

Стихи AI навсегда меняют робототехнику с активным выводом прорыва
18 августа 2025 г.Переход от «Инструментов» к товарищам по команде, которые «думают с нами».
Мы все работали с кем -то, кто мог бы следовать инструкциям, но не мог адаптироваться, когда все изменилось. У нас даже есть уничижительный термин, чтобы описать такого человека, как это:инструмент--Возможно, надежный, но узкий, жесткий и в конечном итоге больше работы для остальной части команды.
АПартнер, с другой стороны, думает с вами. Они ожидают. Они адаптируются. Они вносят вклад в общую миссию.
Сегодняшние роботы, несмотря на всю их механическую точность, в значительной степени попали в эту категорию: они являются мощными инструментами, но они все еще являются инструментами. У них нетагентствоПолем Они могут следовать предварительно подписанной последовательности движений, но если среда неожиданно изменится-Коробка не на месте, появляется новое препятствие, смены освещения-Они запутаются, терпят неудачу или требуют обширной переподготовки.
Если агент или член команды (человек или машина) имеет:
- Нет способности рассуждать о контексте
- Нет гибкости для адаптации планов
- Нет возможности интегрировать перспективы других в свою модель
… Тогда они не настоящий «агент». Они могут работать только в узкой полосе. Они могут выполнить свою конкретную часть хорошо, ноОнибесполезно (а иногда и опасно), когда условия меняютсяПолем Такие роботы требуют постоянного микроуправления человека. В непредсказуемых условиях это не просто неэффективно-Это небезопасно.
ЧтоНам действительно нужнопартнеры-Роботизированные товарищи по команде с агентством, которые могут прочитать ситуацию, адаптироваться в режиме реального времени и разум о миссии вместе с нами.

И теперь, впервые, недавнее исследование из стихов AI разрушило этот барьер с помощью активного вывода.
Продвижение робототехники через нейробиологию: делать то, чего никогда не делалось раньше
Новая газета тихо упала 23 июля 2025 года под названием «Мобильные манипуляции с активным выводом для задач пересталкиПолем«В нем,Стихи ИИИсследовательская группа, возглавляемая всемирно известным нейробиоусом, доктором Карлом Фристоном,Демонстрирует план нового стека управления робототехникой, который достигает того, чего никогда не было возможным раньше: Внутренняя архитектура множественных активных агентов вывода в одном теле роботов-работая вместе для контроля всего тела, чтобы адаптироваться и учиться в режиме реального времени в незнакомых средах. ЭтотИерархическая, многоагентная структура активного вывода позволяет роботам адаптироваться в режиме реального времени, планировать длинные последовательности и восстанавливаться от неожиданных проблем,все без переподготовки.
В отличие от современных роботов, которые работают как один монолитный контроллер,Этот новый план работает как сеть коллективных интеллектуальных агентов, каждый из которых работаетАктивный вывод-где каждый соединение, каждая конечность, каждый контроллер движения сам по себе являетсяАгент Агент выводаБлагодаря своему местному пониманию мира, все это координируется вместе под моделью активного вывода более высокого уровня-робота.
Думайте об этом как о миниатюрном обществе, принимающих решения, живущих в теле одного робота:
- Агенты совместного уровня-Каждый сустав (например, локоть, запястье, колесо), предсказывая и контролирующие его движение на основе сенсорной обратной связи, мгновенно регулируя, если есть сопротивление или проскальзывание.
- Агенты уровня конечностей-Координация между суставами для достижения когерентного движения конечности (например, полная рука или перемещение базы).
- Агент всего тела-Интеграция множества конечностей и навигации для выполнения скоординированных навыков (например, достижение и захват во время движения).
- Планировщик высокого уровня-Выбор навыка для выполнения следующего, на основе текущей цели и среды.
Агенты нижнего уровня обрабатывают точный контроль (например, перемещение захвата), в то время как агенты более высокого уровня планируют последовательности действий для достижения целей.
Каждый агент сохраняет внутренние убеждения (о своем собственном состоянии) и внешние убеждения (о его отношении к миру).
