

Маленькая модель ИИ делает большие волны в интеллекте на языке зрения
16 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 терминология
3 Изучение пространства дизайна моделей на языке зрения и 3.1. Все ли предварительно обученные основы эквивалентны VLMS?
3.2 Как полностью ауторегрессивная архитектура сравнивается с архитектурой перекрестного активации?
3.3 Где повышение эффективности?
3.4 Как можно вычислить торговлю на производительность?
4 IDEFICS2-открытая современная модель Фонда зрения и 4.1 многоэтапное предварительное обучение
4.2 Инструкция тонкая настройка и 4.3 оптимизация для сценариев чата
5 Заключение, подтверждение и ссылки
Приложение
A.1 Дальнейшие экспериментальные детали абляций
A.2 Детали инструкции тонкая настройка
A.3 Детали оценок
A.4 Красная команда
4 IDEFICS2-открытая современная модель фонда на языке зрения
С этими знаниями в руках мы обучаем открытую модель 1B параметров: IDEFICS2. В этом разделе описывается конструкция модели, выбор набора данных, последовательность учебных фаз и сравнивает полученную модель с базовыми показателями VLMS.
4.1 многоэтапное предварительное обучение
Мы начинаем с Siglip-So400M и Mistral-7b-V0.1 и Pre-Train IDefics2 на 3 типах данных.
Чередовые документы с изображениемМы используем obelics (Laurençon et al., 2023), открытый набор данных веб-масштаба с переосмысленными текстовыми документами с 350 миллионами изображений и 115 миллиардов текстовых токенов. Как показано авторами, длинные документы обеликов позволяют сохранить производительность языковой модели, учится справляться с произвольным количеством чередующихся изображений, текстов и длительного контекста. Кроме того, авторы показывают, что чередованные документы с изображением являются самым большим движущим фактором для повышения производительности по визуальным задачам ответа на вопросы (VQA), в частности в настройке обучения в контексте. Мы выполняем дополнительное удаление недавно выбранного контента в январе 2024 года, используя API-нереста [3], хотя обелики уже были отфильтрованы для исключения избранного контента по состоянию на сентябрь 2023 года. Мы также удалили 5% документов с самыми высокими показателями недоумения, что рассчитано Falcon-1B (Penedo et al., 2023).
Пары с изображением текстовых текстов по парам изображений-текста позволяет модели изучать выравнивание между изображениями и связанными с ними текстами. Мы используем комбинацию высококачественных пар, аннотируемых человеком, изображений с изображением из PMD (Singh et al., 2022) и пары с изображением изображений с более высоким шумом из (Schuhmann et al., 2022). Чтобы ограничить количество некачественных данных, мы выбираем синтетические подписи, полученные с помощью версии набора данных Laion Coco [4], где изображения были подписаны с помощью модели, обученной на Coco. Это улучшает качество обучающих образцов и, следовательно, качество полученной модели (см. Таблицу 6). Мы используем NSFW Classifier5 с высоким отзывами и удаляем 7% образцов в Laion Coco. Мы вручную проверяем 5 000 примеров и обнаружили 28 порнографических изображений в оригинальной Laion Coco и только 1 после фильтрации. Эта фильтрация не отрицательно влияет на производительность вниз по течению.

PDF документы Sun et al. (2023) показывает, что большая часть ошибок современных VLMS вытекает из-за их неспособности точно извлечь текст в изображениях или документах. Чтобы получить сильные способности к пониманию OCR и документа, мы обучаем IDEFICS2 различным источникам документов PDF: 19 миллионов отраслевых документов из OCR-IDL (Biten et al., 2022) и 18 миллионов страниц от PDFA [6]. Более того, мы добавляем текст рендеринга [7] в дополнение к набору данных текстами, написанными с широким спектром шрифтов и цветов, а также на разнообразных фонах. Эти интеграции значительно повышают производительность на критериях, которые требуют чтения текста без снижения производительности на других критериях (см. Таблицу 7).
