

Мы разработали исследование, чтобы увидеть, сможет ли ИИ подражать реальным программным ошибкам
4 июня 2025 г.Авторы:
(1) Бо Ван, Университет Пекин Цзиотонг, Пекин, Китай (wangbo_cs@bjtu.edu.cn);
(2) Mingda Chen, Пекинский университет Цзиотонга, Пекин, Китай (23120337@bjtu.edu.cn);
(3) Youfang Lin, Пекинский университет Цзиотонг, Пекин, Китай (yflin@bjtu.edu.cn);
(4) Майк Пападакис, Университет Люксембурга, Люксембург (michail.papadakis@uni.lu);
(5) Цзе М. Чжан, Королевский колледж Лондон, Лондон, Великобритания (jie.zhang@kcl.ac.uk).
Таблица ссылок
Аннотация и1 Введение
2 предыстория и связанная с ним работа
3 Учебный дизайн
3.1 Обзор и исследования исследований
3.2 Наборы данных
3.3 генерация мутаций через LLMS
3.4 Метрики оценки
3.5 Настройки эксперимента
4 Результаты оценки
4.1 RQ1: производительность по стоимости и юзабилити
4.2 RQ2: сходство поведения
4.3 RQ3: воздействие различных подсказок
4.4 RQ4: воздействие различных LLMS
4.5 RQ5: основные причины и типы ошибок некомпилируемых мутаций
5 Обсуждение
5.1 Чувствительность к выбранным настройкам эксперимента
5.2 Последствия
5.3 Угрозы достоверности
6 Заключение и ссылки
3 Учебный дизайн
3.1 Обзор и исследования исследований
Наша статья намерена тщательно исследовать возможности существующих LLM в генерации мутаций. Мы разрабатываем вопросы исследований, охватывающие оценку настройки нашего исследования по умолчанию, влияние быстрых инженерных стратегий и моделей, а также анализ основной причины для неэффективных аспектов. В частности, мы стремимся ответить на следующие пять вопросов исследования.
• rQ1: Как LLM работают при создании мутаций с точки зрения стоимости и удобства использования?
• RQ2: Как LLM работают в генерации мутаций с точки зрения сходства поведения с реальными ошибками?
• RQ3: Как различные подсказки влияют на производительность при создании мутаций?
• RQ4: Как различные LLM влияют на производительность при создании мутаций?
• RQ5: Каковы основные причины и типы ошибок компиляции для генерации некомпилируемых мутаций?
3.2 Наборы данных
Мы намерены оценить наш подход с помощью реальных ошибок, и поэтому нам нужно использовать наборы данных ошибок со следующими свойствами:
• Наборы данных должны включать Java -программы, поскольку существующие методы в основном основаны на Java, и нам нужно сравнить с ними.
• Ошибки наборов данных должны быть ошибками в реальном мире, чтобы мы могли сравнить разницу между мутациями и реальными ошибками.
• Каждая ошибка в наборах данных имеет правильную фиксированную версию, предоставленную разработчиками, чтобы мы могли мутировать фиксированную версию и сравнить их с соответствующими реальными ошибками.
• Каждая ошибка сопровождается хотя бы одним тестом, вызывающим ошибку, потому что нам нужно измерить, влияют ли мутации на выполнение тестов, вызывающих ошибки.
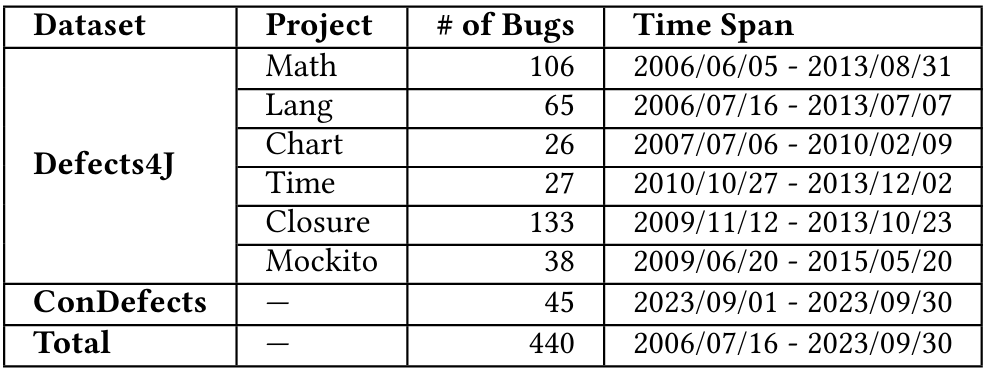
С этой целью мы используем Defects4j v1.2.0 [37] и проводят проведения [82] для оценки подходов к генерации мутаций, показанных в таблице 1. В целом, мы проводим эксперименты на 440 ошибках.
Defects4J является широко используемым эталоном в области тестирования на мутации [15, 38, 40, 43, 55, 70], который содержит исторические ошибки из 6 проектов с открытым исходным кодом, обеспечивая широкое представление реальных ошибок. В общей сложности эти 6 проектов содержат 395 реальных ошибок. Тем не менее, из таблицы 2 и таблицы 1 мы наблюдаем, что промежутки времени ошибок Defects4J раньше, чем время обучения LLMS, что может вводить утечку данных. Поэтому мы дополняем еще один набор данных, проводятся [82], предназначенные для решения проблем утечки данных. Condefects состоит из задач из конкурса программирования Atcoder [2]. Чтобы предотвратить утечку данных, мы используем исключительно ошибки, о которых сообщалось после даты выпуска LLMS, в частности, те, которые были идентифицированы 31 августа 2023 года или после этого, и в общей сложности мы собираем 45 программ Java из Cindefects.
Эта статья есть
Оригинал
Recent Post
-
Небольшие коммиты, большие победы: как атомные изменения преобразуют жизнь разработчика
20 августа 2025 г. -
Начало работы с государственным управлением в Still.js
20 августа 2025 г. -
Однородность и нормальность: как проверить ваши экспериментальные данные
20 августа 2025 г. -
Революционизация QA: Мой путь к созданию уникального аудита, который сокращает затраты и повышает эффективность
20 августа 2025 г. -
Больше нет «корабля и молитвы»: тестирование биллинговых систем SaaS с тестовыми часами Playwright & Stripe
20 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика