

Лучший высший список из 50 вопросов на собеседовании • Мастер LLMS, взломайте ваше следующее интервью
13 июня 2025 г.Если вы когда -либо сели, чтобы подготовиться к собеседованию LLM и в итоге получили 30 вкладок, открытых по механизмам внимания, LORA и токенизации - вы не одиноки.
Я тоже был там. То, что начиналось как быстрое учебное заседание, часто бывает в лабиринт перекрывающихся постов в блоге, плотных исследовательских документах и темах форума, которые отвечали на всекромеВопрос, который я пытался понять.
Дело не было, что информации не было - это было. Но это было разбросано, чрезмерно академическое или похороненное в жаргоне. И когда вы пытаетесь подготовиться к собеседованию (или просто понять, как все работает), такой шум не помогает. Это замедляет тебя.
Именно поэтому я собрал это руководство: куратор из 50 самых важных вопросов крупной языковой модели (LLM)-те, которые последовательно появляются в интервью, разговорах в реальном мире и практических проектах. Каждый вопрос поставляется с четким, обоснованным ответом, который пропускает пух и становится прямо к «ага».
Независимо от того, чистите ли вы свою следующую роль, проводите собеседование с кандидатами или просто пытаетесь углубить свое понимание того, как на самом деле работают LLM, это предназначено для того, чтобы сэкономить ваши часы разбросанных исследований и помочь вам сосредоточиться на том, что наиболее важно.
Давайте погрузимся.

Вопрос 1: Что влечет за собой токенизация и почему это критическое для LLMS?
Токенизация включает в себя разбивание текста на более мелкие единицы или токены, такие как слова, подчинки или символы. Например, «искусственный» может быть разделен на «искусство», «ific» и «ial». Этот процесс жизненно важен, потому что LLMS обрабатывает численные представления токенов, а не сырой текст. Токенизация позволяет моделям обрабатывать различные языки, управлять редкими или неизвестными словами и оптимизировать размер словарного запаса, повышая вычислительную эффективность и производительность модели.
Вопрос 2: Как функционирует механизм внимания в моделях трансформатора?
Механизм внимания позволяет LLMS весить важность разных токенов в последовательности при генерации или интерпретации текста. Он вычисляет оценки сходства между векторами запроса, ключа и значения, используя такие операции, как точечные продукты, чтобы сосредоточиться на соответствующих токенах. Например, в «Кошке преследовали мышь», внимание помогает «мышь» модели «мышь». Этот механизм улучшает понимание контекста, делая трансформаторы очень эффективными для задач NLP.
Вопрос 3: Что такое окно контекста в LLMS и почему это имеет значение?
Контекстное окно относится к количеству жетонов, которые LLM может обрабатывать одновременно, определяя ее «память» для понимания или генерации текста. Большее окно, например, 32000 жетонов, позволяет модели рассмотреть больше контекста, улучшая когерентность в таких задачах, как суммирование. Тем не менее, это увеличивает вычислительные затраты. Балансировать размер окна с эффективностью имеет решающее значение для практического развертывания LLM.
Вопрос 4: Что отличает Лору от Qlora в тонкой настройке LLMS?
Lora (адаптация с низким рейтингом)-это метод тонкой настройки, который добавляет матрицы с низким уровнем ранга к уровням моделей, что обеспечивает эффективную адаптацию с минимальными задержками памяти. Qlora расширяет это, применяя квантование (например, 4-битную точность) для дальнейшего снижения использования памяти при сохранении точности. Например, Qlora может точно настроить модель 70B-параметра на одном графическом процессоре, что делает ее идеальной для ограниченных ресурсов.
Вопрос 5: Как поиск луча улучшает генерацию текста по сравнению с жадным декодированием?
Поиск луча исследует несколько последовательностей слов во время генерации текста, сохраняя верхние K кандидатов (балки) на каждом шаге, в отличие от жадного декодирования, которое выбирает только наиболее вероятное слово. Например, этот подход, с k = 5, обеспечивает более когерентные результаты путем балансировки вероятности и разнообразия, особенно в таких задачах, как генерация Machine Translation ordealogue.
Вопрос 6: Какую роль играет температура в управлении выходом LLM?