Эти агенты постоянно делятся обновлениями веры и ошибки прогнозирования:
- Если один сустав встречает неожиданное сопротивление, информация каскады вверх, а план высокого уровня корректируется в миллисекундах.
- Сценарий восстановления с жестким кодированием не требуется-Корректировка естественным образом возникает в данный момент от процесса активного вывода.
Фактически,Роботсложная адаптивная система коллективного интеллекта-Очень похоже на координацию человеческого тела между мышцами, рефлексами и сознательным планированием.
Все эти агенты, работающие вместе в роботе, могут постоянно общаться, обновляя свои убеждения на основе принципа свободной энергии доктора Карла Фристона-Та же самая математическая структура, которая лежит в основе человеческого восприятия, обучения и действия. Эти активные агенты вывода в тела робота доля друг с другом, как и их убеждение, говорится о мире и постоянно обновляет свои действия на основе ошибок прогнозирования. Это тот же процесс, который люди используют при ходьбе по многолюдной комнате, несущей кофе: постоянные микрореплссы на уровне сустава, координация конечностей для баланса и планирование высокого уровня для навигации.
Это означает, что эти активные роботы вывода не просто выполняют предварительно запрограммированные действия, они воспринимают, предсказывают и планируют согласовать, динамически корректируя мгновенно, если мир не соответствует их ожиданиям. Это то, что роботы подкрепляющего обучения (RL) просто не могут сделать, так как каждая корректировка требует обширной переподготовки.
Это не просто обновление до робототехники.Это переопределение того, что такое робот.
Аксиома и VBG: сила под капюшоном
Этот прорыв не остается одиноким-Он построен на двух других основных стихах инноваций:
Аксиома:Новая бесплатная архитектура активного вывода, которая объединяет восприятие, планирование и контроль в одной генеративной модели.
- Агенты совместного уровня и стратегические планировщики высокого уровня используют одну и ту же структуру рассуждений.
- Это делает человеческий вход естественным образом совместимым с рассуждением машины.
VBG (вариационное байеса Гауссовое распад):Вероятностный, «неопределенность» метод для создания 3D-карт с высокой точки зрения из данных датчиков.
- Роботы могут представлять свою среду как карту убеждений-и поделиться этим с людьми через HSML.
- Неопределенность явно, что делает совместное планирование более безопасным и прозрачным.
Вместе аксиома и VBG дают роботам активного вывода мозга и чувства, настроенные для команды в реальном времени.
Давайте погрузимся глубже ...
Что нам на самом деле нужны роботы?

- Безопасно работать в динамичных, загроможденных, человеческих пространствах.
- Планируйте не только следующий шаг, но и следующий дюжина, и при необходимости измените курс.
- Сообщите их рассуждения и то, что они знают, и не знают людям.
- Обобщение по макетам, объектам и условиям без недель переподготовки.
До сих пор область робототехники изо всех сил пыталась соответствовать этому стандарту. Большинство систем управления либо:
- Жестко предварительно запрограммирован-эффективно только в узких, предсказуемых задачах, или
- Главные данные о глубоком обучении-Способный, но хрупкий, требующий огромного количества маркированных данных обучения и все еще подверженных неудачам, когда реальный мир не соответствует обучению.
Почему роботы борьбы подкрепляют обучение (RL) (и почему это важно)

Подкрепление обучения (RL) привело к впечатляющим демонстрациям, но оно попадает в стены в реальном мире:
Массовые требования к обучению:Агенты RL часто требуютмиллионыпробных и ошибочных взаимодействий в моделировании, чтобы овладеть задачей. Это хорошо для одной фиксированной задачи, но невозможно масштабироваться для каждого вариации, с которым может столкнуться робот в реальном мире.
Плохое обобщение:Обурите робота RL, чтобы сложить красные блоки в одной комнате, и он не обязательно будет складывать синие блоки в другой без переподготовки. Знание не очень хорошо обобщается на изменения в цвете, форме, освещении или макете.
Бриттли, чтобы измениться: Политики RL оптимизированы для точных условий их обучения. Небольшой сдвиг - новое препятствие, немного другой размер объекта - может вызвать катастрофический сбой.
