

Проектирование системы ваттций: динамический кв-к.-кв с смежной виртуальной памятью
12 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
2.1 Модели больших языков
2.2 Фрагментация и Pagegataturation
3 проблемы с моделью Pagegatatturetion и 3.1 требуют переписывания ядра внимания
3.2 Добавляет избыточность в рамки порции и 3,3 накладных расходов
4 понимания систем обслуживания LLM
5 Vattument: проектирование системы и 5.1 Обзор дизайна
5.2 Использование поддержки CUDA низкого уровня
5.3 Служение LLMS с ваттенцией
6 -й ваттиция: оптимизация и 6,1 смягчения внутренней фрагментации
6.2 Скрытие задержки распределения памяти
7 Оценка
7.1 Портативность и производительность для предпочтений
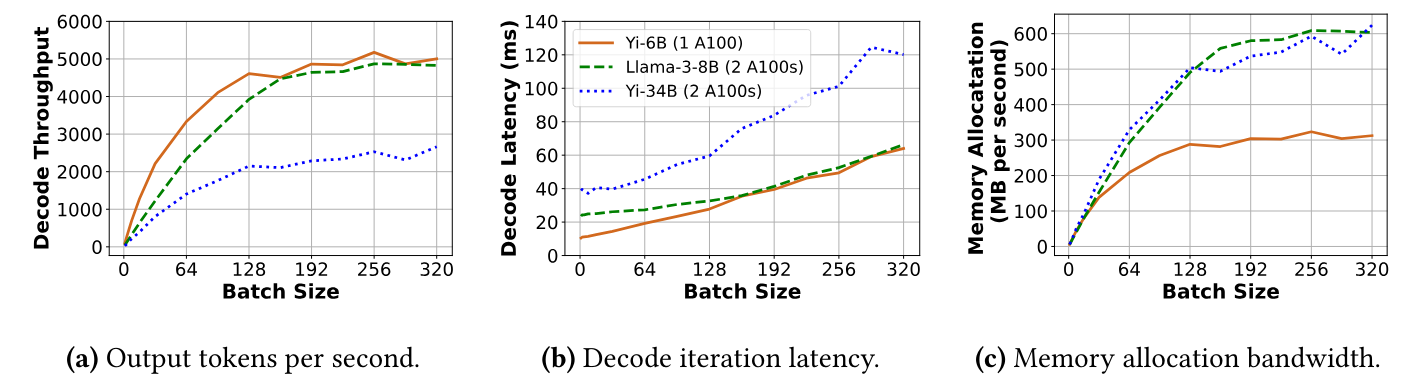
7.2 Портативность и производительность для декодов
7.3 Эффективность распределения физической памяти
7.4 Анализ фрагментации памяти
8 Связанная работа
9 Заключение и ссылки
5 Сравнение: дизайн системы
Наша цель - повысить эффективность и мобильность путем добавления поддержки динамического распределения памяти к существующим ядрам. Для достижения этой цели, ваттенция использует поддержку системы для
Динамическое распределение памяти вместо реализации пейджинг в пространстве пользователя.
5.1 Обзор дизайна
Vattument основана на способности распределять виртуальную память и физическую память отдельно. В частности, мы распределяем большой смежный буфер для кв-кэша в виртуальной памяти заранее (аналогично распределителям на основе резервации), одновременно откладывая распределение физической памяти во время выполнения, то есть, выделяем физическую память только при необходимости (аналогично PageDattuention). Таким образом, VATTUTION сохраняет виртуальную смелость KV-кэша, не теряя физической памяти. Этот подход осуществляется, потому что емкость и фрагментация памяти являются ограничивающими факторами только для физической памяти, тогда как виртуальная память в изобилии, например, современные 64-битные системы обеспечивают 128 ТБ виртуальное адресное пространство, управляемое пользователем, для каждого процесса [3].
