 2, 6, 7, 11
[63] Мингек Кан, Джун-Янь Чжу, Ричард Чжан, парк Ясик, Эли Шехтман, Сильвен Париж и Парк Тэснг. Масштабирование Gans для синтеза текста до изображения. В конференции по компьютерному видению и распознаванию шаблонов (CVPR), 2023. 5
[64] Wonjae Kim, Bokyung Son и Ildoo Kim. Vilt: Vision и Language Transformer без свертки или регионального надзора. На Международной конференции по машинному обучению (ICML), 2021. 1
[65] Киммо Коскенними. Общая вычислительная модель для распознавания и производства слова. В 10 -й Международной конференции по вычислительной лингвистике и 22 -м ежегодному собранию Ассоциации вычислительной лингвистики. Ассоциация вычислительной лингвистики, 1984. 3
[66] Джонатан Краузе, Майкл Старк, Цзя Денг и Ли Фей-Фей. 3D-представления объекта для мелкозернистой категоризации. В Международной конференции по семинару по компьютерному видению (ICCV-W), 2013. 4
[67] Алекс Крижевский, Джеффри Хинтон и др. Изучение нескольких слоев функций из крошечных изображений. 2009. 4
[68] Чжэнфенг Лай, Хаотиан Чжан, Вёоо Ву, Хапинг Бай, Алексеи Тимофейв, Сяньжу Дю, Чжэ Ган, Джиулонг Шан, Чен-Ни Чуа, Иньфей Ян и др. От дефицита до эффективности: улучшение обучения клипам с помощью обогащенных визуальными подписями. Arxiv Preprint arxiv: 2310.07699, 2023. 11
[69] Кристоф Х Ламперт, Ханнес Никиш и Стефан Хармелинг. Классификация на основе атрибутов для категоризации зрительного объекта с нулевым выстрелом. IEEE Transactions по анализу шаблонов и интеллекта машин, 36 (3): 453–465, 2013. 1
[70] Кэтрин Ли, Дафна Ипполито, Эндрю Нистрем, Чиюан Чжан, Дуглас Эк, Крис Каллисон-Берч и Николас Карлини. Дедуплирование данных обучения делает языковые модели лучше. В материалах 60 -го ежегодного собрания Ассоциации по вычислительной лингвистике (том 1: Долгие документы), стр. 8424–8445, 2022. 5
[71] Тони Ли, Мичихиро Ясунага, Ченлин Менг, Йифан Май, Джун Сун Парк, Агрим Гупта, Юньчхи Чжан, Дипак Нараянан, Ханна Теуфель, Марко Беллагенте и др. Целостная оценка моделей текста до изображения. Достижения в области систем обработки нейронной информации, 36, 2023. 4, 5
[72] Джуннан Ли, Рампрасаат Селвараджу, Ахилеш Готмар, Шафик Йоти, Кайминг Сюн и Стивен Чу Хуг Хой. Выровнять перед предохранителем: видение и языковое представление обучение с дистилляцией импульса. Конференция по системам обработки нейронной информации (Neurips), 2021. 1
[73] Цунг-Йи Лин, Майкл Мэйр, Серж-Достиж, Джеймс Хейс, Пьетро Перона, Дева Раманан, Пиот-Долл и С Лоуренс Зитник. Microsoft Coco: Общие объекты в контексте. В Европейской конференции по компьютерному видению (ECCV), 2014. 4, 5
[74] Шейн Лонгпра, Грегори Яуни, Эмили Рейф, Кэтрин Ли, Адам Робертс, Баррет Зоф, Денни Чжоу, Джейсон Вей, Кевин Робинсон, Дэвид Мимо и др. Руководство по предварительному образованию по данным обучения: измерение последствий возраста данных, охвата домена, качества и токсичности. Arxiv Preprint arxiv: 2305.13169, 2023. 2, 11
[75] Анас Махмуд, Мостафа Эльхауши, Амро Аббас, Ю Ян, Ньюша Ардалани, Хью Кожа и Ари Моркос. SIETH: обрезка набора данных мультимодального данных с использованием моделей подписания изображений. Arxiv Preprint arxiv: 2310.02110, 2023. 4, 8
[76] Pratyush Maini, Sachin Goyal, Zachary C Lipton, J Zico Kolter и Aditi Raghunathan. T-Mars: улучшение визуальных представлений путем обхода обучения текстовой функции. Arxiv Preprint arxiv: 2307.03132, 2023. 4, 8, 11