Жесткий, неадаптивный контроль тела: RL StacksнеАгенты рассуждений хозяина в каждой степени свободы (DOF). Контроль в отдельных суставах/приводах предварительно запрограммируется для задачи/среды, на которую она была обучена. Если среда меняется (более тяжелый объект, скользящий пол, джемы ящика, размахивание дверей шире), вы должны тщательно переучить стек, от контроллеров низкого уровня до навыков среднего уровня, чтобы ручные руки не провалились.
Нет встроенного осознания неопределенности:Агенты RL действуют так, как будто их внутренняя модель всегда верна. Они явно не отслеживают то, что онинезнаю, что затрудняет безопасную адаптацию.
Неэффективность в задачах с длинным хоризоном:Когда задача требует нескольких шагов в течение длинной последовательности (например, настройка стола или перестройка комнаты), RL борется с планированием и секвенированием, не разбивая его на более мелкие, сильно предварительно обученные модули.
Результат? Роботы для подкрепления обучения-это мощные инструменты, которые могут сиять в лабораторных критериях для фиксированного контекста, но в реальной обстановке, таких как склад, больница или зона бедствий, они слишком жесткие и хрупкие, чтобы их доверяют независимым операторам, и они дороги для замены в каждом новом варианте.
Внутренняя логика в активном выводе
В активном выводе логика не прикрепляется к выпуску как «набор правил»-Это происходит естественно из:
Генеративная модель -который кодирует убеждения/понимание агента о том, как работает мир.
Приоры и ограничения в этой модели -которые действуют как «Правила игры».
НепрерывныйПрогнозирование - циклы коррекции-которые поддерживают внутреннюю последовательность и адаптируют рассуждения к реальным условиям.
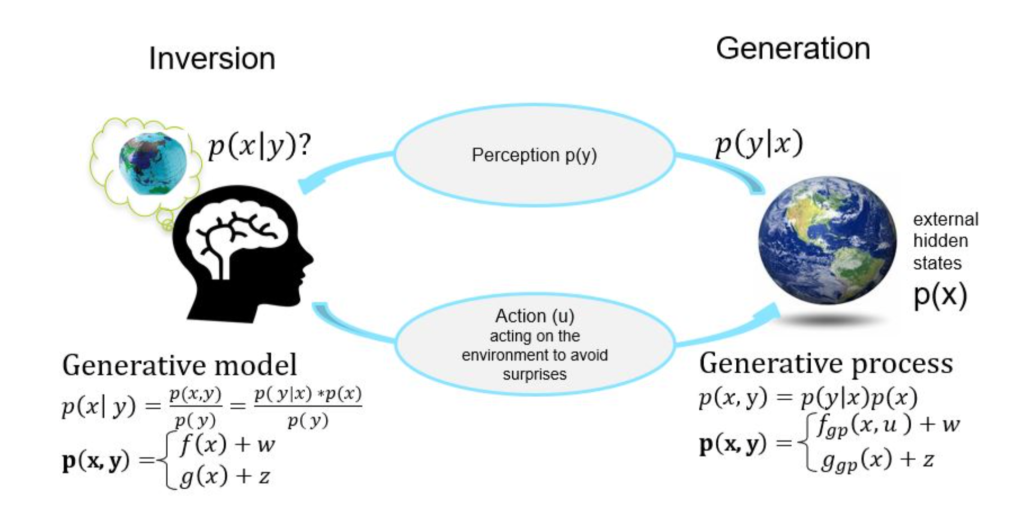
Это означает, что логика здесь является вероятностной и контекстуальной:
- Агент постоянно проверяет:«Имеет ли это действие или вера, учитывая то, что я ожидаю?»
- Если нет, то он приспосабливается, как человек, который переосмысливает решение, когда появляются новые доказательства.
Активный прорыв
Новое исследование стихов меняет игру для робототехники.
Вместо одной политики в области монолитного подкрепления (RL) их архитектура создает иерархию интеллектуальных агентов внутри робота, каждая из которых работает по принципам активного вывода и принципа свободной энергии для плавного обучения и адаптации в режиме реального времени.