Температура - это гиперпараметр, который регулирует случайность выбора токена в генерации текста. Низкая температура (например, 0,3) способствует высокоскоростному токенам, производя предварительно-дизнабные результаты. Высокая температура (например, 1,5) увеличивает разнообразие за счет сглаживания распределения вероятностей. Установка температуры до 0,8 часто уравновешивает творчество и согласованность для таких задач, как рассказывание историй.
Вопрос 7: Что такое маскированное моделирование языка и как оно помогает предварительному обработке?
Моделирование языка в масках (MLM) включает в себя сокрытие случайных токенов в последовательности и обучение модели, чтобы предсказать их на основе контекста. Используется в таких моделях, как BERT, MLM способствует двунаправленному пониманию языка, позволяя модели понять семантические отношения. Этот предварительный подход дает LLMS для ответа на вопрос о том, как анализ настроений.
Вопрос 8: Что такое модели последовательности к последовательности и где они применяются?
Модели последовательности к последовательности (SEQ2SEQ) преобразуют входную последовательность в выходную последовательность, часто различной длины. Они состоят из энкодера для обработки входа и декодера для генерации вывода. Приложения включают в себя машинный перевод (например, английский в испанский), текстовое обобщение и чат-боты, где распространены входы и выходы переменной длины.
Вопрос 9: Как авторегрессивные и маскированные модели отличаются по обучению LLM?
Авторегрессивные модели, такие как GPT, прогнозируют токены последовательно на основе до токенов, превосходящих генеративные задачи, такие как завершение текста. Маскированные модели, такие как BERT, предсказывают токены в масках с использованием двунаправленного контекста, что делает их идеальными для понимания таких задач, как классификация. Их тренировочные цели формируют их сильные стороны в поколении по сравнению с сочетанием.
Вопрос 10: Что такое встроенные и как они инициализируются в LLMS?
Встроены плотные векторы, которые представляют токены в непрерывном пространстве, захватывая семантические и синтаксические свойства. Они часто инициализируются случайным образом или с предварительно проведенными моделями, такими как перчатка, а затем настраиваются во время тренировки. Например, внедрение для «собаки» может развиваться, чтобы отразить его контекст в задачах, связанных с ПЭТ, повышая точность модели.
Вопрос 11: Что такое предсказание следующего предложения и как оно усиливает LLMS?
Следующее предложение предсказания (NSP) побуждают модели, чтобы определить, являются ли два предложения последовательно или не связаны. Во время предварительной подготовки, такие модели, как BERT, учатся классифицировать 50% положительных (последовательных) и 50% отрицательных (случайных) пар предложений. NSP улучшает согласованность в таких задачах, как система диалога или суммирование документов путем понимания отношений предложений.
Вопрос 12: Как выборка Top-K и Top-P отличается по генерации текста?
Отбор выборки Top-K выбирает наиболее вероятные токены (например, K = 20) для случайной выборки, обеспечивая контролируемое разнообразие. Отбор выборки Top-P (ядро) выбирает токены, совокупная вероятность которого превышает порог p (например, 0,95), адаптируясь к контексту. Top-P предлагает большую гибкость, производя различные, но последовательные результаты в творческом письме.
Вопрос 13: Почему быстрая инженерная инженерия имеет решающее значение для производительности LLM?
Обратная техника включает в себя проектирование входов для получения желаемых ответов LLM. Четкая подсказка, например, «суммировать эту статью в 100 словах», улучшает актуальность вывода по сравнению с расплывчатыми инструкциями. Это особенно эффективно в настройках с нулевым выстрелом или несколькими выстрелами, что позволяет LLMS решать такие задачи, как перевод или классификация без обширной тонкой настройки.
Вопрос 14: Как LLMS может избежать катастрофического забывания во время точной настройки?
Катастрофическое забывание происходит, когда тонкая настройка стирает предварительные знания. Стратегии смягчения включают:
- Репетиция: смешивание старых и новых данных во время обучения.
- Консолидация упругого веса: приоритет критическим весам для сохранения знаний.
- Модульные архитектуры: добавление модулей для конкретной задачи, чтобы избежать перезаписи.
Эти методы гарантируют, что LLM сохраняют универсальность между задачами.
Вопрос 15: Что такое дистилляция модели, и как она приносит пользу LLMS?