[77] Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko и Andrea Vedaldi. Мелкозернистая визуальная классификация самолетов. Arxiv Preprint arxiv: 1306.5151, 2013. 4
[78] Даниэла Массисети, Камилла Лонгден, Агниша Столстен, Сэмюэль Уиллс, Мартин Грейсон и Сесили Моррисон. Объяснение различий в производительности Клипа на данных от слепых/низких пользователей. Arxiv Preprint arxiv: 2311.17315, 2023. 11
[79] Прасанна Мэйлваханан, Таддд -Видемер, Евгения Русак, Матиас Бетге и Виланд Брендель. Является ли производительность генерализации Clip в основном из-за сходства с высоким тестированием на поезде? Arxiv Preprint arxiv: 2310.09562, 2023. 1, 2, 7, 11
[80] Матиас Миндерер, Алексей Гритсенко и Нил Хоулсби. Масштабирование обнаружения открытых вокабулярный объект. Достижения в системах обработки нейронной информации, 36, 2023. 12
[81] Норман Му, Александр Кириллов, Дэвид Вагнер и Санинг Си. Слипать: самоосужение соответствует языковому предварительному обучению. Arxiv Preprint arxiv: 2112.12750, 2021. 4
[82] Тао Нгуен, Габриэль Илхарко, Митчелл Вортсман, Сьюонг Огайо и Людвиг Шмидт. Качество не количество: при взаимодействии между дизайном набора данных и надежностью клипа. Arxiv Preprint arxiv: 2208.05516, 2022. 2, 4, 11
[83] Тао Нгуен, Самир Ицхак Гадре, Габриэль Илхарко, Сьюонг Огайо и Людвиг Шмидт. Улучшение мультимодальных наборов данных с подписанием изображения. Достижения в системах обработки нейронной информации, 2023. 2, 4, 11
[84] Мария-Элена Нильсбэк и Эндрю Зиссерман. Автоматизированная классификация цветов по большему количеству классов. В 2008 году Шестая Индийская конференция по компьютерному видению, графике и обработке изображений, страницы 722–729. IEEE, 2008. 4
[85] Максим Окваб, Тимот-Эи Дарсет, Тео Мутаканни, Хуи Во, Марк Сафраниц, Василь Халидов, Пьер Фернандес, Даниэль Хазиза, Франциско Масса, Алаээээээээлдин Эль-Ноуби и др. DINOV2: Обучение надежными визуальными функциями без надзора. Arxiv Preprint arxiv: 2304.07193, 2023. 16
[86] Шубхэм Парашар, Чжикю Лин, Тянь Лю, Сянджу Донг, Янан Ли, Дева Раманан, Джеймс Каверли и Шу Конг. Заброшенные хвосты моделей на языке зрения. CVPR, 2024. 11
[87] Омкар М. Пархи, Андреа Ведальди, Эндрю Зиссерман и CV Джавахар. Кошки и собаки. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2012. 4
[88] Стивен Т -Пиантадоси. Закон о частоте ZIPF на естественном языке: критический обзор и будущие направления. Психономический бюллетень и обзор, 21: 1112–1130, 2014. 8
[89] Дастин Поделл, Сион Инглиш, Кайл Лейси, Андреас Блаттманн, Тим Докхорн, Джонас Мюллер, Джо Пенна и Робин Ромбах. SDXL: улучшение моделей скрытой диффузии для синтеза изображения с высоким разрешением. Arxiv Preprint arxiv: 2307.01952, 2023. 10, 16
[90] Амейя Прабху, Хасан Абед Аль Кадер Хаммуд, Сер-Нам Лим, Бернард Ганем, Филипп Торр и Адель Биби. От категорий до классификатора: только имени постоянное обучение путем изучения Интернета. Arxiv Preprint arxiv: 2311.11293, 2023. 9, 11
[91] Алек Рэдфорд, Чон Вук Ким, Крис Халласи, Адитья Рамеш, Габриэль Го, Сандхини Агарвал, Гириш Састри, Аманда Аскалл, Памела Мишкин, Джек Кларк и др. Обучение переносимым визуальным моделям от надзора естественного языка. В Международной конференции по машинному обучению (ICML), 2021. 1, 2, 4, 10, 11, 22
