

Использование LLMS для мутирования кода Java
4 июня 2025 г.Авторы:
(1) Бо Ван, Университет Пекин Цзиотонг, Пекин, Китай (wangbo_cs@bjtu.edu.cn);
(2) Mingda Chen, Пекинский университет Цзиотонга, Пекин, Китай (23120337@bjtu.edu.cn);
(3) Youfang Lin, Пекинский университет Цзиотонг, Пекин, Китай (yflin@bjtu.edu.cn);
(4) Майк Пападакис, Университет Люксембурга, Люксембург (michail.papadakis@uni.lu);
(5) Цзе М. Чжан, Королевский колледж Лондон, Лондон, Великобритания (jie.zhang@kcl.ac.uk).
Таблица ссылок
Аннотация и1 Введение
2 предыстория и связанная с ним работа
3 Учебный дизайн
3.1 Обзор и исследования исследований
3.2 Наборы данных
3.3 генерация мутаций через LLMS
3.4 Метрики оценки
3.5 Настройки эксперимента
4 Результаты оценки
4.1 RQ1: производительность по стоимости и юзабилити
4.2 RQ2: сходство поведения
4.3 RQ3: воздействие различных подсказок
4.4 RQ4: воздействие различных LLMS
4.5 RQ5: основные причины и типы ошибок некомпилируемых мутаций
5 Обсуждение
5.1 Чувствительность к выбранным настройкам эксперимента
5.2 Последствия
5.3 Угрозы достоверности
6 Заключение и ссылки
3.3 генерация мутаций через LLMS
Учитывая местоположение программы Java, мы извлекаем важную информацию (например, метод контекста или соответствующие модульные тесты), чтобы сформулировать подсказки, инструктирующие генерацию мутаций, а затем подают запросы к выбранному LLM. Как только LLM возвращает свои ответы, мы отфильтровываем мутации, которые являются некомпилируемыми, избыточными или идентичными исходному коду и возвращаем сгенерированные мутации. Как показано в разделе 3.4, наше исследование поддерживает комплексный набор метрик для оценки мутаций.
3.3.1 Модели.Мы стремимся всесторонне сравнить существующие LLMS в их способности генерировать мутации с различных точек зрения. Это включает в себя оценку возможностей моделей, которые настраиваются на различных базовых моделях, и контрастируют с производительностью коммерческих моделей с закрытым источником с альтернативами с открытым исходным кодом. В нашем исследовании мы выбираем LLMS на основе следующих критериев. (1) LLM должен иметь возможности кодирования, то есть понимание, генерирование и преобразование кода. (2) LLM должен поддерживать
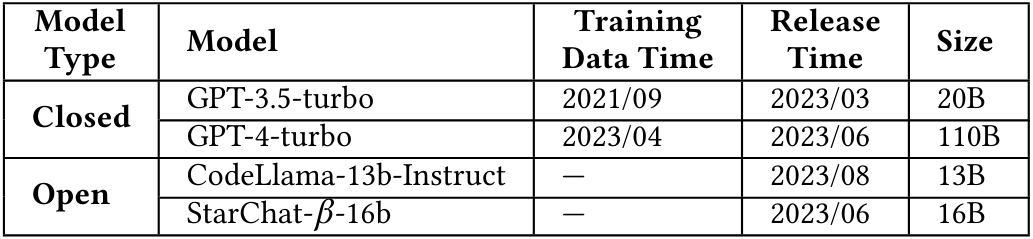
Взаимодействие в режиме чата, позволяющее преобразовать разговорное код. (3) LLM должен предлагать доступные API для интеграции.
Наконец, мы выбираем следующие модели: GPT-3.5-Turbo [4], GPT4-Turbo [4], Codellama-13b-Instruct [64] и Star кштат-16B [45]). Детали этих моделей показаны в таблице 2. Эти LLMS охватывают открытый исходный код (то есть Starchat и Codellama) и с закрытым исходным кодом (то есть GPT-3.5-Turbo и GPT-4-Turbo) и различные виды базовых моделей.
3.3.2 подсказки.Подсказки имеют решающее значение для LLM, поскольку они направляют ответы моделей и определяют направление сгенерированного вывода. Хорошо продуманная подсказка может значительно повлиять на полезность, актуальность и точность кода, созданного LLM. Этот подраздел представляет, как мы разрабатываем подсказки.
Чтобы разработать эффективные подсказки для генерации мутаций, мы следуем передовым методам, предполагаемым подсказки должны содержать четыре аспекта, а именно инструкции, контекст, входные данные и индикатор вывода [26, 49]. В инструкциях мы направляем LLMS генерировать мутанты для элемента целевого кода. В контексте мы четко указываем, что мутант является концепцией тестирования на мутации, и дополнительно предоставляем различные источники информации для наблюдения за эффективностью LLM, включая весь метод Java, окружающий элемент целевого кода и несколько выстрелов, выбранных из реальных ошибок из другого эталона. Во входных данных мы указываем элемент кода, который будет мутирован и количество мутантов для генерации. В выходном индикаторе мы указываем формат файла JSON для выходов мутаций, способствуя дальнейшим экспериментам. На рисунке 1 показан шаблон приглашения по умолчанию в нашем исследовании.
Кроме того, наши подсказки нуждаются в нескольких примерах, которые должны происходить из реальных ошибок, позволяющих LLMS научиться мутировать код из реальных ошибок. Это позволяет модели понимать контекст и логику, стоящие за изменениями, улучшая ее способность генерировать соответствующие и эффективные мутации.
Чтобы избежать нескольких примеров, протекающих информацию, помимо Defects4j и Cindefects, мы используем еще один эталонный базовый Quixbugs [47], который включает в себя 40 реальных жуков Java и обычно используется сообществом тестирования и отладки [35, 46, 83, 90, 91]. После существующего исследования по нескольким выстрелам [19] мы выбираем 6 ошибок из Quixbugs.
Чтобы гарантировать разнообразие примеров, мы случайным образом выбираем одну ошибку из набора данных и оцениваем, похож ли его шаблон модификации с уже собранными примерами. Если это отличается, мы добавляем его в нашу коллекцию и продолжаем, пока не соберем все 6 примеров. В таблице 3 показаны эти примеры.
Эта статья есть
Оригинал