

На пути к целостной оценке LLM: интеграция обратной связи с людьми с традиционными метриками
2 августа 2025 г.Абстрактный
Статья выступает за более комплексный метод оценки для крупных языковых моделей (LLMS) путем объединения традиционных автоматизированных метрик (Bleu, Rouge и недоумения) со структурированными отзывами человека. Он подчеркивает ограничения стандартных методов оценки, при этом подчеркивая критическую роль человеческих оценок в определении контекстуальной значимости, точности и этической целесообразности. С помощью подробных методологий, практических примеров реализации и тематических исследований в реальном мире, статья иллюстрирует, как целостная стратегия оценки может повысить надежность LLM, лучше выравнивать модель с ожиданиями пользователей и поддержать ответственность разработки ИИ.
1 Введение
Домен приложения искусственного интеллекта претерпел фундаментальную трансформацию из-за крупных языковых моделей (LLM), включая GPT-4, Claude, Gemini и другие модели. Обширное использование этих моделей требует полной оценки с помощью комплексных методов оценки. Оценка этих моделей зависит главным образом от автоматизированных метрик, которые включают Bleu, Rouge, Meteor и недоумение. Результаты исследований показывают, что автоматические показатели оценки не могут точно прогнозировать удовлетворенность пользователей и эффективность модели. Полная структура оценки требует комбинации обратной связи человека с традиционными показателями для оценки. Эта статья демонстрирует полный метод оценки эффективности LLM путем объединения количественных показателей с оценкой обратной связи человека. В этой статье рассматриваются существующие ограничения метода оценки при объяснении значения обратной связи человека и представляют подходы интеграции с практическими примерами и иллюстрациями кода.
2 ограничения традиционных метрик
Традиционные показатели служили стандартизированными критериями для более ранних систем НЛП, однако они не измеряют семантическую глубину, контекстуальную уместность и творческие возможности, которые определяют современные LLM. Традиционные показатели для оценки LLM в основном включают в себя:
- Bleu (двуязычная оценка занедрение) (Papineni, Roukos, Ward & Zhu, 2002)Блю
- Rouge (отзыв, ориентированный на отзыв, для расстояния оценки) (LIN)Руж
- Метеор (метрика для оценки перевода с явным упорядочением)
- Недоумение
Метрики оценки предоставляют полезную информацию, но у них есть несколько недостатков:
- Отсутствие контекстного понимания:Bleu и аналогичные показатели измеряют сходство токенов, но они не могут оценить контекстуальное значение сгенерированного текста.
- Плохая корреляция с человеческим суждением:Высокие автоматические оценки не обязательно приводят к высокой удовлетворенности пользователей в соответствии с человеческим суждением.
- Нечувствительность к нюансу и творчеству:Эти показатели оценки не могут обнаружить нюансированные или творческие результаты, которые остаются необходимыми для практических применений.
Метрики оценки LLM - BLEU, ROUGE, NERPLEXITY и точность - были разработаны для конкретных задач NLP, но не отвечали требованиям моделей современного языка. Оценки IBM Bleu демонстрируют слабую связь с оценкой человека (0,3-0,4 для творческих задач), а корреляция Rouge варьируется от 0,4-0,6 на основе сложности задачи. Метрики демонстрируют семантическую слепоту, потому что они измеряют перекрытие слова на уровне поверхности вместо обнаружения семантической эквивалентности и достоверных перефразов. (Клемент, 2021)Clementbm, (Dhungana, 2023)Оценка модели НЛП, (Mansuy, 2023)Оценка моделей НЛП
Смущение сталкивается с теми же проблемами, что и другие показатели, несмотря на общее применение. Определенность метрики на размер словарного запаса и длину контекста создает ненадежные перекрестные сравнения, и его сосредоточение на вероятности прогнозирования токена не измеряет качество генерируемого контента. (IBM, 2024)IBMПолем Исследования показывают, что модели с более низкими показателями недоумения не генерируют более полезные или точные или безопасные результаты, объясняя разрыв между целями оптимизации и утилитой реальной жизни. (Деванш, 2024)Середина
Система оценки имеет множество ограничений, которые влияют как на отдельные показатели, так и основные предположения об оценке. Традиционные методы оценки зависят от идеальных стандартов золота и единичных правильных ответов, но они не рассматривают субъективную природу задач генерации языка (Devansh, 2024)СерединаПолем Bertscore и Bleurt, хотя они используют нейронные встраивания для захвата семантического значения, все еще испытывают трудности с антонимами, отрицаниями и контекстуальной тонкостью (Oefelein, 2023)SaturncloudПолем Исследование демонстрирует, что передовые автоматизированные метрики не могут полностью измерить сложность человеческого языка. Недавние достижения в области нейронных метрик попытались решить эти проблемы (Bansal, 2025)Analyticsvidhya(Sojasingarayar, 2024)СерединаПолем Xcomet достигает современной производительности в разных типах оценки с его мелкозернистыми возможностями обнаружения ошибок. Сжатая версия Xcomet-Lite поддерживает качество 92,1%, используя только 2,6% исходных параметров. Улучшения функционируют в пределах автоматических ограничений оценки, которые требуют обратной связи человека для полной оценки (Guerreiro, et al., 2024)MIT Press, (Ларионов, Селезнов, Вишков, Панченко и Эгер, 2024)Антология ACLПолем
2.1 Пример ограничения:
Ожидаемый ответ на вопрос «Описать ИИ» должен быть:
«Моделирование процессов человеческого интеллекта через машины определяет ИИ».