5.1.1 Предварительная виртуальная память.Поскольку виртуальная память в изобилии, мы предварительно выделяем достаточно пространства виртуальной памяти, которое достаточно большое, чтобы удерживать KV-кэш максимального размера партии (настраиваемый), который необходимо поддерживать.
Количество буферов виртуальной памяти:Каждый слой в LLM поддерживает свои собственные k и v tensors: мы называем их индивидуально как k-cache и v-cache. Мы распределяем отдельные буферы виртуальной памяти для K-Cache и V-Cache. Для одного задания по графическому процессору требуется предварительно оставлять 2 × 𝑁 буферы, где 𝑁-количество слоев в модели. В задании с несколькими GPU каждый работник оставляет за собой 2 × 𝑁 ′ буферы, где 𝑁 ′-это количество слоев, управляемых этим работником (𝑁 ′ = 𝑁 с тензорным параллелизмом, тогда как 𝑁 ′ <𝑁 с параллелизмом трубопровода).
Размер буфера виртуальной памяти: максимальный размер буфера составляет 𝐵𝑆 = 𝐵 × 𝐿 × 𝑆, где B-максимальный размер партии, L-максимальная длина контекста, поддерживаемая моделью, а 𝑆-это размер для одного токена для одного токена (или V-кэш) на рабочем. Кроме того, 𝑆 = 𝐻 × 𝐷 × 𝑃, где 𝐻 - это количество голов кВ на работнике, 𝐷 - это размер каждой головки кВ, а 𝑃 - количество байтов, основанных на точности модели (например, P = 2 для FP16/BF16). Обратите внимание, что 𝑆 постоянно для данной конфигурации модели.
Рассмотрим yi-34b с FP16 и двусторонним тензорным параллелизмом (TP-2). В этом случае 𝑁 = 60, 𝐻 = 4, 𝐷 = 128, 𝑃 = 2 (головки yi-34B в 8 кВ распределяются равномерно на два графических процессора), а максимальная поддерживаемая длина контекста 𝐿 = 200𝐾. Для этой модели максимальный размер k-cache (или v-cache) для наработа на рабочую силу равен 𝑆 = 200𝑀𝐵 (200𝐾 ∗ 4 ∗ 128 ∗ 2). Предполагая 𝐵 = 500, максимальный размер каждого буфера для работника составляет 𝐵𝑆 = 100𝐺𝐵 (500 × 200𝑀𝐵). Следовательно, общее требование виртуальной памяти для 60 слоев YI-34B составляет 120 буферов по 100 ГБ каждый (всего 12 ТБ). Обратите внимание, что количество доступного виртуального адресного пространства растет с количеством графических процессоров, например, с двумя работниками ТП, количество доступного виртуального адресного пространства составляет 256 ТБ. Следовательно, распределение виртуальной памяти может быть легко выполнено.
5.1.2 по требованию распределение физической памяти.Веспочтно выделяет физическую память по одной странице за раз и только тогда, когда запрос использовал все свои ранее выделенные страницы физической памяти. Чтобы показать, как это работает, мы ссылаемся на простой пример на рисунке 7. Пример показывает, как Vattention управляет K-Cache (или V-Cache) на одном слое модели, предполагая максимальный размер партии двух. Остальные буферы k-cache и v-cache управляются аналогичным образом на всех слоях.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
[3] 64-битные системы обычно используют 48 бит для виртуальных адресов, обеспечивая пространство виртуальной памяти для каждого процесса 256 ТБ, которое в равной степени разделено между пространством пользователя и (OS) ядра.
Авторы:
(1) Рамья Прабху, Microsoft Research India;
(2) Аджай Наяк, Индийский институт науки и участвовал в этой работе в качестве стажера в Microsoft Research India;
(3) Джаяшри Мохан, Microsoft Research India;
(4) Рамачандран Рамджи, Microsoft Research India;
(5) Ашиш Панвар, Microsoft Research India.
Оригинал