

Архитектура блока трансформаторов: внимание и интеграция с подачей
19 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 модели и 3.1 ассоциативные воспоминания
3.2 трансформаторные блоки
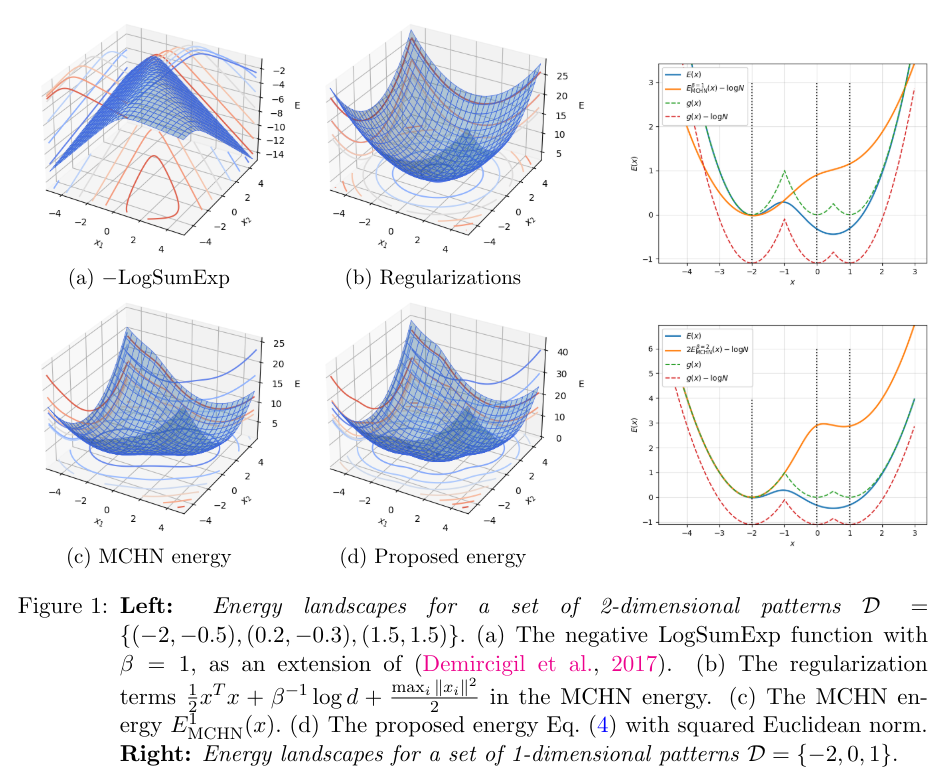
4 Новая энергетическая функция
4.1 Слоистая структура
5 Потеря по перекрестной энтропии
6 Эмпирические результаты и 6.1 Эмпирическая оценка радиуса
6.2 Обучение GPT-2
6.3 Тренировка ванильных трансформаторов
7 Заключение и подтверждение
Приложение A. отложенные таблицы
Приложение B. Некоторые свойства энергетических функций
Приложение C. отложенные доказательства из раздела 5
Приложение D. Трансформатор Подробности: Использование GPT-2 в качестве примера
Ссылки
3.2 трансформаторные блоки
Трансформеры (Vaswani et al., 2017) изготовлены из стопки гомогенных слоев, где каждый состоит из подслойного мультиголового внимания, подслойного подсловия, операции Add-Norm с подключением Skip и нормализации слоя. В качестве примера типичного трансформатора архитектура GPT-2 обсуждается в Приложении D. Многоугольные слои внимания и обработки (FF) учитывают большинство параметров в модели.

Наблюдение 2Слой внимания и слой подачи могут быть концептуально интегрированы в унифицированный слой трансформатора.
Слои внимания и слои FF способствуют большинству параметров модели, так что количество параметров N пропорционально квадрату измерения встраивания. Соотношение зависит от количества слоев и скрытых размеров
блоки трансформатора. В текущей работе мы не рассматриваем другие модификации, такие как боковые соединения, подключения к пропуску или другие модули сжатия, такие как (Xiong et al., 2023; Fei et al., 2023; Munkhdalai et al., 2024).
Авторы:
(1) Xueyan Niu, Theory Laboratory, Central Research Institute, 2012 Laboratories, Huawei Technologies Co., Ltd.;
(2) Бо Бай Байбо (8@huawei.com);
(3) Lei Deng (deng.lei2@huawei.com);
(4) Вэй Хан (harvey.hanwei@huawei.com).
Эта статья есть
Оригинал