
Использование слов для поиска мест в 3D -средах
16 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
Метод
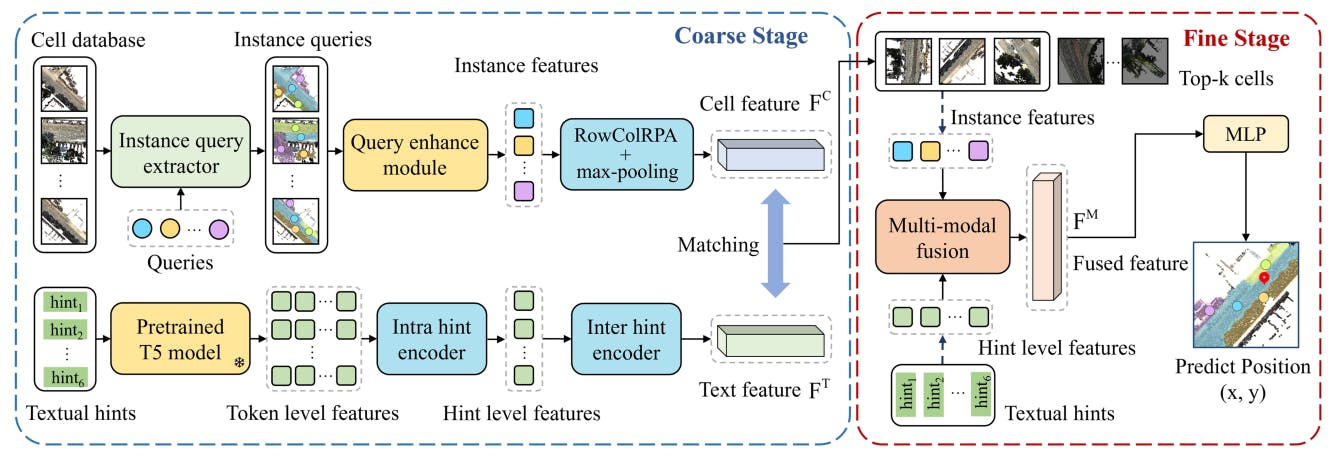
3.1 Обзор нашего метода
3.2 грубое извлечение текстовых клеток
3.3 Оценка прекрасной позиции
3.4 Цели обучения
Эксперименты
4.1 Описание набора данных и 4.2 Подробная информация
4.3 Критерии оценки и 4.4 результаты
Анализ производительности
5.1 Исследование абляции
5.2 Качественный анализ
5.3 Анализ встраивания текста
Заключение и ссылки
Дополнительный материал
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
2 Связанная работа
2.1 Признание 3D PLATE
Распознавание трехмерного места направлена на то, чтобы соответствовать изображению запроса или сканирования LIDAR локальной области с базой данных трехмерных облаков точек, чтобы определить местоположение и ориентацию запроса относительно эталонной карты. Этот метод может быть классифицирован на два подхода, то есть на основе плотной точки и на основе разреженного вокселя [46]. В частности, PointNetVlad [36] представляет собой основополагающую работу в потоке плотной точки, извлекая функции с помощью PointNet [29] и агрегирует их в глобальный дескриптор через Netvlad [2]. С появлением трансформатора [38] во многих исследованиях [12, 15, 25, 53] были использованы механизмы внимания, чтобы подчеркнуть значительные локальные особенности для распознавания места. Напротив, методы, основанные на вокселе, начинаются с воклизующих трехмерных облаков, повышающих надежность и эффективность. MinkLoc3d [22] извлекает локальные функции из разреженных вокселизованных точек, используя сеть пирамид, с последующим объединением с образованием глобального дескриптора. Тем не менее, вокселизация может привести к локальной потере информации. Управляя это, CASSPR [41] сочетает в себе вокселисные и точечные преимущества с двойным иерархическим трансформатором с двойной ветвью. Отрываясь от обычной зависимости облака точечных облаков, в нашем методе используются описания естественного языка, чтобы указать целевые местоположения, предлагая новое направление в 3D -локализации.
2.2 Языковая 3D-локализация
Языковая 3D-локализация направлена на определение позиции на городской карте 3D-точки в масштабе города на основе описания языка. Text2pos [21] пионерует это поле, разделяя карту на ячейки и используя грубую методологию, которая первоначально идентифицирует приблизительные местоположения посредством поиска и впоследствии уточняет оценку позы посредством регрессии. Крупный этап соответствует функциям и описанию ячейки и описания в общем пространстве встраивания, в то время как тонкая стадия проводит сопоставление функций на уровне экземпляра и вычисляет позиционные смещения для окончательной локализации. Тем не менее, этот метод упускает из виду отношения между подсказками и экземплярами облака точек. Управляя этот пробел, RET [39] включает в себя усиление к отношениям, чтобы анализировать как подсказки, так и экземпляры, и использует перекрестное взаимодействие в регрессии для улучшения многомодальной интеграции признаков. Text2loc [42] использует предварительно обученную языковую модель T5 [33] и иерархический трансформатор для улучшения текста, внедряющего и вводит бесплатный подход к тонкой локализации, используя каскадный трансформатор поперечного амортизации для превосходного мультимодального слияния. Используя контрастное обучение, Text2loc значительно превосходит существующие модели с точностью. Тем не менее, текущие методы зависят от экземпляров-территории земли в качестве входных данных, которые являются дорогостоящими для новых сред и не могут полностью использовать информацию о относительной позиции.
2.3 Понимание трехмерного видения и языка
В сфере 3D видения и понимания языка были достигнуты значительные шаги в внутренних сценариях [17, 44, 47, 48]. ScanRefer [5] и Refert3d [1] установите начальные тесты для трехмерного визуального заземления посредством выравнивания аннотаций объекта с описаниями естественного языка на сканете [11]. Последующее исследование [40, 45, 50] улучшают производительность, включив дополнительные функции, такие как функции 3D экземпляра, 2D-предварительные функции и анализируемые лингвистические функции для повышения производительности. Трехмерная плотная подвеска [7] подчеркивает подробное описание атрибутов объекта и также была уточнена путем интеграции различных методов трехмерного понимания [3, 6, 49]. И наоборот, наружный домен остается относительно неиспользованным, с большинством существующих наборов данных [20, 26, 28] полагаются на 2D -входы. Недавно набор данных TOD3CAP [18] приносит 3D плотную подпись в сценарии на открытом воздухе. Соответствующая модель использует 2D-3D-представления и объединяет соотношение Q-форматора с лама-адаптером [51] для получения подробных подписей для объектов. В отличие от существующих работ, мы сосредоточены на задаче локализации в масштабе от открытого города в масштабах текста до точки, стремясь преодолеть разрыв в 3D-видении на открытом воздухе и интеграции языка.
Авторы:
(1) Lichao Wang, FNII, Cuhksz (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNII и SSE, Cuhksz (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNII и SSE, Cuhksz (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE и FNII, Cuhksz (shuguangcui@cuhk.edu.cn);
(5) Чжэнь Ли, автор -соответствующий автор из SSE и FNII, Cuhksz (lizhen@cuhk.edu.cn).
Эта статья есть
Оригинал