

Транцик -задача: сборка мебели против любого другого метода обучения роботов
4 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 предварительные
3 Transic: передача политики с рисованием в реальность путем обучения на онлайн-коррекции и 3.1 базовые политики обучения в моделировании с RL
3.2 ОБУЧЕНИЯ ОТРИЦИЯ ПОЛИТИКИ ОТНОВЛЕНИЯ НАУКЦИИ
3.3 Интегрированная структура развертывания и 3,4 Подробности реализации
4 эксперименты
4.1 Настройки эксперимента
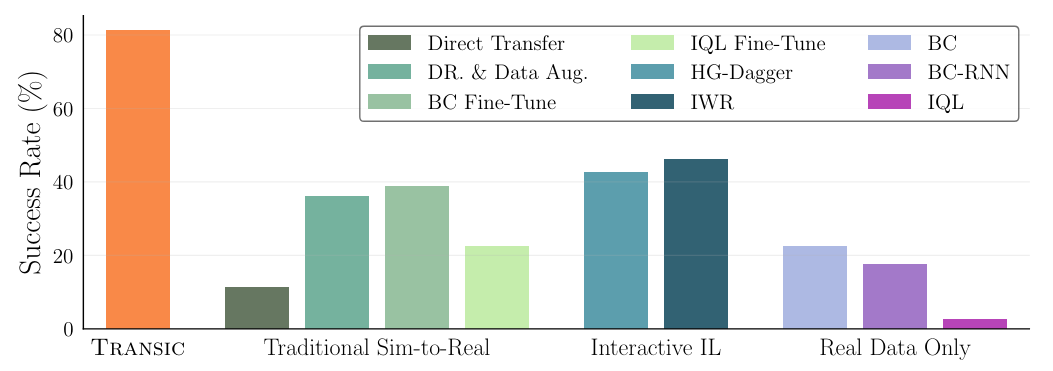
4.2 Количественное сравнение по четырем задачам сборки
4.3 Эффективность в решении различных разрывов с рисунком (Q4)
4.4 Масштабируемость с человеческими усилиями (Q5) и 4,5 интригующих свойств и возникающего поведения (Q6)
5 Связанная работа
6 Заключение и ограничения, подтверждения и ссылки
А. Подробная информация об обучении симуляции
Б. Реальные детали обучения в реальном мире
C. Настройки эксперимента и детали оценки
D. Дополнительные результаты эксперимента
4 эксперименты
Мы стремимся ответить на следующие вопросы исследования с нашими экспериментами:
![Figure 3: Four tasks benchmarked in this work. They are fundamental skills required to assemble a square table from FurnitureBench [90]. We randomize objects’ initial poses during evaluation. a) The robot pushes the square tabletop to the right corner of the wall such that it remains stable in following assembly steps. b) The robot reaches and grasps the table leg. It needs to properly adjust the end effector’s orientation to avoid infeasible grasping poses. c) The robot inserts the pre-grasped table leg to the far right assembly hole of the tabletop. d) The robot’s end-effector is initialized close to an inserted table leg and it screws the table leg clockwise into the tabletop.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-57834mi.png)
Q1: приводит ли трансик к лучшей производительности переноса по сравнению с традиционными методами SIM-к реальности (гл. 4.2)?
Q2: может ли транс лучше интегрировать коррекцию человека в политику, изученную в моделировании, чем существующие подходы к интерактивному имитационному обучению (IL) (Sec. 4.2)?
Q3: требует ли транс-обработчика данных меньше реальных данных для достижения хорошей производительности по сравнению с алгоритмами, которые учатся только у траекторий реального робота (гл. 4.2)?
Q4: Насколько эффективно может трансформировать различные типы разрывов с рисованием с рисунком (раз, 4.3)?
Q5: Как транспортные масштабы с человеческими усилиями (г. 4.4)?
Q6: Вызывает ли транс-интригующие свойства, такие как обобщение для невидимых объектов, эффективное стробирование, устойчивость к политике, последовательность в ученых визуальных характеристиках, способность решать задачи манипуляции с длинными головами и другие возникающие поведения (гл. 4.5)?
4.1 Настройки эксперимента
ЗадачиМы рассматриваем сложные задачи манипуляции, богатые контактами, которые требуют высокой точности в мебели, [90]. Эти задачи сложны и идеально подходят для тестирования передачи для симуляции в реальность, поскольку восприятие, воплощение, контроллер и пробелы в динамике должны быть решены для успешного выполнения задач. В частности, мы разделяем сборку квадратной таблицы на четыре независимых задачи (рис. 3): стабилизируйте, дотягиваются и захватывают, вставьте и винт. Мы собираем 20, 100, 90 и 17 реальных траекторий с коррекцией человека, соответственно. Чтобы дополнительно проверить обобщение до невидимых объектов из новой категории, мы экспериментируем с лампой (рис. 6B). Все эксперименты проводятся на настольной обстановке с установленным роботом Franka Emika 3. Смотрите приложение гл. B.1 Для подробной системы системы.
Базовые линии и протокол оценкиМы сравниваем со следующими тремя группами базовых линий.1) Традиционные методы с рисованием в реальность:Эта группа включает в себя прямое развертывание политики моделирования, обученной рандомизацией доменов и увеличением данных [53], обозначаемой как «Dr. & Data Aug.». Он также охватывает реальную парадигму точной настройки, где политики моделирования дополнительно настраиваются с реальными данными через BC (обозначаемая как «BC Fine-Tune») и современным методом RL (неявный Q-обучение [69], обозначенный как «IQL Fine-Tune»). Чтобы оценить более низкую границу производительности, мы также включаем базовую линию без какого-либо увеличения данных или реального мира, обозначенного как «прямая передача».2) Интерактивный IL:Эта группа представляет современные интерактивные методы обучения имитации, включая HG-Dagger [66] и IWR [67].3) Изучение только на реальных данных: Эта группа включает в себя BC [72], BC-RNN [68] и IQL [69]. Они обучены только на демонстрациях реальной робот. Мы следуем Liu et al. [70] Чтобы пометить вознаграждение за IQL. Все оценки состоят из 20 испытаний, начиная с разных объектов и роботов. Мы прилагаем все усилия для обеспечения тех же начальных настроек при оценке различных методов. См. Приложение Sec. C для подробного протокола оценки.

Авторы:
(1) Юнфан Цзян, факультет информатики;
(2) Чен Ван, кафедра компьютерных наук;
(3) Руохан Чжан, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(4) Цзяджун Ву, Департамент информатики и Институт ИИ, ориентированного на человека (HAI);
(5) Ли Фей-Фей, Департамент информатики и Институт ИИ, ориентированного на человека (HAI).
Эта статья есть
Оригинал