Модельная дистилляция обучает меньшую «студенческую» модель, чтобы имитировать более крупные результаты модели «учителя», используя мягкие вероятности, а не жесткие этикетки. Это снижает память и вычислительные требования, что позволяет развертываться на таких устройствах, как смартфоны, сохраняя при этом производительность почти учителя, идеально подходит для приложений в реальном времени.
Вопрос 16: Как LLM управляют словами вне вокалубения (OOV)?
LLMS использует токенизацию подвода, такую как кодирование байтовой пары (BPE), чтобы разбить слова на известные подразделения подчинки. Например, «криптовалюта» может разделить на «крипто» и «валюта». Этот подход позволяет LLMS обрабатывать редкие или новые слова, обеспечивая надежное понимание языка и поколение.
Вопрос 17: Как улучшают трансформаторы на традиционных моделях SEQ2SEQ?
Трансформеры преодолевают ограничения SEQ2SEQ с помощью:
- Параллельная обработка: самосознание позволяет одновременная обработка токенов, в отличие от последовательных RNN.
- Долгосрочные зависимости: внимание захватывает отдаленные токеновые отношения.
- Позиционные кодировки: эти порядок последовательности сохранения.
Эти функции повышают масштабируемость и производительность в таких задачах, как перевод.
Вопрос 18: Что переосмыслить и как его можно смягчить в LLMS?
Переполнение происходит, когда модель запоминает учебные данные, несмотря на обобщение. Смягчение включает в себя:
- Ретализация: штрафы L1/L2 упрощают модели.
- Выброшенный: случайным образом отключает нейроны во время тренировки.
- Ранняя остановка: останавливает обучение при проверке Performance Plateaus.
Эти методы обеспечивают надежное обобщение невидимых данных.
Вопрос 19: Что такое генеративные и дискриминационные модели в НЛП?
Генеративные модели, такие как GPT, моделируют совместные вероятности для создания новых данных, таких как текст или изображения. Дискриминационные модели, такие как BERT для классификации, условные вероятности модели, чтобы различать классы, например, анализ настроений. Генеративные модели преуспевают в создании, в то время как дискриминационные модели фокусируются на точной классификации.
Вопрос 20: Чем GPT-4 отличается от GPT-3 в функциях и приложениях?
GPT-4 превосходит GPT-3 с:
- Мультимодальный ввод: обрабатывает текст и изображения.
- Большой контекст: обрабатывает до 25 000 токенов против 4096 GPT-3.
- Повышенная точность: уменьшает фактические ошибки за счет лучшей тонкой настройки.
Эти улучшения расширяют свое использование в ответе на визуальные вопросы и сложные диалоги.
Вопрос 21: Что такое позиционные кодировки и почему они используются?
Позиционные кодировки добавляют информацию заказа последовательности к входам трансформатора, так как самоубийство отсутствует в неотложении порядка. Используя синусоидальные функции или изученные векторы, они гарантируют, что такие токены, как «король» и «корона», интерпретируются правильно на основе позиции, критически важных для таких задач, как перевод.
Вопрос 22: Что такое многоуровневое внимание и как оно улучшает LLMS?
Многоугольное внимание расщепляет запросы, клавиши и значения в несколько подпространств, позволяя модели сосредоточиться на различных аспектах ввода одновременно. Например, в предложении одна голова может сосредоточиться на синтаксисе, другой на семантике. Это улучшает способность моделей захватывать сложные закономерности.
Вопрос 23: Как функция SoftMax применяется в механизмах внимания?
Функция SoftMax нормализует оценки внимания в распределение вероятностей:
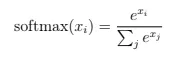 В внимании он превращает необработанные оценки сходства (из точечных продуктов с ключом) в веса, подчеркивая соответствующие токены. Это гарантирует, что модель фокусируется на контекстуально важных частях ввода.
В внимании он превращает необработанные оценки сходства (из точечных продуктов с ключом) в веса, подчеркивая соответствующие токены. Это гарантирует, что модель фокусируется на контекстуально важных частях ввода.
Вопрос 24: Как точечный продукт способствует самоутверждению?
В самостоятельном примере продукт точки между векторами запроса (Q) и ключами (k) вычисляет оценки сходства:
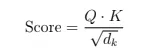 Высокие оценки указывают на соответствующие токены. Несмотря на эффективность, его квадратичная сложность (O (N²)) для длинных последовательностей стимулировала исследования в редких альтернативах внимания.