Вот что отличается:
- Агенты в каждом масштабе -У каждого сустава в теле робота есть свой «местный» агент, способный рассуждать и адаптироваться в режиме реального времени. Они подаются в агенты уровня конечности (например, ARM, Gripper, Mobile Base), которые, в свою очередь, превращаются в агента всего тела, который координирует движение. Выше этого расположена высокоуровневый планировщик, который последовает многоэтапные задачи.
- Адаптация в реальном времени-Если один сустав испытывает неожиданное сопротивление, локальный агент мгновенно регулируется, в то время как агенты уровня конечности и целого тела плавно адаптируют оставшуюся часть движения, не останавливая задачу.
- Композиция навыков -Робот может объединить ранее изученные навыки по -новому, что позволяет им импровизировать при столкновении с новыми задачами или средами.
- Встроенное отслеживание неопределенности-Активные выводы агентовмоделировать то, что они не знают, обеспечивает более безопасное, более осторожное поведение в незнакомых ситуациях.
Результатом является система, которая может войти в среду, которую она никогда не видела, понимала задачу и выполняет ее - непрерывно адаптируясь по мере изменения условий.
Более внимательный взгляд на робота из агентов
Мы обсуждаем сложную адаптивную систему, которая работает в каждом масштабе тела.
- Агенты совместного уровня (по DOF/степени свободы): поддерживатьвнутренние убеждения(их углы/скорости) иВнешние убеждения(Поза в космосе). Они предсказывают сенсорные результаты и минимизируют ошибку прогнозирования (различия между ожидаемой и наблюдаемой проприоцепцией/видением) с момента к моменту.
Это имитирует чувство человеческого тела о его положении и движении в космосе;Способность двигаться без осознанных мыслей, например, ходить, не глядя на наши ноги. Этот смысл опирается на сенсорные рецепторы в мышцах, суставах и сухожилиях, которые посылают в мозг информацию о положении тела и движении.
- Агенты на уровне конечности (рука, захват, основа): Интегрируйте совместные убеждения, установите декартовые цели и ограничения (например, достичь траектории, поза захвата, базовый заголовок) и договориться с суставами с помощью анкеры с топ -маршрутами и ошибки в нижней части.
- Агент всего тела:Создает навыки (выберите, место, перемещение, выборка/ящик), достижение одновременной навигации и манипуляции, с предотвращением столкновений.
- Планировщик высокого уровня:Причины по сравнению с отдельными состояниями задачи (например, объект в инвентаризации по сравнению с контейнером; робот в местоположении Pick vs. Place), навыки последовательностей и повторения с альтернативными параметрами подхода при обнаружении сбоев,Все без автономного переподготовки.
Как это работает (интуитивно):
Каждый уровень выполняет один и тот же принцип: Минимизировать свободную энергию, выравнивая прогнозы с ощущениями и целями.
Сверху вниз:Более высокие агенты отправляют предпочтения/цели (априоры) более низким.
Вверх дном:Нижние агенты отправляют ошибки прогноза вверх, когда реальность отклоняется.
Этот круговой поток дает адаптацию в реальном времени: если запястье чувствует неожиданный крутящий момент, рука регулирует, базовая репозиция для левереджа и планировщик переключается на альтернативное понимание - без остановки или перепрограммирования.
Базовая связь с связью:База не является отдельным «режимом навигации». Its free‑energy minimization includes arm prediction errors, so the robot walks its body to help the arm (extending reach, improving approach geometry). Вот как ты получаешьМанипуляция всего телаПолем
Восприятие, которое учится по мере его движения: вариационное байестное распад (VBG)
Роботам нужна мировая модель, которая обновляется онлайн, не забывая. VBGS обеспечивает это по:
Представление сцены как смесь гауссов в 3D -позиции + цвет(вероятностное поле сияния/занятости).
Обучение с помощью закрытых вариационных обновлений байесов(Cavi с сопряженными априорами), поэтому он может употреблять потоковые RGB -D без буферов воспроизведения или BackProp.
