
Что 300 ГБ исследований ИИ показывает о истинных пределах «нулевого выстрела» интеллекта
9 июля 2025 г.Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Таблица ссылок
Аннотация и 1. Введение
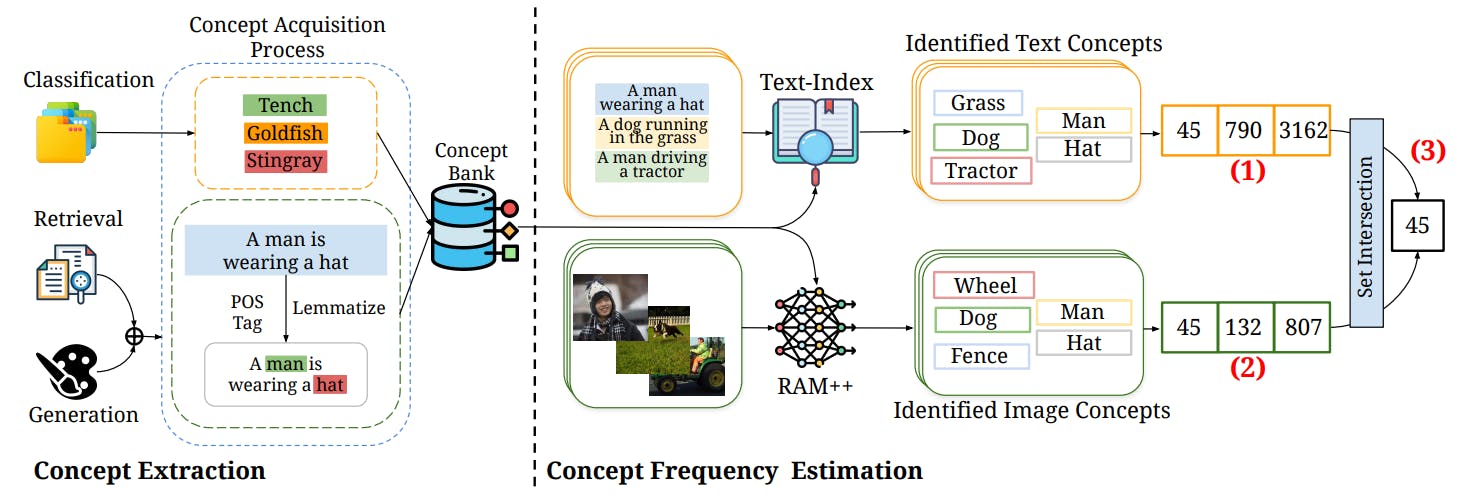
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
Абстрактный
Наборы данных предварительных данных в веб-карете лежат в основе впечатляющих результатов оценки «нулевого выстрела» мультимодальных моделей, таких как клип для классификации/поиска и стабильная диффузия для генерации изображений. Тем не менее, неясно, насколько значимо понятие «нулевой выставки»обобщениедля таких мультимодальных моделей, так как неизвестно, в какой степени их предварительные наборы данных охватывают концепции нижестоящих направлений, нацеленные на «нулевой выстрел». В этой работе мы спрашиваем:Как на производительность мультимодальных моделей на нижестоящих концепциях влияет частота этих концепций в их наборах данных предварительного подготовки?
Мы всесторонне исследуем этот вопрос в 34 моделях и в пяти стандартных наборах данных предварительных предварительных данных (CC-3M, CC-12M, YFCC-15M, LAION-400M, LAION-AESTETICS), генерируя более 300 ГБ артефактов данных. Мы последовательно обнаруживаем, что, далеко не демонстрируя обобщение «нулевого выстрела», мультимодальные модели требуют экспоненциально большего количества данных для достижения линейных улучшений в нисходящей производительности «нулевого выстрела», следуя образцу неэффективной тенденции логарифмического масштабирования. Эта тенденция сохраняется даже при контроле сходства на уровне выборки между предварительной подготовкой и нижестоящими наборами данных [79] и тестированием на чисто синтетические распределения данных [51]. Кроме того, на сравнительных моделях на длиннохвостых данных, отобранных на основе нашего анализа, мы демонстрируем, что мультимодальные модели по всей плате работают плохо. Мы вкладываем этот набор тестов с длинным хвостом в качествеПусть это виляет!эталон для дальнейших исследований в этом направлении. Взятые вместе, наше исследование показывает экспоненциальную потребность в обучении данных, которая подразумевает, что ключ к возможностям обобщения «нулевой выстрел» при крупномасштабных учебных парадигмах еще предстоит найти.
1 Введение
Мультимодальные модели, такие как Clip [91] и стабильная диффузия [96], произвели революцию в выполнении нисходящих задач-Clip в настоящее время является de-facto для распознавания изображений «с нулевым выстрелом» [133, 72, 126, 48, 132], а ImageText-поиск [46, 64, 24, 117, 129], в то время как Stable Diffusion STANKEME-STANDE-STANDE-STAMELE-TO-TO-TO-TO-TO-TO-TO-TO-STANDERE. (T2I) поколение [93, 17, 96, 41]. В этой работе мы исследуем этот эмпирический успех через призму обобщения с нулевым выстрелом [69], что относится к способности модели применять свои ученые знания к новым невидимым концепциям. Соответственно, мы спрашиваем:Действительно ли современные мультимодальные модели способны к обобщению «нулевого выстрела»?