Высокие оценки указывают на соответствующие токены. Несмотря на эффективность, его квадратичная сложность (O (N²)) для длинных последовательностей стимулировала исследования в редких альтернативах внимания.
Вопрос 25: Почему потери перекрестной энтропии используются в языковом моделировании?
Потеря по перекрестной энтропии измеряют дивергенцию между прогнозируемыми и верными вероятностями токена:
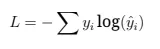 Он наказывает неверные прогнозы, поощряя точный выбор токенов. В языковом моделировании это гарантирует, что модель назначает высокие вероятности исправлять рядом с токенами, оптимизируя производительность.
Он наказывает неверные прогнозы, поощряя точный выбор токенов. В языковом моделировании это гарантирует, что модель назначает высокие вероятности исправлять рядом с токенами, оптимизируя производительность.
Вопрос 26: Как градиенты вычисляются для встраивания в LLMS?
Градиенты для встраиваний вычисляются с использованием цепного правила во время обратного распространения:
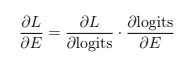 Эти градиенты корректируют встраивающие векторы, чтобы минимизировать потерю, уточняя их семантические представления для лучшей выполнения задач.
Эти градиенты корректируют встраивающие векторы, чтобы минимизировать потерю, уточняя их семантические представления для лучшей выполнения задач.
Вопрос 27: Какова роль Якобианской матрицы в обратном распространении трансформатора?
Якобианская матрица захватывает частичные производные выходов по отношению к входам. В трансформаторах он помогает вычислить градиенты для многомерных выходов, обеспечивая точные обновления веса и встраивания во время обратного распространения, критически важных для оптимизации сложных моделей.
Вопрос 28: Как собственные значения и собственные векторы связаны с уменьшением размерности?
Собственные векторы определяют основные направления в данных, а собственные значения указывают на их дисперсию. В таких методах, как PCA, выбор собственных векторов с высокими собственными значениями снижает размерность, сохраняя при этом большую часть дисперсии, что позволяет эффективному представлению данных для обработки ввода LLMS.
Вопрос 29: Что такое дивергенция KL и как она используется в LLMS?
KL Дивергенция количественно определяет разницу между двумя распределениями вероятностей:
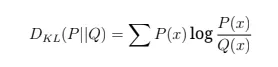 В LLMS он оценивает, как близко к модели прогнозы соответствуют истинным распределениям, направляя тонкую настройку для улучшения качества выходных данных и выравнивания с целевыми данными.
В LLMS он оценивает, как близко к модели прогнозы соответствуют истинным распределениям, направляя тонкую настройку для улучшения качества выходных данных и выравнивания с целевыми данными.
Вопрос 30: Какова производная функции RELU и почему это значимо?
Функция RELU, f (x) = max (0, x), имеет производную:
 Его разреженность и нелинейность предотвращают градиенты исчезновения, делая религиозные вычислительные и широко используемые в LLM для надежного обучения.
Его разреженность и нелинейность предотвращают градиенты исчезновения, делая религиозные вычислительные и широко используемые в LLM для надежного обучения.
Вопрос 31: Как правило цепи применяется к градиентному спуска в LLMS?
Правило цепи вычисляет производные композитных функций:
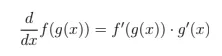 В градиентном спуска он позволяет обратно разжигать расчет слоя градиентов по слою, обновлять параметры, чтобы эффективно минимизировать потери в глубоких архитектурах LLM.
В градиентном спуска он позволяет обратно разжигать расчет слоя градиентов по слою, обновлять параметры, чтобы эффективно минимизировать потери в глубоких архитектурах LLM.
Вопрос 32: Как рассчитываются оценки внимания в трансформаторах?
Оценки внимания вычисляются как:
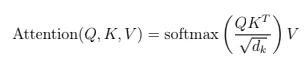 Масштабированный точечный продукт измеряет актуальность токена, и Softmax нормализует оценки, чтобы сосредоточиться на ключевых токенах, улучшая генерацию контекста в таких задачах, как суммирование.
Масштабированный точечный продукт измеряет актуальность токена, и Softmax нормализует оценки, чтобы сосредоточиться на ключевых токенах, улучшая генерацию контекста в таких задачах, как суммирование.