Поддержание неопределенности для каждого компонента-Идеально подходит для планирования риска и предотвращения препятствий.
Включая эвристику смены компонента для быстрого покрытия недостаточно моделированных регионов*; поддерживает постоянное обучение без катастрофического забывания.*
В роботе: VBGS строит вероятностную карту препятствий, сочлененных поверхностей (ящики, двери холодильника) и свободное пространство. Контроллер считывает эту карту для планирования путей и движений, придавая более высокие «затраты» оккупированным или рискованным регионам. Поскольку карта является байесовской, где она обозначает высокую неопределенность, политика, которая направляет смену робота к консервативному поведению (замедленному вниз, удержанию расстояния) или инициирует «активное зондирование» для сбора информации, как краткое изменение повторного сканирования или точки зрения, прежде чем принять контакт.
Масштабируемое когнитивное ядро: аксиома (объектно -центр активный вывод)
Аксиома дополняет воплощенный контроль с помощью мировой модели и ядра планирования, которое является быстрым, интерпретируемым и расширяемым:
SMM (модель смеси слот):Подборки пиксели в объектно -центрированные законопов. (Положение, цвет, экстент) через смеси.
Imm (идентификационная смесь):назначает токены типа (идентификация объекта) из непрерывных функций; Динамика, связанная с типом, обобщается по случаям.
TMM (переходная смесь):Переключение линейной динамики (SLDS) открыть для себя примитивы движения (падение, скольжение, подпрыгивание), разделенное по объектам.
RMM (повторяющаяся смесь):Учит редкие взаимодействия (столкновения, вознаграждения, действия), связывая объекты, действия и переключатели режима.
Рост и байесовская модель снижения:Расширяет компоненты на велосипеде, когда данные требуют этого; Позже объединяет избыточные кластеры, чтобы упростить и обобщать.
Планирование по ожидаемой свободной энергии:Торгуется утилита (вознаграждение) с получением информации (узнайте, что имеет значение), выбирая действия, которые достигают целей и снижают неопределенность.
Аксиома показывает, как байесовские, объектно -центричные модели изучают полезную динамику в минутах (без градиентов), разъясняя, как активное вывод может масштабироваться за пределы контроля низкого уровня до понимания и планирования на уровне задач, и взаимодействовать с человеческими рассуждениями.
Почему это важно: бесшовная адаптация в реальном времени
Поскольку система построена из агентов, которые сами являются адаптивными учениками, робот не нуждается в исчерпывающем предварительном обучении для всех возможных вариаций. Он может:
- Адаптироваться на лету -Если объект тяжелее, чем ожидалось, агенты совместного уровня чувствуют напряжение и регулируют силу сцепления, в то время как агент высокого уровня обновляет свою веру в вес объекта для будущей обработки.
- Восстановиться от неудач -Если подзадача терпит неудачу (например, сбрасывание предмета), робот немедленно запланирует, не запустив всю задачу.
- Планируйте задачи с длинным хоризоном-Планировщик высокого уровня может динамически разложить цель на подзадачи, навыки секвенирования без необходимости изучать каждую возможную последовательность заранее.
Выплата: Результаты Robotic Habitat Robotic (At -A -Alance)
Активный вывод оказывается превосходным, адаптируясь в режиме реального времени, без офлайн-обучения.
Эталонные задачи (давняя хоризон, мобильные манипуляции): «Tidy House »,« Подготовьте продукты »и« Set Table ».
Активные выводы (ИИ) против подкрепления обучения (RL)
Успех/завершение (в среднем более 100 эпизодов):
- Аккуратный дом:72,5% (ИИ)против 71% (лучший RL -базовый уровень)
- Подготовьте продукты:77% (ИИ)против 64% (RL)
- Установить таблицу:50% (ИИ)против 29% (RL)
- Общий:66,5% (ИИ)против 54,7% (RL)
Тренировочное бремя (обучение базового подкрепления):~ 6400 эпизодов на задачу + 100 метров шагов за навык (7 навыков) для обучения.