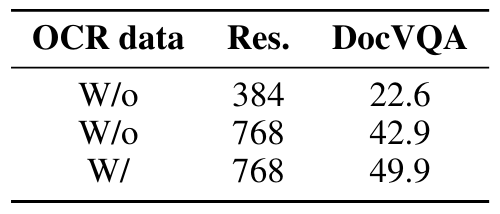
Чтобы максимизировать эффективность вычислителя, мы разлагаем предварительное обучение на два этапа. На первом этапе мы ограничиваем максимальное разрешение изображения 384 пикселями, что позволяет нам использовать большой глобальный размер партии 2'048 (в среднем 17 тыс. Изображений и 2,5 млн. Текста). Мы выбираем обелики для 70% примеров с максимальной длиной последовательности 2’048 и наборами данных парами-текста для 30% примеров с максимальной длиной последовательности 1'536. На втором этапе мы вводим PDF -документы. Поскольку они требуют более высокого разрешения изображения, чтобы текст был разборчивым, мы увеличиваем разрешение максимум до 980 пикселей. Мы используем тот же самый глобальный размер партии, но должны уменьшить размер партии на каждого и использовать накопление градиента, чтобы компенсировать дополнительную стоимость памяти. Обелики представляют 45% примеров с максимальной длиной последовательности 2’048, пары изображения текстовых текстов представляют 35% примеров с максимальной длиной последовательности 1'536, а PDF-документы представляют оставшиеся 20% примеров с максимальной длиной последовательности 1'024. Кроме того, мы случайным образом масштабируем изображения, чтобы адекватно охватить распределение потенциальных размеров изображений. Мы подчеркиваем, что стадии обучения отличаются от тех, которые поднимаются в (Karamcheti et al., 2024): вместо избирательного замораживания/разведывания частей модели мы обучаем всю модель на обоих этапах (некоторые параметры обучаются с LORA) и увеличиваем разрешение изображения от одного этапа к другим.

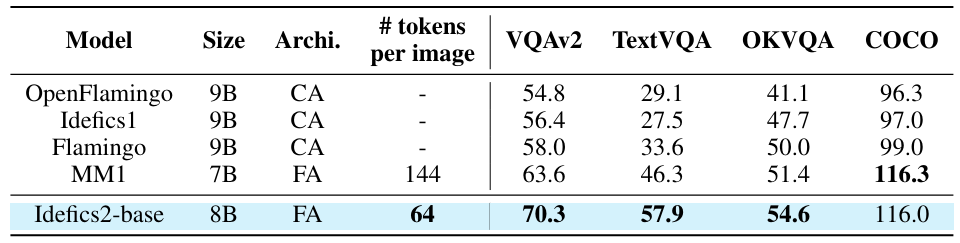
Чтобы оценить базовую модель, мы рассмотрим VQAV2 (Goyal et al., 2017), Textvqa (Singh et al., 2019), Okvqa (Marino et al., 2019) и Coco (Lin et al., 2014). В таблице 8 представлены результаты. При наличии меньшего количества токенов на изображение и, следовательно, более эффективно, IDEFICS2 работает выгодно по сравнению с другими точными лучшими базовыми VLMS (OpenFlamingo (Awadalla et al., 2023), IDEFICS1 (Laurençon et al., 2023), Flamingo (Alayrac et al., 2022) и MM1 (McKinzie et., 2024), 2024). Это особенно лучше в чтении текстов на изображении. На рисунке 3 показан пример вывода базовой модели на задаче, аналогичной предварительной тренировке.

4.2 Инструкция тонкая настройка
Мы продолжаем обучение с фазой точной настройки обучения.
Для этого мы создаем и выпускаем котел [8], массивную коллекцию из 50 наборов данных на уровне зрения, охватывающая широкий спектр задач: общий ответ на визуальные вопросы, подсчет, подписание, транскрипция текста, понимание документов, понимание диаграммы/фигуры, понимание таблицы, визуальные рассуждения, геометрия, определение различий между двумя изображениями или конвертационными скризинами к функциональному коде. Подобно (Sanh et al., 2022; Wei et al., 2022; Bach et al., 2022; Dai et al., 2023; Li et al., 2023), каждый набор данных запрашивается в общий формат вопроса/ответа. Когда есть несколько паров вопросов/ответов на изображение, мы объединяем пары в разговор с несколькими поворотами. Мы дедуплифицируем набор обучения в отношении наборов оценки, обеспечивающих минимальное загрязнение от обучения до оценки.
В дополнение к этим наборам данных на языке зрения и следующим пониманию (McKinzie et al., 2024), мы добавляем наборы данных только для текста в смесь. Наборы данных направлены на обучение модели следовать сложным инструкциям, решать математические задачи или арифметические расчеты. Мы даем более подробную информацию о выбранных наборах данных, количестве изображений, парах вопросов-ответов и размере каждого из подмножеств, а также о выбранной пропорции смеси в таблице 14 в Приложении A.2.1.
Мы обучаем базовую модель, используя DORA (Liu et al., 2024) (вариант лоры). Во время точной настройки мы только вычислим потерю токенов ответов в парах Q/A. Поскольку мы делаем много эпох в некоторых наборах данных, мы используем несколько стратегий, чтобы снизить риск переживания. Во -первых, мы добавляем шум к встраиванию с техникой Neftune (Jain et al., 2024). Затем мы случайным образом увеличиваем разрешение изображений во время обучения. Наконец, когда мы применим, мы перетасовываем многочисленного пользователя/помощника случайным образом, прежде чем подавать пример модели.