Вопрос 33: Как Близнецы оптимизируют мультимодальное обучение LLM?
Близнецы повышают эффективность через:
- Унифицированная архитектура: объединяет обработку текста и изображений для эффективности параметров.
- Расширенное внимание: улучшает кросс-модальную стабильность обучения.
- Эффективность данных: использует самоотверженные методы для снижения заданных потребностей данных.
Эти функции делают Близнецы более стабильными и масштабируемыми, чем модели, такие как GPT-4.
Вопрос 34: Какие виды моделей фундамента существуют?
Фонд модели включают:
- Языковые модели: Bert, GPT-4 для текстовых задач.
- Модели зрения: Resnet для классификации изображений.
- Генеративные модели: Dall-E для создания контента.
- Мультимодальные модели: клип для задач текстового изображения.
Эти модели используют широкую предварительную подготовку для различных приложений.
Вопрос 35: Как PEFT смягчает катастрофическое забывание?
Параметр-эффективная тонкая настройка (PEFT) обновляет лишь небольшое подмножество параметров, замораживая остальные, чтобы сохранить предварительно предварительно предоставленные знания. Такие методы, как Lora, гарантируют, что LLMS адаптируется к новым задачам, не теряя основных возможностей, поддерживая производительность между доменами.
Вопрос 36: Каковы шаги в поколении в поисках (Rag)?
Тряпка включает в себя:
- Поиск: извлечение соответствующих документов с использованием встроенных запросов.
- Рейтинг: сортировка документов по актуальности.
- Поколение: использование полученного контекста для генерации точных ответов.
RAG повышает фактическую точность в таких задачах, как ответ на вопросы.
Вопрос 37: Как смеси экспертов (MOE) повышает масштабируемость LLM?
MOE использует функцию стробирования для активации конкретных экспертных подсчетов на вход, снижая вычислительную нагрузку. Например, только 10% параметров модели могут использоваться в соответствии с запросом, что позволяет эффективно работать на миллиард параметра при сохранении высокой производительности.
Вопрос 38: Что подсказывает цепь мыслей (COT) и как это помогает рассуждать?
КОМПЛЕКТИЯ РУКОВОДСТВОВАНИЯ LLMS для решения проблем пошаговым, имитирующим человеческие рассуждения. Например, в математических задачах он разбивает расчеты на логические шаги, повышая точность и интерпретацию в сложных задачах, таких как логический вывод или многоэтапные запросы.
Вопрос 39: Чем различаются дискриминационные и генеративные ИИ?
Дискриминационный ИИ, как и классификаторы настроений, прогнозирует метки на основе входных функций, моделирование условных вероятностей. Генеративный ИИ, как и GPT, создает новые данные, моделируя совместные вероятности, подходящие для таких задач, как текст или генерация изображений, предлагая творческую гибкость.
Вопрос 40: Как интеграция графа знаний улучшает LLMS?
Графики знаний предоставляют структурированные, фактические данные, улучшая LLMS за счет:
- Уменьшение галлюцинаций: проверка фактов на графике.
- Улучшение рассуждений: использование отношений сущности.
- Улучшение контекста: предложение структурированного контекста для лучших ответов.
Это полезно для ответа на вопросы и признания сущности.
Вопрос 41: Что такое нулевое обучение и как его реализуют LLMS?
Обучение с нулевым выстрелом позволяет LLMS выполнять неподготовленные задачи, используя общие знания из предварительной подготовки. Например, подсказка с «классифицировать этот обзор как положительный или отрицательный», LLM может сделать вывод на настроение без конкретных данных, демонстрируя его универсальность.
Вопрос 42: Как адаптивный SoftMax оптимизирует LLMS?
Адаптивные группы Softmax Слова по частоте, уменьшая вычисления для редких слов. Это снижает стоимость обработки больших словари, ускоряя обучение и вывод, сохраняя при этом точность, особенно в условиях ограниченных ресурсов.
Вопрос 43: Как трансформаторы решают проблему исчезновения градиента?
Трансформеры смягчают градиенты исчезновения через:
- Самоализация: избегание последовательных зависимостей.
- Остаточные соединения: разрешение прямого градиента.
- Нормализация слоя: стабилизирующие обновления.
Они обеспечивают эффективную подготовку глубоких моделей, в отличие от RNN.
Вопрос 44: Что такое несколько выстрелов, и каковы его преимущества?
Несколько выстрелов позволяет LLMS выполнять задачи с минимальными примерами, используя предварительно предоставленные знания. Преимущества включают в себя снижение потребностей в данных, более высокую адаптацию и экономическую эффективность, что делает его идеальным для нишевых задач, таких как специализированная классификация текста.
Вопрос 45: Как бы вы установили сгенерирование LLM, сгенерирующие или неверные выходы?
Для решения смещенных или неправильных выходов:
- Анализировать закономерности: Определите источники смещения в данных или подсказках.
- Улучшение данных: используйте сбалансированные наборы данных и методы ослабления.
- Точная настройка: переподготовка с кураторскими данными или состязательными методами.
Эти шаги улучшают справедливость и точность.
Вопрос 46: Как кодеры и декодеры отличаются по трансформаторам?
Энкодеры обрабатывают входные последовательности в абстрактные представления, захватывая контекст. Декодеры генерируют выходы, используя выходы энкодера и перед токенами. В переводе энкодер понимает источник, а декодер производит целевой язык, что позволяет эффективным задачам seq2seq.
Вопрос 47: Чем LLM отличаются от традиционных моделей статистического языка?
LLM используют архитектуры трансформатора, массивные наборы данных и неконтролируемую предварительную подготовку, в отличие от статистических моделей (например, N-граммов), которые полагаются на более простые, контролируемые методы. LLMS обрабатывает на дальние зависимости, контекстуальные встраивания и разнообразные задачи, но требуют значительных вычислительных ресурсов.
Вопрос 48: Что такое гиперпараметр и почему это важно?
Гиперпараметры - это предустановленные значения, такие как скорость обучения или размер партии, которые контролируют обучение модели. Они влияют на конвергенцию и производительность; Например, высокая скорость обучения может вызвать нестабильность. Настройка гиперпараметров оптимизирует эффективность и точность LLM.
Вопрос 49: Что определяет большую языковую модель (LLM)?
LLMS-это системы ИИ, обученные обширной текстовой корпорации для понимания и генерирования языка, подобного человеку. С миллиардами параметров они преуспевают в таких задачах, как перевод, суммирование и ответ на вопросы, используя контекстное обучение для широкой применимости.
Вопрос 50: С какими проблемами сталкивается LLMS в развертывании?
Проблемы LLM включают в себя:
- Интенсивность ресурсов: высокие вычислительные требования.
- Предвзятость: риск увековечивания предвзятости к данным обучения.
- Интерпретируемость: сложные модели трудно объяснить.
- Конфиденциальность: потенциальные проблемы безопасности данных.
Решение об этом обеспечивает этическое и эффективное использование LLM.
Заключение
Мне потребовалось много времени-и слишком много ночных кроличьих дырок-чтобы понять, что большая часть подготовки к интервью LLM не должна быть таким хаотичным.
Вам не нужно 30 вкладок.
Вам не нужно запоминать каждую неясную бумагу.
Вам просто нужно четко понимать основы, знать, куда идти глубоко, и сосредоточиться на концепциях, которые на самом деле появляются в реальных разговорах и системах.
Это руководство - ресурс, который я хотел бы иметь, когда я начал. Не свалки мозга, а не пух - только основные вопросы и практические объяснения, которые помогают вам звучать как кто -то, ктоПолучает этоПолем
Независимо от того, стремитесь ли вы принять новую роль, отточить свои навыки или просто разобраться в шуме LLM, это ваша основа.
Продолжайте строить на нем - и удачи там.
Хотите услышать от меня чаще?
👉 Связаться со мной на LinkedIn!
Я делюсьежедневноДействительные идеи, советы и обновления, чтобы помочь вам избежать дорогостоящих ошибок и оставаться впереди в мире искусственного интеллекта. Следуй за мной здесь:
Вы специалист по технологиям, чтобы вырастить свою аудиторию за счет написания?
👉 Не пропустите мою информационную рассылку!
МойТехнологическая аудитория ускорительзаполнен действенным копирайтингом и стратегиями построения аудитории, которые помогли сотням профессионалов выделяться и ускоряют их рост. Подпишитесь сейчас, чтобы остаться в курсе.
Оригинал