Активный вывод: без автономного обучения; Навыки вручную на горстке эпизодов; адаптируется онлайн (навыки повторно/сочинять автономно).
Адаптация активного вывода:Восстанавливается после сбоев в подразделениях путем повторного планирования (альтернативные направления подхода, перемещение базового) без переподготовки.
Значение:Это первая демонстрация, которую полностью иерархическая архитектура активного вывода может масштабироваться для современных, давно -горизонских контрольных показателей и превзойти сильные базовые показатели RL в отношении успеха и адаптивности - без массивных автономных тренировок.
От одного робота до команд человека и мачин
Активные роботы вывода уникально подходят для объединения с людьми. Они разбираются в том, что это совместимо с нами, разделяя структуру здравого смысла: восприятие окружающей среды, прогнозирование результатов и корректировка действий, чтобы минимизировать неопределенность.

Вот что это значит на практике:
Безопасность через общую ситуационную осведомленность:Робот может поделиться своей внутренней 3D «картой убеждений» окружающей среды, включая области неопределенности, с его человеческим партнером в режиме реального времени. Если не уверен, безопасно ли пространство, эта неопределенность становится совместной точкой решения.
Безопасность через управление неопределенностью:Робот не просто действует; это рассчитывает уверенность. Если доверие низкая, он ищет ввод, паузы или адаптацию, снижая риск.
Жидкое разделение труда:Как бы двое людей могутЧитать намерения друг друга и отрегулироватьРоли динамически динамически, активный робот вывода может предвидеть, когда вести, когда следует следовать и когда получить контроль за безопасностью или эффективностью.
Адаптивная переключение ролей:Если робот видит человека, борящегося с задачей, он может захватить - или наоборот - без полного сброса.
В критических доменах, таких как производство, реакция на стихийные бедствия или здравоохранение,Это означает, что человек и робот могут действовать как истинные партнеры, каждое понимание, прогнозирование и адаптация к действиям другогобез жестких сценариев.

Сотрудничество человека и робота стало возможным с активным выводом:
Когда как люди, так и роботы работают по принципам активного вывода, синергия замечательная. Вот что происходит, когда у обеих сторон есть рассуждения и логические возможности:
- Взаимное прогнозное моделирование- Оба могут предвидеть действия другого и соответствующим образом скорректировать, что приведет к более плавному сотрудничеству.
- Общее ситуационное осознание- Оба отслеживают неопределенность, поэтому они могут сигнализировать, когда им нужны разъяснения или помощь.
- Контекстные переговоры: Решения не просто приняты начтоделать, но напочемуЭто лучшее действие в текущем контексте.
- Безопасность и эффективность: Логика позволяет обеим сторонам осознавать, когда действие имеет смысл для общей миссии, а не только их узкой роли.
- Естественное разделение задач-Люди могут справиться с стратегией высокого уровня, в то время как роботы обрабатывают точное выполнение, каждая из которых адаптируется в режиме реального времени к входу другого.
Когда одна сторона не имеет такой емкости, партнер по аргументации долженМикроубийствоНепомогательный партнер, создание задержек, ошибок и разочарования.
Как это масштабируется для команд, городов и мира: пространственной сети (HSTP +HSML)
Когда вы объединяете эту внутреннюю многоагентную роботизированную структуру сПространственный веб -протокол, Сотрудничество масштабируется за пределами одного робота. Эта внутренняя координация становится еще более мощной через HSTP и HSML. Команда роботов (или робот и человек) может действовать так, как если бы они были частью одного и того же организма, с общим осознанием целей, рисков и возможностей,Таким образом, знания, полученные одним агентом, могут сообщить всем остальным.
HSTP (протокол транзакции гиперпространства):Обеспечивает безопасный, децентрализованный обмен обновлениями веры/целей, ограничения и государственные обновления между распределенными агентами - будь то человек, робот или инфраструктура. Центральный мозг не требуется.
HSML (язык моделирования гиперпространства):Дает всем агентам общие семантические 3D -модели понимания окружающей среды/мест, объектов, задач и правил - поэтому каждый агент читает один и тот же план одинаково.