LLM генерирует инновационный ответ на вопрос:
«Сила ИИ превращает машины в мышления сущности, которые учатся и адаптируются аналогично людям».
Традиционные методы оценки дадут этот ответ более низкий балл, даже если он имеет большую практическую ценность.
3 Важность обратной связи человека
Обратная связь с человеком подключается к автоматическим пробелам оценки путем непосредственной оценки полезности и ясности и творчества, а также фактической правильности и безопасности генерируемых выходов. Ключевые преимущества включают:
- Контекстуальное понимание:Люди оценивают, имеют ли ответы логическим смыслом в данных контекстах.
- Практическая значимость:Непосредственно оценивает удовлетворенность пользователями.
- Этическое выравнивание:Оценивает этические последствия, смещения и уместность генерируемых результатов.
Оценка обратной связи с человеком требует результатов оценки на основе качественных критериев оценки.
Показатель | Описание |
|---|---|
Точность | Правильная предоставленная информация? |
Актуальность | Вывод выровняется с намерением пользователя? |
Ясность | Информация четко сообщена? |
Безопасность и этика | Это избегает предвзятых или неуместных ответов? |
4 Интеграция обратной связи человека с традиционными метриками
Сочетание автоматической оценки с обратной связью с человека в недавних исследованиях показывает выравнивание предпочтений на уровне 85-90%, в то время как традиционные метрики только достигают всего 40-60% в соответствии с (Pathak, 2024)Красная шляпа, который преобразует наши текущие методы оценки эффективности искусственного интеллекта. Новый подход демонстрирует, как LLM нуждаются в рамках оценки, которые оценивают точность вместе с когерентностью и безопасностью, справедливостью и выравниванием ценности человека. Эффективная оценка композитов LLM требует комбинации автоматических методов с субъективными аннотациями. Можно предусматривать сильное решение, как показано на рисунке 1
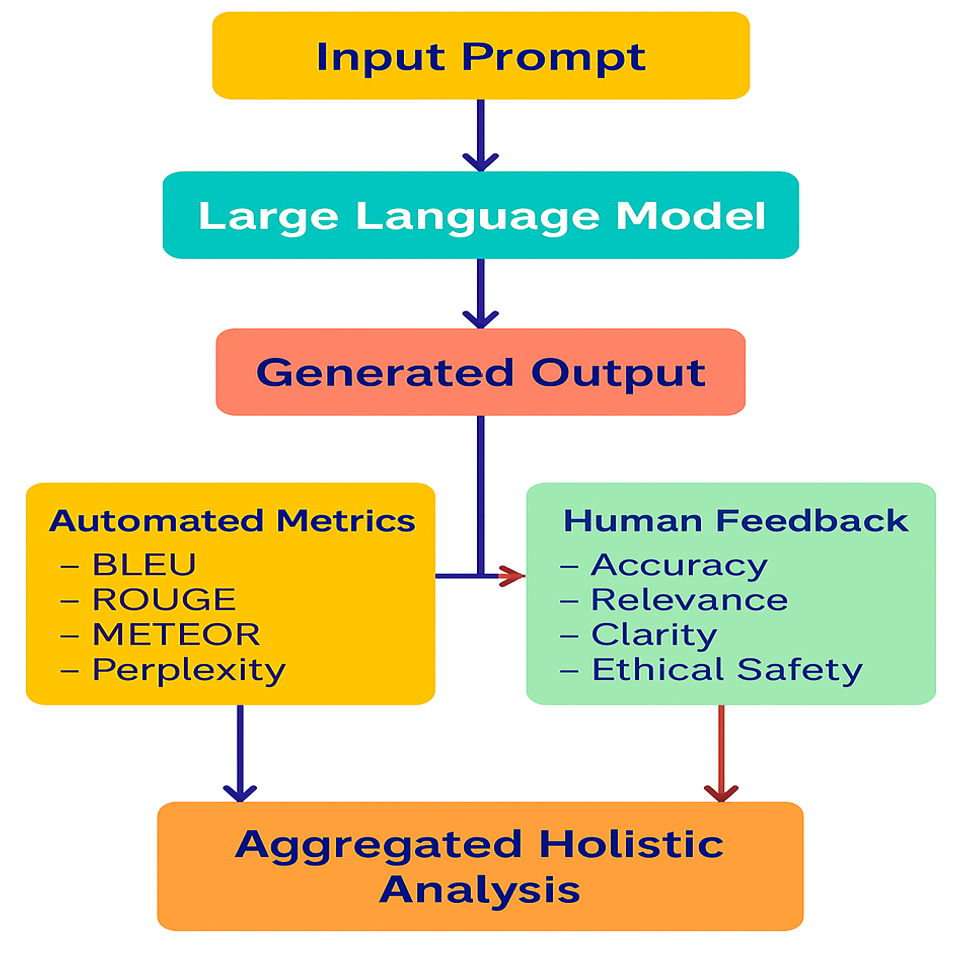
Переход от автоматизированной оценки к интегрированным человеку подходов выходит за рамки методологического улучшения, поскольку он решает основные проблемы в нашем нынешнем понимании эффективности искусственного интеллекта. Появление подкрепления обучения от обратной связи с человеком (RLHF) и конституционного искусственного интеллекта и предпочтений, обучения, представляют новые методологии оценки, которые сосредоточены на человеческих ценностях и реальной применимости вместо узких показателей эффективности (Dupont, 2025)Лейблвизор, (Atashbar, 2024)МВФ Элибрир, (Huyen, 2023)RlhfПолем
RLHF достигает выдающейся эффективности за счет обучения моделей параметров 1,3B с обратной связью с человеческой, которая превосходит базовые модели параметров 175B, одновременно оптимизируя выравнивание для достижения 100 -кратной эффективности параметров (Lambert, Castricato, Werra, & Havrilla, 2022)Обнимающееся лицоПолем Система функционирует на трех последовательных этапах, которые включают в себя контролируемую тонкую настройку с последующим обучением модели вознаграждения от предпочтений человека и оптимизации обучения подкреплением посредством оптимизации проксимальной политики (PPO) (Dupont, 2025)Лейблвизор, (Huyen, 2023)RlhfПолем
Методология работает эффективно, потому что она обнаруживает тонкие человеческие предпочтения, которые стандартные метрики не могут обнаружить. Оценка человека демонстрирует, что модели, выравниваемые RLHF, получают 85%+ оценки предпочтений выше базовых моделей, демонстрируя значительные улучшения в полезности, безвредности и честности. Процесс обучения модели вознаграждения использует пар человеческих предпочтений 10K-100K для разработки масштабируемых предикторов предпочтений, которые прямая модельная поведение без необходимости оценки человека для каждого вывода (Lambert, Castricato, Werra, & Havrilla, 2022)Обнимающееся лицоПолем
Реализация систем человека в петле (HITL) устанавливает динамические рамки оценки через человеческое суждение, которое направляет автоматизированные процессы. Эти системы достигают на 15-25% улучшения производительности конкретной задачи, снижая при этом риски безопасности на 95%+, работая за счет интеллектуальной маршрутизации задач, которая усиливает неопределенные или потенциально вредные результаты для людей. Метод демонстрирует наилучшие результаты в специализированных областях юридического обзора и медицинской диагностики, потому что AI предварительно скрининг с последующей проверкой экспертов производит эффективные и строгие оценочные трубопроводы. (Серо -серой, 2023)Середина, (Specannotate, 2025)Speernonotate, (Оливера, 2024)Середина

4.1 Практическая реализация (с примером кода)
Основная структура для интеграции обратной связи с человеком с автоматизированными метриками может быть реализована через код Python.
Шаг 1: Вычисление автоматических метрик.
from nltk.translate.bleu_score import sentence_bleu
from rouge import Rouge
reference = "AI simulates human intelligence in machines."
candidate = "AI brings intelligence to machines, allowing them to act like humans."
#Calculate BLEU Score
bleu_score = sentence_bleu([reference.split()], candidate.split())
#Calculate ROUGE Score
rouge = Rouge()
rouge_scores = rouge.get_scores(candidate, reference)
print("BLEU Score:", bleu_score)
print("ROUGE Scores:", rouge_scores)
Вывод для выше
Bleu Score:1.1896E-231 (≈ 0)
Rouge Score : [
{
"rouge-1": {
"r": 0.3333333333333333,
"p": 0.2,
"f": 0.24999999531250006
},
"rouge-2": {
"r": 0.0,
"p": 0.0,
"f": 0.0
},
"rouge-l": {
"r": 0.3333333333333333,
"p": 0.2,
"f": 0.24999999531250006
}
}
]
Эти результаты выделяют:
- Бритлей Блю: почти нулевой из -за отсутствия 4 грамма, что означает очень плохое в каждом измерении.
- Rouge-1 и Rouge-LЗахватить базовое совпадение (Unigrams/LCS), но Rouge-2-это нулевое, поскольку нет подходящих биграм.