[92] Vivek Ramanujan, Thao Nguyen, Sewoong OH, Ali Farhadi и Ludwig Schmidt. О связи между разнообразием данных перед тренировкой и точной настройкой. Достижения в области систем обработки нейронной информации, 36, 2024. 11
[93] Адитья Рамеш, Михаил Павлов, Габриэль Го, Скотт Грей, Челси Восс, Алек Рэдфорд, Марк Чен и Илья Сатскевер. Ноль выстрела текста до изображения. На Международной конференции по машинному обучению (ICML), 2021. 1
[94] Ясаман Разеги, Роберт Л Логан IV, Мэтт Гарднер и Самир Сингх. Влияние частоты до подготовки терминов на несколько выстрелов. В результатах Ассоциации вычислительной лингвистики: EMNLP 2022, стр. 840–854, 2022. 2, 6, 7, 11
[95] Ясаман Разеги, Раджа Сехар Редди Мекала, Роберт Л Логан IV, Мэтт Гарднер и Самиер Сингх. Snoopy: онлайн-интерфейс для изучения влияния частот до подготовки терминов на производительность нескольких выстрелов. В материалах конференции 2022 года по эмпирическим методам в обработке естественного языка: демонстрации системы, стр. 389–395, 2022. 11
[96] Робин Ромбач, Андреас Блаттманн, Доминик Лоренц, Патрик Эссер и Бьорн Оммер. Синтез изображения высокого разрешения с скрытыми диффузионными моделями. В конференции по компьютерному видению и распознаванию шаблонов (CVPR), 2022. 1, 5, 10, 16
[97] Ким Сэхун, Чо Сангун, Ким Чихеон, Доюп Ли и Вунхюк Бэк. Mindall-E на концептуальные подписи. https://github.com/kakaobrain/mindall-e, 2021. 5
[98] Читван Сахария, Уильям Чан, Саурабх Саксена, Лала Ли, Джей Ванг, Эмили Л. Дентон, Камир Гасемипур, Рафаэль Гонтиджо Лопес, Бурку Карагол Аян, Тим Салиманс и др. Фотореалистические модели диффузии текста до изображения с глубоким языком пониманием. Достижения в области систем обработки нейронной информации, 35: 36479–36494, 2022. 5
[99] Двир Самуэль, Рами Бен-Ари, Саймон Равив, Нир Даршан и Гал Чечик. Создание изображений редких концепций с использованием предварительных диффузионных моделей. Arxiv Preprint arxiv: 2304.14530, 18, 2023. 11
[100] Шибани Сантуркар, Янн Дюбуа, Рохан Таори, Перси Лян и Татсунори Хашимото. Стоит ли подпись тысячи изображений? Контролируемое исследование для обучения представительства. Arxiv Preprint arxiv: 2207.07635, 2022. 11
[101] Мерт Бюулент Сарийлдыз, Каркик Алахари, Дайан Ларлус и Яннис Калантидис. Подделка до тех пор, пока вы не сделаете: обучение переносимым представлениям от синтетических клонов ImageNet. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2023. 11
[102] Кристоф Шуманн, Ричард Венку, Ромен Бомонт, Роберт Качмарчик, Клейтон Муллис, Ааруш Катта, Тео Кумбс, Джена Джитев и Аран Комацузаки. LAION-400M: Откройте набор данных из 400 миллионов картинок 400 миллионов. Arxiv Preprint arxiv: 2111.02114, 2021. 2, 4, 5, 22
[103] Кристоф Шуманн, Роман Бомонт, Ричард Венку, Кейд Гордон, Росс Вайтман, Мехди Черти, Тео Кумбес, Ааруш Катта, Клейтон Муллис, Митчелл Вортсман, et al. LAION-5B: открытый крупномасштабный набор данных для обучения моделей изображений следующего поколения. Достижения в системах обработки нейронной информации, 35: 25278–25294, 2022. 2, 4, 22
[104] Прити Сешадри, Самир Сингх и Янай Элазар. Парадокс амплификации смещения в генерации текста до изображения. Arxiv Preprint arxiv: 2308.00755, 2023. 11
[105] Хасан Шахмохаммади, Адхирадж Гош и Хендрик Ленш. VIPE: Визуализируйте довольно много всего. В материалах конференции 2023 года по эмпирическим методам обработки естественного языка, стр. 5477–5494, 2023. 16