Результат: то же самое распространение убеждений, которое координирует локоть и колеса робота, может координировать двух роботов, координатор человека и умное средство мгновенно и безопасно.
Представьте себе робота для доставки в больницу, медсестру и интеллектуальную систему инвентаризации -все они работают так, как если бы они были частью одного скоординированного организма, делясь тем же контекстом миссии в режиме реального времени. Этот уровень связной совместимости между агентами и платформами является одним из самых глубоких красивых аспектов этого нового технологического стека.

Человек -махин объединяется на практике
Так как же это может выглядеть в реальном мире?
Авиационная земля OPS:
ТекущийRL-управляемые роботыТребовать сценарии непредвиденных обстоятельств для каждого отклонения от плана.
Активный роботНа протяженности багажная тележка, блокирующая залив, предсказывает волновые эффекты задержки и мгновенно ведет переговоры о новом порядке задания с человеческими руководителями-избегая задержек.
Ответ о бедствии:
RL Robotsможет обнаружить опасности, но часто не хватает рамки рассуждений, чтобы взвесить конкурирующие риски без переподготовки.
Активный роботВ разрушенном здании структурная нестабильность помечает уровень неопределенности и предлагает альтернативные маршруты поиска в сотрудничестве с человеческими респондентами.
Промышленная логистика:
На умной фабрике,Роботы, оснащенные активным выводом and VBGS mapping adapt to new conveyor layouts without reprogramming, while humans focus on production priorities.
Большая картина: аксиома, VBGS и пространственная сеть
Более широкий исследовательский стек стихов связывает это непосредственно с масштабируемым сетевым интеллектом:
- Аксиома -Единая модель активного вывода, которая работает в каждом масштабе, от совместного управления до многоагентной координации в разных сетях.
- Вариационное байестное распад (VBGS) -Метод неопределенности для создания трехмерных карт окружающей среды высокой точки зрения, необходимый для безопасной, общей ситуационной осведомленности в командах человека и мачин.
- Пространственный веб -протокол (HSTP + HSML) -Материал обмена данными, которая позволяет роботам и людям безопасно и в реальном времени обменять пространственно контекстуализированную информацию.
Вместе они формируют технический мост от одного робота в качестве товарища по команде до глобального сетевого, распределенных интеллектуальных систем, где каждый человек, робот и система могут сотрудничать через общее понимание мира.
Уровни взаимодействия, оптимизации, сотрудничества и совместной регуляции являются беспрецедентными и ошеломляющими.Каждая отрасль будет затронута этой технологиейПолемУмные городаПо всему миру оживится через эту технологию.
От «инструментов» до мышления товарищей по команде
Это не просто обновление робототехники - это сдвиг парадигмы.

Там, где роботы RL являются мощными, но хрупкими инструментами, активные роботы вывода являются товарищи по команде, способные работать в жидкой непредсказуемой реальности человеческой среды.
Это происходит прямо сейчас, и это меняет то, что мы можем ожидать от робототехники навсегда.
Вы не можете "не засвидетельствовать" это
Замечательные работы AI впервые показывают, что робот может развиваться за пределы нынешних ограничений обучения подкреплению (RL):
- От хрупких сценариев до самого затрат до агентов, которые могут рассуждать внутри себя и соответственно адаптироваться.
- От автономного переподготовки до онлайн -вывода и повторного планирования в данный момент.
- От непрозрачной политики до интерпретируемых мировых моделей неопределенности (VBGS, Axiom).
- И от «инструментов» до товарищей по команде, которыеПодумай с намиПолем
Это первая публичная демонстрация, которая масштабирует активные выводы для реальной сложности робототехники, одновременно превосходя текущие парадигмы по эффективности, адаптивности и безопасности - без нагрузки на данные и обслуживание обучения подкреплению.
Это первое публичное доказательство того, что активное вывод может масштабироваться в сложности реальных задач.
Стихи AI Research Stack сбрасывает бар для того, что мы должны ожидать от роботов в домах, больницах, аэропортах, фабриках и от команд, которые мы строим с ними.
Оригинал