Шаг 2: Интеграция отзывов человека
Предположим, что у нас есть оценщики человека, набирающие одинаковый результат кандидатов:
#Human Feedback (Collected from Survey or Annotation)
human_feedback = {
'accuracy': 0.9,
'relevance': 0.95,
'clarity': 0.9,
'safety': 1.0 }
#Aggregate human score (weighted average)
def aggregate_human_score(feedback):
weights = {'accuracy':0.3, 'relevance':0.3, 'clarity':0.2, 'safety':0.2}
score = sum(feedback[k]*weights[k] for k in feedback)
return score
human_score = aggregate_human_score(human_feedback)
print("Aggregated Human Score:", human_score)
В выход
Агрегированный человек: 0,935
Совокупный человек0,935Указывает, что ваш выход LLM получает чрезвычайно высокие оценки от реальных людей, которые превышают типичные «хорошие» пороги и делают его подходящим для большинства практических применений или публикации с лишь незначительными корректировками для почти совершенного выравнивания.
Шаг 3: Целостная агрегация
Объединить автоматические и человеческие оценки:
#Holistic Score Calculation
def holistic_score(bleu, rouge, human):
automated_avg = (bleu + rouge['rouge-l']['f']) / 2
holistic = 0.6 * human + 0.4 * automated_avg
return holistic
holistic_evaluation = holistic_score(bleu_score, rouge_scores[0], human_score)
print("Holistic LLM Score:", holistic_evaluation)
Вывод для выше
Целостная оценка LLM:0,6109999990625
Целостный балл LLM 0,6109999990625отражает взвешенную смесь:
- Автоматизированный показательS (Bleu & Rouge-L в среднем) 40% веса
- Агрегированный человек- 60% веса. Оценка ~ 0,611 требует объяснения, а также руководство о том, как продолжить.
4.1.1. Как был рассчитана оценка
- Человеческий балл (0,935)имел вес 60%, что означает, что он внес 0,561 до окончательного балла.
- Средний балл автоматическогорассчитывали путем принятия среднего уровня Bleu ≈0 и Rouge LF1 ≈0,2478, что равняется 0,1239, и этот показатель составлял 40%, что означает, что он внес 0,0496 до окончательного балла.
- Общий баллПриблизительно 0,6109999, когда он округлен до 0,6106.
4.1.2. Интерпретация 0,611 по шкале 0–1
- Уровень производительности будет считаться «плохим», когда оценка падает ниже 0,5.
- Модель получает высокие оценки человека, но жесткие лексические метрики оценивают ее на нижней части диапазона, когда оценка падает от 0,5 до 0,7.
- Большинство приложений считают оценки выше 0,8 как «сильно приемлемые».
Оценка 0,611Поместите вас в умеренный диапазон.
- Выход получил высокую похвалу от оценщиков человека за точность, актуальность, ясность и безопасность.
- Автоматизированные метрики сильно оштрафовали выход, потому что у него было низкое точное перекрытие N-грамма.
4.1.3. Почему гибридный счет ниже, чем человеческий счет
- Автоматизированный компонент получает оценку 0, потому что Bleu не имеет 4-граммового перекрытия.
- Оценка Rouge-L F1 0,2478 также довольно низкая по той же причине.
- Оценка человека 0,935 не предотвращает автоматизированный срез 40% от снижения общего балла до приблизительно 0,61.
4.1.4. Практические выводы
Впервые доверяйте человеческому рейтингу
- Человеческий балл указывает на качество содержания в его конкретном контексте.
- Ваше текущее внимание на удовлетворенности пользователей указывает на то, что вы уже достигаете своих целей.
Решите свой порог
- Ваши автоматизированные метрики требуют улучшения, даже если ваш порог готовности к производствуявляется ≥0,7Полем
- Ваши автоматизированные задачи готовы к развертыванию, когда их оценки достигают0,6или выше, независимо от их природы.
Улучшить автоматические оценки
- Лексическое перекрытие:Повторно используйте больше эталонной формулировки или добавьте синонимы, которые соответствуют ее.
- Сглаживание:Для Bleu попробуйте сгладить функции (например, сглаживание функции. Method1), чтобы избежать нулевых результатов. o Семантические метрики: рассмотрите обмен или увеличение Bleu/Rouge с помощью Bertscore или Bleurt, что лучше захватывает значение.
- Семантические метрики:Рассмотрим обмен или увеличение Bleu/Rouge с помощью Bertscore или Bleurt, что лучше захватывает значение.
Регулируйте взвешивание (при необходимости)
Вы можете уменьшить автоматический вес (например, 30% Auto /70% человека), если вы больше доверяете обратной связи для человека для вашего случая использования.