Чтобы решить эту проблему, мы провели сравнительный анализ, включающий два основных фактора: (1) эффективность моделей по различным нижестоящим задачам и (2) частота тестовых концепций в их предварительных наборах данных. Мы составили комплексный список из 4, 029 концепций [1] из 27 нисходящих задач, охватывающих классификацию, поиск и генерацию изображений, оценивая эффективность против этих концепций. Наш анализ охватывал пять крупномасштабных наборов данных с различными масштабами, методами курирования данных и источниками (CC-3M [107], CC-12M [27], YFCC-15M [113], LAION-AESTHETICS [103], LAION-400M [102]) и оценил производительность из 10 моделей Clip Models и 24 T2I-моделей, а также PAMATERES-ARCICETERAS и PAM-ARTECTERS-ARCICETERS и PAMPERTERES-ARCICETRES. Мы постоянно находим во всех наших экспериментах, что в разных концепциях частота концепции в наборе данных предварительной подготовки является сильным предиктором эффективности модели на тестовых примерах, содержащих эту концепцию. Примечательно,Производительность модели линейно масштабируется, поскольку частота концепции в предварительных данных растут в геометрической прогрессии.то есть,Мы наблюдаем постоянную тенденцию логарифмического масштабирования. Мы обнаруживаем, что эта логарифмическая тенденция устойчива к контролю коррелированных факторов (аналогичные образцы в предварительной подготовке и тестировании данных [79]) и тестировании по различным распределениям концепций, а также образцы, созданные полностью синтетически [51].
Наши результаты показывают, что впечатляющие эмпирические характеристики мультимодальных моделей, таких как Clip и стабильная диффузия, могут быть в значительной степени связаны с наличием тестовых концепций в их обширных наборах данных, поэтому их сообщаемая эмпирическая производительность не составляет «нулевого выстрела». Наоборот, эти модели требуют экспоненциально большего количества данных о концепции, чтобы линейно улучшить их производительность по задачам, относящимся к этой концепции, подчеркивая экстремальную неэффективность выборки.
В нашем анализе мы дополнительно документируем распределение концепций, встречающихся в предварительных данных, и обнаруживаем, что:
• Распределение концепции:Во всех наборах данных предварительно подготовки распределение концепций является длинным хвостом (см. Рис. 5 в сек. 5), что указывает на то, что большая часть концепций встречается редко. Однако, учитывая наблюдаемый экстремальный образцы неэффективности, то, что редко, не изучается должным образом во время мультимодальной предварительной подготовки.
• Корреляция концепции в предварительных наборах данных:Распределение концепций по различным наборам данных предварительно предварительно связано с тесным коррелированием (см. Вкладку 4 в раздел.
• Размещение в тексте изображения между концепциями в предварительных данных:Концепции часто появляются в одной модальности, но не в другой, что подразумевает значительное смещение (см. Вкладку 3 в разделах 5). Наши выпущенные артефакты данных могут помочь усилиям по выравниванию текста изображений в масштабе, точно указывая на примеры, в которых методы смешиваются. Обратите внимание, что логарифмическая тенденция в обоих методах является устойчивой к этому смещению.
Чтобы обеспечить простой эталон для производительности обобщения для мультимодальных моделей, который управляет частотой концепции в учебном наборе, мы вводим новый набор тестирования с длинным хвостами под названием«Пусть это виляет!».Текущие модели, обученные как открыто доступным наборам данных (например, LAION-2B [103], DATACOMP-1B [46]), так и наборах данных с закрытым исходным кодом (например, OpenAI-WIT [91], Webli [29]), имеют значительное падение производительности, предоставляя доказательства того, что наши наблюдения могут также перенести в данные с закрытым источником. Мы публично выпускаем все наши артефакты данных (более 300 ГБ), амортизируя стоимость анализа наборов данных предварительного подготовки моделей мультимодальных фундаментов для более ориентированного на данные понимание свойств мультимодальных моделей в будущем.
Несколько предыдущих работ [91, 46, 82, 42, 83, 74] исследовали роль предварительных данных в влиянии на производительность. Mayilvahanan et al. [79] показали, что производительность клипа коррелирует с сходством между наборами данных обучения и тестирования. В других исследованиях по конкретным областям, таким как вопросы, отвечающие вопросам [62] и численное мышление [94] в моделях крупных языков, сходство с высоким тестированием поезда не в полной мере учитывало наблюдаемые уровни производительности [127]. Наш всесторонний анализ нескольких наборов данных с образованием текста изображения значительно добавляет к этой линии работы, (1) показывая, что частота концепции определяет производительность с нулевым выстрелом и (2) определяет экспоненциальную потребность в учебных данных как фундаментальную проблему для современных крупномасштабных мультимодальных моделей. Мы пришли к выводу, что ключ к возможностям обобщения «нулевой выставки» при крупномасштабных учебных парадигмах еще предстоит найти.
Эта статья есть
[1] Категории классов для классификационных задач, объектов в текстовых подписях для поиска задач и объектов в текстовых подсказках для задач генерации, см. Sec. 2 Для получения более подробной информации о том, как мы определяем концепции.
Оригинал