[106] Ханьин Шао, Цзе Хуанг, Шен Чжэн и Кевин Чен-Чен Чанг. Количественная оценка возможностей ассоциации крупных языковых моделей и ее последствия для утечки конфиденциальности. Arxiv Preprint arxiv: 2305.12707, 2023. 11
[107] Пиюш Шарма, Нан Дин, Себастьян Гудман и Раду Сорикут. Концептуальные подписи: очищенный, гипернименный, изображение альт-текстовое набор данных для автоматического подписания изображения. В материалах 56 -го ежегодного собрания Ассоциации вычислительной лингвистики (том 1: длинные работы), страницы 2556–2565, 2018. 2, 4, 22
[108] Хуррам Сумро, Амир Рошан Замир и Мубарак Шах. UCF101: набор данных из 101 класса человеческих действий из видео в дикой природе. Arxiv Preprint arxiv: 1212.0402, 2012. 4
[109] Бен Соршер, Роберт Гейрхос, Шашанк Шехар, Сурья Гангули и Ари Моркос. Помимо законов о нейронном масштабировании: превышение масштабирования законодательства о власти за счет обрезки данных. Достижения в области систем обработки нейронной информации, 35: 19523–19536, 2022. 11
[110] Студент. Возможная ошибка коэффициента корреляции. Биометрика, страницы 302–310, 1908. 6
[111] Кристиан Сегеди, Вэй Лю, Янццин Цзя, Пьер Серманет, Скотт Рид, Драгомир Ангуэлов, Дюмитру Эрхан, Винсент Ванхук и Эндрю Рабинович. Пойду глубже с свертыми. В конференции по компьютерному видению и распознаванию шаблонов (CVPR), 2015. 11
[112] Команда Близнецов, Рохан Анил, Себастьян Борги, Йонхуи Ву, Жан-Батист Алайрак, Цзяхуи Ю, Раду Сорикут, Йохан Шальквик, Эндрю М. Дай, Анджа Хаут и др. Близнецы: семейство очень способных мультимодальных моделей. Arxiv Preprint arxiv: 2312.11805, 2023. 10
[113] Барт Томе, Дэвид А. Шамма, Джеральд Фридленд, Бенджамин Элизальде, Карл Ни, Дуглас Польша, Дамиан Борт и Ли-Цзия Ли. YFCC100M: новые данные в мультимедийных исследованиях. Сообщение ACM, 59 (2): 64–73, 2016. 2, 4, 22
[114] Тристан Трод, Райан Цзян, Макс Бартоло, Аманприт Сингх, Адина Уильямс, Доуве Киела и Кэндис Росс. Винограунд: зондирование видения и языковых моделей для Visio-ilingistic Compositionally. В конференции по компьютерному видению и распознаванию шаблонов (CVPR), 2022. 5
[115] Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang и Dilip Krishnan. Stablerep: Синтетические изображения из моделей текста до изображения делают сильных учеников визуального представления. Конференция по системам обработки нейронной информации (Neurips), 2023. 11
[116] Кушал Тирумала, Даниэль Симиг, Армен Агаджаньян и Ари Моркос. D4: Улучшение предварительной подготовки LLM с помощью детукации и диверсификации документов. Достижения в области систем обработки нейронной информации, 36, 2024. 11
[117] Вишаал Удандарао, Абхишек Майти, Дипак Шриватсав, Сурьятер Редди Вялла, Ифанг Инь и Раджив Ратин Шах. COBRA: контрастный алгоритм биодального представления. Arxiv Preprint arxiv: 2005.03687, 2020. 1
[118] Вишаал Удандарао, Макс Ф. Бург, Сэмюэл Албани и Матиас Бетге. Понимание визуального типа не возникает из масштабирования моделей на языке зрения. Arxiv Preprint arxiv: 2310.08577, 2023. 11
[119] Вишаал Удандарао, Анкуш Гупта и Сэмюэл Албани. SUS-X: Без обучения передачи моделей VisionLanguage только для названия. В Международной конференции по компьютерному видению (ICCV), 2023. 11