Мы оцениваем IDEFICS2 по обычно принятым контрольным показателям: MMMU (Yue et al., 2024) для междисциплинных задач на уровне колледжа, Mathvista (Lu et al., 2024) для математических рассуждений, Textvqa
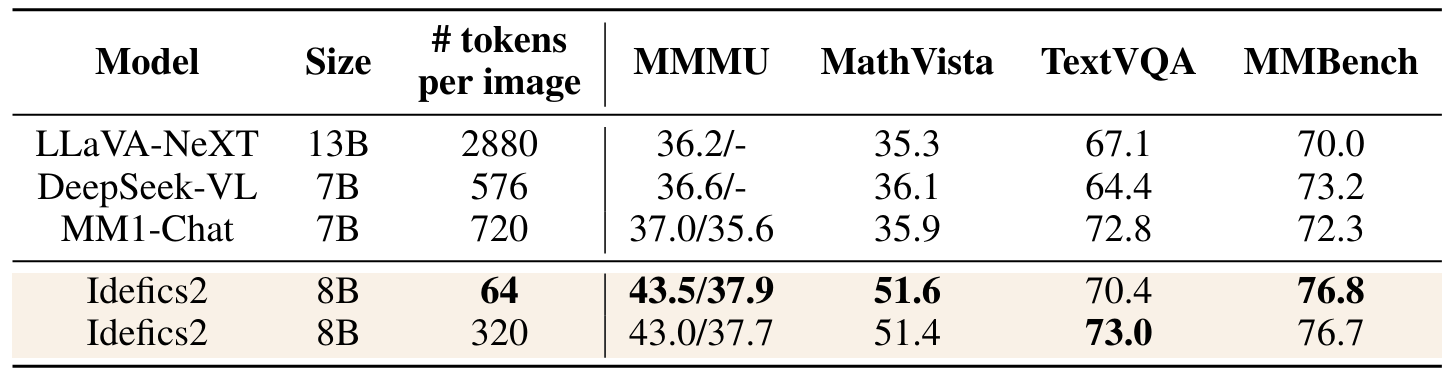
(Singh et al., 2019) для чтения текста на естественных изображениях, и Mmbench Liu et al. (2023) Для различных задач восприятия и рассуждений. В таблице 9 представлены результаты (см. Таблицу 15 для полной таблицы результатов) IDEFICS2 против текущих самых сильных VLM в размере своего класса: Llava-Next (Liu et al., 2024), Deepseek-Vl (Lu et al., 2024) и MM1-Chat (McKinzie et al., 2024). Будучи вычислительно более эффективным при выводе, IDEFICS2 демонстрирует сильную производительность по различным показателям, опередив текущие VLMS Best Foundation VLMS в своей категории размера. Он находится на одном уровне с самыми современными моделями 4x его размера, или с моделями с закрытым исходным кодом, такими как Gemini 1.5 Pro, на нескольких критериях, таких как Mathvista или Textvqa.
4.3 Оптимизация для сценариев чата
Оценные критерии ожидают очень коротких ответов, но люди предпочитают длительные поколения при взаимодействии с моделью. Мы обнаруживаем, что IDEFICS2 может проявлять трудности в том, что они точно следовали инструкциям о ожидаемом формате, что затрудняет согласование «чат» и производительность нисходящего. Таким образом, после точной настройки обучения мы дополнительно обучаем IDEFICS2 данных диалога. Мы настраиваем IDefics2 для нескольких сотен шагов по Llava-conv (Liu et al., 2023) и ShareGPT4V (Chen et al., 2023), с большим размером партии. Наши слепые оценки человека показывают, что IDEFICS2-Chatty является в подавляющем большинстве предпочтительнее, чем в своей инструкции, настраиваемой версии во многих пользовательских взаимодействиях. Мы также задержали на состязании стресс модель для создания неточных, смещенных или оскорбительных ответов, и сообщили о результатах в Приложении A.4. Мы показываем примеры поколений с IDEFICS2-Chatty на рисунке 1 и в приложении на рисунках 5, 6 и 7.
Авторы:
(1) Хьюго Лоренсон, обнимающееся лицо и Sorbonne Université, (порядок был выбран случайным образом);
(2) Léo Tronchon, обнимающее лицо (порядок был выбран случайным образом);
(3) шнур Matthieu, 2Sorbonne Université;
(4) Виктор Сан, обнимающееся лицо.
Эта статья есть
[3] https://spawning.ai/
[4] https://laion.ai/blog/laion-coco/
[5] https://github.com/laion-ai/laion-safety
[6] https://huggingface.co/datasets/pixparse/pdfa-eng-wds
[7] https://huggingface.co/datasets/wendlerc/renderedtext
[8] https://huggingface.co/datasets/huggingfacem4/the_cauldron
Оригинал