5 Недавних исследований достигают целостных структур оценки
В течение 2023-2025 гг. Исследователи разработали полные рамки оценки для LLMS, которые посвящены сложным аспектам эффективности языковой модели. Целостная оценка структуры языковых моделей (Helm) достигла 96% улучшения охвата по сравнению с предыдущими оценками, поскольку исследователи из Стэнфорда оценили 30+ заметных моделей в 42 сценариях и 7 ключевых показателях, включая точность, калибровку, надежность, справедливость, смещение, токсичность и эффективность. (Стэнфорд, н.д.)СтэнфордПолем
Система оценки Prometheus и ее преемник Prometheus 2 представляют серьезные достижения в области технологии оценки с открытым исходным кодом. Prometheus 2 демонстрирует 0,6-0,7 корреляции Пирсона с соглашением GPT-4 и 72-85% с судьями человека, что обеспечивает прямую оценку и парное рейтинг. Структура предлагает доступные альтернативы системы оценочной системы со стандартами производительности, которые соответствуют ведущим коммерческим решениям (Kim, et al., 2023)Корнелл, (Liang, et al. 2025)OpenReview, (Wolfe, 2024)ПодмазочныйПолем
Структура G-eval реализует рассуждения о цепочке мыслей для оценки процессов посредством заполнения форм парадигм для показателей, специфичных для задачи. Структура обеспечивает лучшие показатели выравнивания человека, чем традиционные метрики в соответствии с уверенным ИИ, поскольку прозрачная оценка, основанная на рассуждениях, показывает сложные аспекты генерации языка, которые автоматизированные метрики не обнаруживают. Метод оценки обеспечивает исключительные преимущества для задач, которые требуют многочисленных шагов рассуждений или захвата творческого вывода (Wolfe, 2024)Подмазочный, (IP, 2025)Уверенный ИИПолем Разработка методов оценки, специфичных для домена, демонстрирует, как эксперты теперь понимают, что инструменты оценки общего назначения не измеряют специализированные приложения должным образом. Finben предоставляет 36 наборов данных, которые охватывают 7 финансовых областей и агрегирует ориентированные на здравоохранение контрольные показатели, чтобы обеспечить точную оценку возможностей для конкретных доменов. Очевидно, что эти рамки включают в себя специализированные требования к знаниям и профессиональные стандарты, которые не могут (Zhang et. Al, 2024)Корнелл, (Jain, 2025)СерединаПолем
Стандартный эталон MMLU-PRO направлен на 57% частоту ошибок, обнаруженную в оригинальном эталонном эталоне MMLU посредством проверки экспертов и увеличения сложности из-за 10-х ответов. Рост поля приводит к постоянной разработке стандарта оценки, которая выявляет проблемы в современных контрольных системах.
6 вариант использования в реальном мире:
6.1 Оценка CHATGPT
OpenAI использует подкрепление обучения от обратной связи человека (RLHF) для улучшения моделей GPT. Оценщики человека оценивают выходы модели, а предоставляемые ими оценки используются для обучения модели вознаграждения. Комбинация этих методов привела к улучшению 40% в фактической точности по сравнению с GPT-3.5, практическим удобством использования и модельными ответами, которые соответствуют ожиданиям человека, что приводит к гораздо лучшему пользовательскому опыту, чем только автоматизированная оценка. Они используют непрерывный мониторинг посредством отзывов пользователей и автоматической безопасности. (Opeinai, 2022)OpenaiПолем
6.2 Microsoft Azure AI Studio
Azure AI Studio из Microsoft интегрирует инструменты оценки непосредственно в свою облачную инфраструктуру, которая позволяет пользователям тестировать приложения в автономном режиме перед развертыванием и мониторинг их онлайн во время производства. Платформа использует метод гибридной оценки, который объединяет автоматизированные оценщики с валидацией человека в петле, чтобы помочь предприятиям сохранить стандарты качества во время масштабирования приложений. Система быстрого потока от их компании позволяет пользователям оценивать сложные современные приложения ИИ с помощью многоэтапной оценки рабочего процесса (Dilmegani, 2025)AimultipleПолем
6.3 Google Vertex AI
Система оценки Google Vertex AI демонстрирует разработку мультимодальной оценки, которая оценивает производительность между текстами, модальностями изображения и аудио. Их методология иглы в сбоке для оценки с длинным контекстом стала отраслевым стандартом, что позволило масштабируемой оценке способности моделей получать и использовать информацию из обширных контекстов. Подход оказался особенно ценным для приложений, требующих синтеза информации из нескольких источников (Dilmegani, 2025)AimultipleПолем
6.4 Другие тематические исследования
Коммерческая оценка ландшафт значительно расширилась, с такими платформами, как HumanLoop, Langsmith и Braintrust, предлагающие сквозные решения для оценки. Эти платформы обычно достигают сокращения затрат на 60-80%по сравнению с разработкой пользовательской оценки, обеспечивая предварительно построенные показатели, рабочие процессы аннотации человека и возможности мониторинга производства. Альтернативы с открытым исходным кодом, такие как Deepeval и Langfuse, демократизируют доступ к сложным инструментам оценки, поддерживая более широкое принятие лучших практик в отрасли (IP, 2025)Конфиденциальность, (Labelbox, 2024)МеткаПолем Практические эффекты сильных структур оценки демонстрируются в рамках тематических исследований в области реализации здравоохранения. Исследование Mount Sinai показало 17-кратное снижение затрат API за счет группировки задач, одновременно обрабатывая до 50 клинических задач без потери точности. Это демонстрирует, как вдумчивый дизайн оценки может достичь как целей, так и целей эффективности в производственных средах (IP, 2023)DevCommunityПолем
Техническое развитие прямого оптимизации предпочтений (DPO) устраняет требование для явного обучения модели вознаграждения. Классификационный подход DPO превращает RLHF в классификационную задачу, которая приводит к ускорению обучения в 2-3 раза без ущерба для качественных показателей. Система DPO достигает 7,5/10 производительности на MT-Bench, в то время как RLHF достигает 7,3/10 и достигает 85% -ного уровня выигрыша на Alpacaeval по сравнению с 82% для традиционного RLHF, сокращая время обучения с 36 часов до 12 часов для эквивалентной производительности (Spemannotate, 2024).Speernonotate, (Werra, 2024)Объятие, (Wolfe, 2024)ПодмазочныйПолем
7 Альтернативный подход:
Конституционный ИИ, разработанный Anpropric, предлагает альтернативный подход, который снижает требования к аннотации человека на 80-90% при сохранении сопоставимой производительности. Структура использует обратную связь с ИИ, а не человеческие этикетки с помощью двухфазного процесса: контролируемое обучение с самокритикой и пересмотром, сопровождаемое подкреплением от обратной связи с ИИ (RLAIF). Этот подход достигает снижения вредных результатов на 90%+ при сохранении 95%+ выполнения задач, демонстрируя, что системы ИИ могут научиться соответствовать человеческим ценностям посредством структурированного самосовершенствования (Anpropic, 2022)АнтропПолем
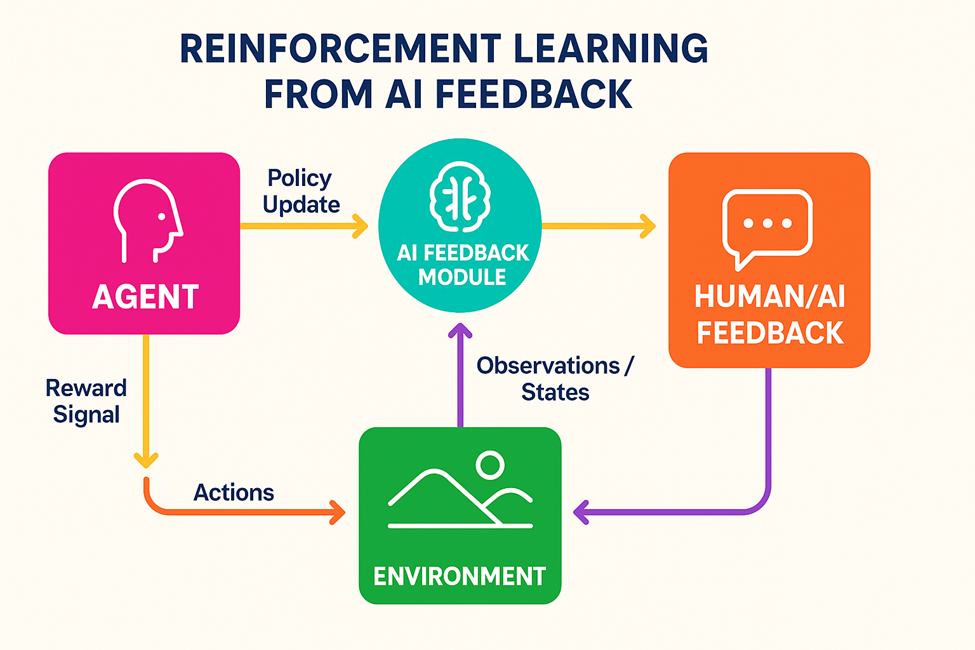
8 проблем и будущих направлений
8.1 Проблемы:
- Масштабируемость: Процесс сбора большого количества обратной связи с человеком оказывается как дорогим, так и трудоемким. Расходы на оценку человека охватывают от 50 до 200 долларов США в час для экспертных рецензентов, что делает обширную оценку недоступной для многочисленных организаций. Процесс качественной оценки человека зависит от опыта домена и последовательной подготовки и постоянной калибровки, которая увеличивает сложность и стоимость процессов оценки. Соглашение между различными аннотаторами показывает широкие различия, потому что сложность задачи влияет на их коэффициенты корреляции, которые варьируются от 0,4 до 0,8 (10pearls, n.d.)10pearls, (Dilmegani, 2025)AimultipleПолем
- Предвзятость и изменчивость: Человеческие оценщики приносят как противоречивые результаты, так и личные предрассудки в процесс оценки. Исследования показывают, что 91% LLM участвуют из данных, затраченных на веб-режиссер, которые содержат недопредставленность женщин в 41% профессиональных контекстов, и эти предубеждения продолжают распространяться через системы оценки. Методология оценки создает предвзятость посредством эффектов порядка и предпочтений длины, а также демографических предположений и культурных перспектив, которые требуют систематических стратегий смягчения, которые во многим организациям не хватает необходимых ресурсов для эффективного реализации (Rossi et al., 2024)Mitpress, (Barrow et al., 2023)КорнеллПолем
- Отсутствие наземной истины в открытом поколении:Отсутствие основной истины для задач открытого поколения делает «правильную» по своей сути субъективной и зависимой от контекста, создавая сценарии оценки, в которых существуют множество достоверных ответов без четких критериев ранжирования. Эта двусмысленность особенно влияет на творческие задачи, разговорные ИИ и специфичные для области приложения, где требования к опыту превышают общие возможности оценки (Huang et al., 2023)КорнеллПолем
- Проблемы с интеграцией автоматизированной и человеческой оценки:Организации должны выполнить обширную калибровку, чтобы определить надлежащие пороги для триггеров обзора человека автоматизированных систем, в то время как им нужны установленные протоколы для разрешения конфликтов между автоматизированными и результатами оценки человека. Практическая реализация рабочих процессов оценки сталкивается с постоянными проблемами из -за сложности создания единых систем, которые интегрируют различные подходы со стандартами качества.
9 Будущие направления:
- Реализация методов активного обучения поможет уменьшить требование для оценки человека.
- Использование вторичных моделей ИИ, обученных данным обратной связи человека, позволяет автоматизировать качественные оценки, которые имитируют оценки человека.
- Будущее методологии оценки будет зависеть от контекстных методов, которые изменяют критерии оценки в соответствии с требованиями задач, потребностями пользователей и областям приложений. Эти методы направлены на решение текущей проблемы стандартизированных структур оценки, которые не могут обнаружить широкий диапазон приложений LLM.
- Разработка единых подходов к оценке, которые могут оценить межмодальную согласованность и согласованность, станет все более важной, поскольку LLMS интегрируется с другими системами искусственного интеллекта для создания более способных и универсальных приложений.
- Агентические структуры оценки должны оценить как качество ответа, так и процессы принятия решений, а также последствия для безопасности и согласованность с предполагаемыми целями (Andrenacci, 2025)Середина, (Чаудхари, 2025)ТьюрингПолем
- Системы оценки в реальном времени должны сохранять как тщательные возможности оценки, так и эффективную вычислительную производительность.
10 Заключение
Оценка LLMS с помощью интеграции обратной связи человека с автоматическими метриками создает полный метод оценки для эффективности модели. Сочетание традиционных показателей с человеческим суждением о качестве дает лучшие результаты для реальных приложений и этического соответствия и удовлетворенности пользователей. Реализация целостных методов оценки приведет к более точным и этическим решениям искусственного интеллекта, которые будут стимулировать будущие достижения. Множественные методологии оценки должны использоваться в успешных структурах оценки для достижения баланса между автоматической эффективностью и суждением рецензента человека. Организации, которые реализуют комплексные стратегии оценки, сообщают о существенном улучшении в области безопасности, эффективности и операционной эффективности, демонстрируя практическую ценность инвестиций в надежные возможности оценки.
11 Ссылки
- Kim, S. et al. (2023)- Прометей: мелкозернистая возможность оценки
https://arxiv.org/abs/2310.08491 - Rei, R. et al. (2024)- xcomet-lite: эффективность и баланс качества
https://aclanthology.org/2024.emnlp-main.1223/ - Антроп (2023)- Конституция Клода
https://www.anthropic.com/news/claudes-constitution - Антроп (2022)- Конституционное исследование ИИ
https://www.anthropic.com/research/constitutional-ai-harmless-from-ai-feedback - Обнимающееся лицо (2023)- RLHF Иллюстрация
https://huggingface.co/blog/rlhf - Huyen, C. (2023)- RLHF: подкрепление, обучение на отзывах человека
https://huyenchip.com/2023/05/02/rlhf.html - IBM (2024)- Руководство по оценке LLM
https://www.ibm.com/think/insights/llm-valuation - Microsoft (2024)- Документация по оценке метрик
https://learn.microsoft.com/en-us/ai/playbook/technology-guidance/generative-ai/working-with-llms/evaluation/list-of-val-metrics - Красная шляпа (2024)- Оценка производительности LLM
https://next.redhat.com/2024/05/16/evaluation-the-performance-of-large-language-models/ - Стэнфордский CRFM (2022)- Хелм Фреймворк
https://crfm.stanford.edu/helm/ - Wolfe, C.R. (2024)- Использование LLM для оценки
https://cameronrwolfe.substack.com/p/llm-as-ajudge - Андреначчи, Г. (2025)- 18 Ai Llm Trends в 2025 году
https://medium.com/data-bistrot/15-artificial-intelligence-llm-trends-in-2024-618a058c9fdf - Серо -серий, C. (2024)-Агенты LLM человека в петле
https://cobusgreyling.medium.com/human-in-the-loop-llm-agents-e0a046c1ec26 - Mansuy, R. (2024)- Комплексное руководство по метрикам оценки НЛП
https://medium.com/@raphael.mansuy/evaluation-the-performance-of-natural-processing-nlp-models-can-be-challenging-ce6f62c07c35 - Dhungana, K. (2024)- Понимание Bleu, Rouge, Meteor и Bertscore
https://medium.com/@kbdhunga/nlp-model-valuation-sresting-bleu-rouge-meteor-and-bertscore-9bad7db71170 - Sojasingarayar, A. (2024)- Бертскор объяснил за 5 минут
https://medium.com/@abonia/bertscore-explained-in-5minutes-0b98553bfb71 - Speernonotate (2024)- Руководство по оценочной структуре оценки LLM
https://www.superannotate.com/blog/llm-valuation-guide - Speernonotate (2024)- Руководство по оптимизации прямых предпочтений
https://www.superannotate.com/blog/direct-preference-optimization-dpo - Уверенный ИИ (2024)- Руководство по оценке Ultimate LLM
https://www.confident-ai.com/blog/llm-valuation-metrics-everything-you-need-for-llm-evaluation - Уверенный ИИ (2025)- Методы и стратегии тестирования LLM
https://www.confident-ai.com/blog/llm-testing-in-2024-top-methods-and стратегии - Aimultiple (2025)- Методы оценки модели большой языка
https://research.aimultiple.com/large-language-model-valuation/ - HumanLoop (2025)- 5 инструментов оценки LLM, которые вы должны знать
https://humanloop.com/blog/best-llm-valuation-tools - DataDog (2024)- Создание лучших практик оценки LLM LLM
https://www.datadoghq.com/blog/llm-valuation-framework-best-practices/ - Labelbox (2024)- Native LLM и мультимодальная поддержка гибридной оценки
https://labelbox.com/blog/labelbox-q1-2024-product-release/ - Label Studio (2024)- Оценки LLM: методы, проблемы и лучшие практики
https://labelstud.io/blog/llm-evaluations-techniques-challenges-and-best-practices/ - Лейблвизор (2024)- Интеграция петлей обратной связи человека в обучение LLM
https://www.labelvisor.com/integrating-human-feedback-loops-into-llm-sraining-data/ - MIT Press (2024)- Предвзятость и справедливость в обследовании моделей крупных языковых моделей
https://direct.mit.edu/coli/article/50/3/1097/121961 - МВФ (2024)- Подкрепление обучения из обратной связи с опытом
https://www.elibrary.imf.org/view/journals/001/2024/114/article-a001-en.xml - Гикс -гидригейки (2024)- Понимание оценки Bleu и Rouge для оценки NLP
https://www.geeksforgeeks.org/nlp/understanding-bleu-and-rouge-score-for-nlp-valuation/ - Аналитика Видхья (2025)- Bertscore: контекстуальная метрика для оценки LLM
https://www.analyticsvidhya.com/blog/2025/04/bertscore-a-contextual-metric-for-llm-valuation/ - Saturn Cloud (2024)- Оценка моделей машинного перевода
https://saturncloud.io/blog/evaluation-machine-translation-models-traditional-and-novel-prapoaches/ - Тьюринг (2025)- Top LLM Trends 2025: Какое будущее LLMS
https://www.turing.com/resources/top-llm-drends - 10pearls (2024)- Поиск правильного LLM для вашего бизнеса
https://10pearls.com/find-the-right-llm-for-your-business/ - Сообщество разработчиков (2025)- 5 лучших рамок оценки LLM с открытым исходным кодом
https://dev.to/guybuildingai/-top-5-open-source-llm-valuation-frameworks-in-2024-98m - Оливера, Дж. (2024)-Обеспечение точности в ИИ с человеком в петле
https://medium.com/@j.m.olivera08/ensuring-accuracy-in-ai-with-human-in-tyloop-7a4d9143296d - ** OPENAI-«Модели языка обучения, чтобы следовать инструкциям с человеческой обратной связью» ** В этой статье представлен подход InstructGPT, где модель с образованием рейтинга, сгенерированная человеком, с помощью RLHF:
Обучающие языковые модели, чтобы следовать инструкциям с отзывом человека (Openai, 2022)ResearchGate.net+7SciRP.org+7sciRP.org+7QA.Time.com+13cdn.openai.com+13youtube.com+13 - ** Papinenietal. - «Bleu: метод автоматической оценки машинного перевода \ Сличальная бумага ACL 2002 года, внедряющая метрику Bleu:
Bleu: метод автоматической оценки машинного перевода (Papineni et al., 2002)Medium.com+12Aclanthology.org+12en.wikipedia.org+12Aclanthology.org - ** Лин, C.Y. - «Руж: пакет для автоматической оценки резюме» \ The Acl Workshop Paper, представляющая метрики Rouge:Rouge: пакет для автоматической оценки резюме (Lin, 2004)microsoft.com+15aclanthology.org+15bibbase.org+15
Оригинал