[120] Паван Кумар Анасосалиу Васу, Хади Пурансари, Фарташ Фагри, Равитха Вемулапалли и на Тузеле. Mobileclip: быстрое изображение модели через мультимодальное усиленное обучение. Arxiv Preprint arxiv: 2311.17049, 2023. 11
[121] Кэтрин Вах, Стив Брэнсон, Питер Влиндер, Пьетро Перона и Сержа. Набор данных Caltech-UCSD Birds-200- 2011. 2011. 4
[122] Стивен Уолфиш. Обзор статистических выбросов методов. Фармацевтическая технология, 30 (11): 82, 2006. 6
[123] Цзянсионг Сяо, Джеймс Хейс, Криста Эхингер, Ауда Олива и Антонио Торральба. База данных Sun: крупномасштабное распознавание сцены от аббатства до зоопарка. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2010. 4
[124] Ху Сюй, Санинг Си, По-Яо Хуанг, Личэн Ю, Рассел Хоус, Гарги Гош, Люк Зеттлемуер и Кристоф Фейхтенхофер. CIT: курирование в обучении для эффективных данных на языке зрения, 2023. 4, 8, 11
[125] Ху Сюй, Санинг Си, Сяоцинг Эллен Тан, По-Яо Хуанг, Рассел Хоус, Васу Шарма, Шан-Вэнь Ли, Гарги Гош, Люк Зеттлемуер и Кристоф Фейхтенхофер. Демостификация данных клипа, 2023. 2, 11, 22
[126] Цзинью Ян, Джиали Дуан, сын Тран, Йи Сюй, Сампат Чанда, Ликун Чен, Белинда Зенг, Тришул Чилимби и Джунчжоу Хуанг. Правозависимость на языке зрения с тройным контрастным обучением. В конференции по компьютерному видению и распознаванию шаблонов (CVPR), 2022. 1
[127] Грегори Яуни, Эмили Рейф и Дэвид Мимно. Сходства данных недостаточно, чтобы объяснить производительность языковой модели. Arxiv Preprint arxiv: 2311.09006, 2023. 2, 7, 11
[128] Питер Янг, Алиса Лай, Мика Ходош и Джулия Хокенмайер. От описаний изображений до визуальных обозначений: новые показатели сходства для семантического вывода по описанию событий. Транзакции Ассоциации вычислительной лингвистики, 2: 67–78, 2014. 4
[129] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini и Yonghui Wu. Coca: контрастные подписи являются моделями фонда с изображением текста. Arxiv Preprint arxiv: 2205.01917, 2022. 1
[130] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Масштабирование авторегрессивных моделей для богатого контентом генерации текста до изображения. Arxiv Preprint arxiv: 2206.10789, 2 (3): 5, 2022. 5
[131] Qiying Yu, Quan Sun, Xiaosong Zhang, Yufeng Cui, Fan Zhang, Xinlong Wang и Jingjing Liu. CapsFusion: переосмысление данных изображения-текста в масштабе. Arxiv Preprint arxiv: 2310.20550, 2023. 11
[132] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Андреас Штайнер, Даниэль Кизерс, Александр Колесников и Лукас Бейер. Горит: перенос с нулевым выстрелом с настройкой текста заблокированного изображения. В конференции по компьютерному видению и распознаванию шаблонов (CVPR), 2022. 1
[133] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov и Lucas Beyer. Сигмоидальная потеря для преподавания изображения языка. Arxiv Preprint arxiv: 2303.15343, 2023. 1
[134] Ренруи Чжан, Сянфей Ху, Бохао Ли, Сиюан Хуанг, Ханкю Денг, Ю Цяо, Пенг Гао и Хоншенг Ли. Призревает, генерируйте, затем кэш: каскад моделей фундамента делает сильных учащихся. В конференции по компьютерному видению и распознаванию образцов (CVPR), 2023. 11
[135] Юнхуа Чжан, Хейзел Даути и Г.М. Сноэк. Проблемы зрения с низким ресурсом для моделей фундамента. Arxiv Preprint arxiv: 2401.04716, 2024. 11
[136] Джордж Кингсли Зипф. Поведение человека и принцип наименьших усилий: введение в экологию человека. Ravenio Books, 2016. 8
Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал