

Разблокировка текстовых данных: путешествие новичка через Python, NLTK и Spacy
16 июля 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 виртуальный опыт обучения
3.1 The Team и 3,2 Обзор курса
3.3 Пилот 1
3.4 Пилот 2
4 обратная связь
4.1 Непрекращающаяся обратная связь
4.2 Подробная обратная связь студентов
5 уроков извлечены
6 Сводка и будущая работа, подтверждения и ссылки
A. Приложение: три звезды и желание
3 виртуальный опыт обучения
3.1 Команда
Наша команда состоит из трех ученых ранней карьеры в Эдинбургском университете. Два преподавателя имеют опыт работы в обработке естественного языка с кандидатами наук в области вычислительной лингвистики. Третий преподаватель имеет докторскую степень в области компьютерных наук и часто преподает программирование различным типам аудитории, включая студентов -бизнеса, а также студентов за пределами высшего образования. Список авторов в этом документе также включает четвертого (последнего) автора, который был участником нашего первого пилота, сама лектором, и который предоставил нам полезную обратную связь для будущих итераций этого курса (см. Раздел 4.2).
3.2 Обзор курса
В нашем обществе, управляемом данными, для людей, общественного, общественного и третьего секторов, все более важно знать, как анализировать богатство информационного общества создает каждый день. Наш курс TDM дает участникам, которые не имеют или очень ограниченного опыта кодирования инструменты, необходимые им для опроса данных. Этот курс предназначен для обучения некодеров тому, как анализировать текстовые данные, используя Python в качестве основного языка программирования. Он проходит через необходимые шаги, необходимые для того, чтобы проанализировать и визуализировать информацию в больших наборах текстовых сборов документов или корпорации.
Курс проходит в течение трех трехчасовых сессий, и каждая сессия знакомит участников с новой темой с короткой лекцией. Темы основываются на предыдущих сессиях, и в конце каждой сессии есть время для обсуждения и обратной связи. На первом сеансе мы начинаем с Python для чтения и обработки текста и учим, как отдельные документы загружаются и токенизированы. Мы работаем с простыми текстовыми файлами, но поднимаем проблему, что текстовые данные могут храниться в разных форматах. Однако, чтобы сделать вещи простыми, мы не рассказываем о других форматах подробно на практических сессиях.
Во втором сеансе мы показываем, как это делается с использованием гораздо больших наборов текста и добавляем визуализации. В качестве примеров мы использовали два набора данных: история болезни Британской Индии (из Шотландии, 2019), предоставленной Национальной библиотекой Шотландии [4] и первыми адресами всех американских президентов с 1789 по 2017 год. Мы показываем, как участники могут создавать списки согласования, распределения частот в корпорации и со временем, а также в области лексических распределений и в том, как они могут выполнять регуляторы. На этом сеансе мы также объясняем, что текстовые данные могут быть грязными, и что много времени может быть потрачено на очистку и подготовку данных таким образом, что это наиболее полезно для дальнейшего анализа. Например, мы указываем учащихся на остановленные слова и пунктуацию в результатах и объясняем, как их фильтровать при создании визуализаций на основе частоты.
Во время третьей сессии мы охватываем позы и названное признание организации. Эта последняя сессия завершается уроком визуализации текста и полученных данных с помощью выделения текста, частотных графиков, облаков слов и сетей (см. Некоторые примеры на рисунке 1). Основными инструментами NLP, используемыми для этого курса, являются NLTK 3 и Spacy, которые широко используются для исследований и разработок NLP. Здесь также мы помещаем некоторые материалы курса в контексте нашего собственного исследования, чтобы показать, как его можно применять на практике в реальном проекте. Например, мы упомянули нашу предыдущую работу по сбору темных наборов данных в Твиттере для дальнейшего анализа (Llewellyn et al., 2015), о геопарчизинном историческом и литературном тексту (Clifford et al., 2016; Alex et al., 2019a) и о названном распознавании Entity для радиологических отчетов (Alex et al., 2019b; Gorinski et al., 2019).
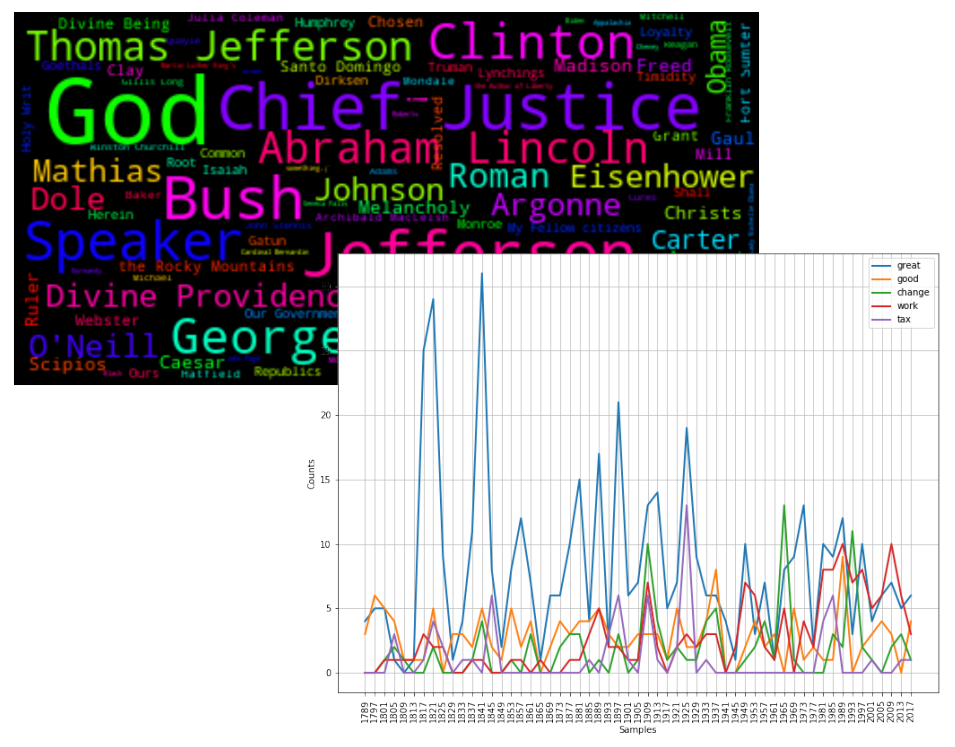
В двух пилотах мы провели этот курс в течение трех дневных сессий в понедельник, среду и пятницу, с офисным часом в промежуточные дни, чтобы разобраться в любых потенциальных технических проблемах и ответить на вопросы. Основным результатом обучения является то, что к концу курса участники приобрели первоначальные навыки TDM, которые они могут использовать в собственном исследовании и наращивавшись, пройдя более продвинутые курсы NLP или учебные пособия. Основная цель этого курса-учить материал четким шагом шагом, чтобы весь код Python и примеры были специфичны для каждой задачи, но не входили в подробные в сложных концепциях программирования, которые, как мы считаем, путают полные новички.
Авторы:
(1) Амадор Дуран, лаборатория баллов, институт I3US, Университет де Севилья, Севилья, Испания (amador@us.es);
(2) Пабло Фернандес, лаборатория баллов, институт i3us, Университет де Севилья, Севилья, Испания (pablofm@us.es);
(3) Беатрис Бернардес, Институт I3US, Университет де Севилья, Севилья, Испания (beat@us.es);
(4) Натаниэль Вайнман, Отдел компьютерных наук, Калифорнийский университет, Беркли, Беркли, Калифорния, США (nweinman@berkeley.edu);
(5) Асла Акалин, Отдел компьютерных наук, Калифорнийский университет, Беркли, Беркли, Калифорния, США (Asliakalin@berkeley.edu);
(6) Армандо Фокс, Отдел компьютерных наук, Калифорнийский университет, Беркли, Беркли, Калифорния, США (Fox@berkeley.edu).
Эта статья есть
[4] https://data.nls.uk/ Data/Digitised-Collections/A-medical-history-ofbritish-india/
Оригинал