
Раскоростный набор данных: новый эталон в создании текста до музыки и движения
8 августа 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
2.1 Текст на вокальное поколение
2.2 Текст на генерацию движения
2.3 Аудио до генерации движения
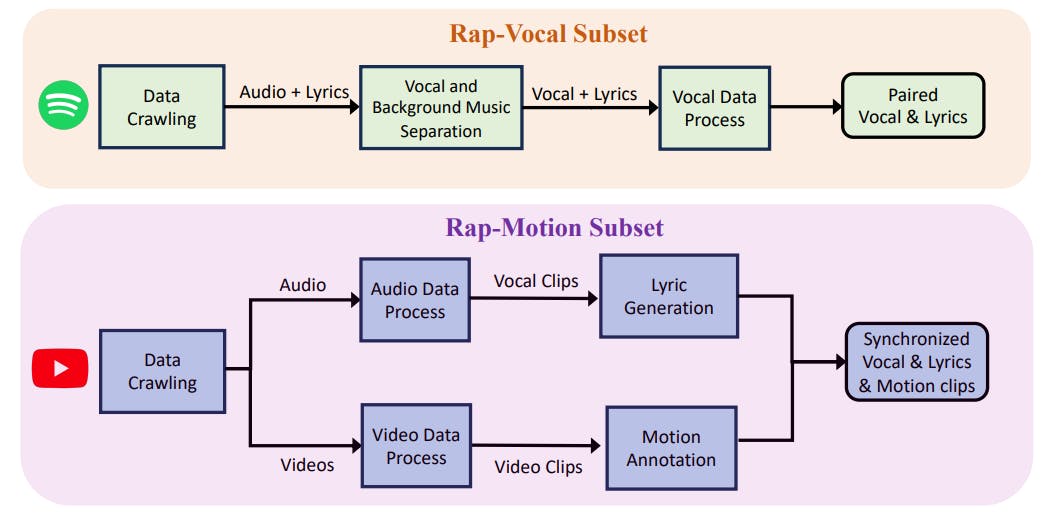
Раскоростный набор данных
3.1 Рэп-вокальное подмножество
3.2 Подмножество рэп-движения
Метод
4.1 Составление проблемы
4.2 Motion VQ-VAE Tokenizer
4.3 Vocal2Unit Audio Tokenizer
4.4 Общее авторегрессивное моделирование
Эксперименты
5.1 Экспериментальная установка
5.2 Анализ основных результатов и 5.3 исследование абляции
Заключение и ссылки
А. Приложение
2 Связанная работа
2.1 Текст на вокальное поколение
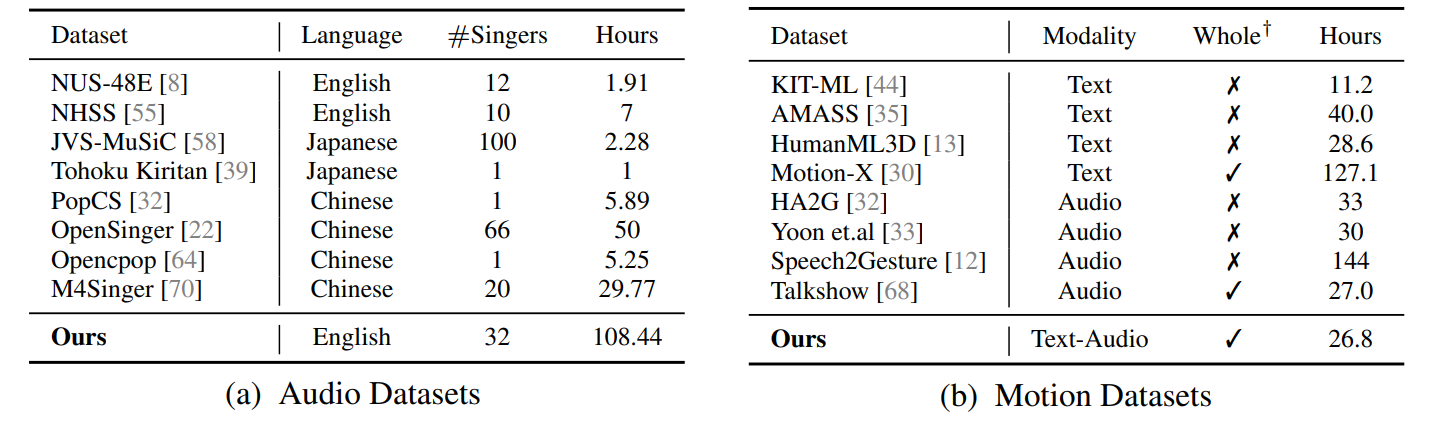
Набор данных текста в Аул.Существует несколько поющих вокальных наборов данных, но у каждого из них есть ограничения. Например, POPCS [32] и Openensinger [22] ограничены китайцами, в то время как NUS-48E [8] и NHSS [55] имеют всего несколько часов песен. Тем не менее, JVS-MUSIC [58] и NUS-48E [8] предлагают несколько часов песен от десятков певцов, тогда как OpenSinger [22] предоставляет более обширную коллекцию с десятками часов от одного певца. Примечательно, что наш набор данных представляет собой первый, который был специально курирован для рэп -песен нескольких певцов с 108 часами.
Текстовые модели.Последние достижения в моделях текста в речь (TTS), включая Wavnet [40], Fastspeech 1 и 2 [52, 51] и Eats [7], значительно улучшили качество синтезированной речи. Тем не менее, пение синтеза голоса (SVS) представляет собой большую проблему из -за его зависимости от дополнительных музыкальных результатов и текстов. Последние модели поколения [32, 16, 16, 74, 26] превосходно работают в создании пения. Тем не менее, их производительность имеет тенденцию ухудшаться при столкновении с данными за пределами распределения. Чтобы справиться с этим, Stylesinger [73] представляет адаптер остаточного стиля и нормализацию слоя моделирования неопределенности, чтобы справиться с этим.
2.2 Текст на генерацию движения
Набор данных текста к движению.Текущие наборы данных о текстовом движении, такие как Kit [44], Amass [35] и HumanML3D [13], ограничены ограниченным охватом данных, обычно охватывая всего десятки часов и отсутствуют представления движения всего тела. Чтобы преодолеть эти недостатки, был разработан Motion-X [30], обеспечивающий обширный набор данных, который охватывает движения всего тела.
Текст-модели модели.Модели текста к движению [43, 71, 14, 13, 34, 4] приобрели популярность за удобство пользователя. Недавние достижения были сосредоточены на диффузионных моделях [71, 25, 61], которые, в отличие от детерминированных моделей генерации [2, 11], позволяют тонкозернистым и разнообразным выработке. Chen et al. [4] предложили диффузионную модель на основе скрытого движения для повышения качества генерации и снижения вычислительных затрат. Тем не менее, смещение между естественным языком и движениями человека представляет проблемы. Lu et al. [34] представили основу для создания движения целого тела, чтобы решить эти проблемы, генерируя высококачественные, разнообразные и когерентные выражения лица, жесты рук и движения тела одновременно.
2.3 Аудио до генерации движения
Набор данных аудио-движения. Наборы с речью могут быть классифицированы на 1: Псевдо-меченное (PGT) и 2: Captured (MOCAP). Наборы данных PGT [3, 15, 12, 68] Используйте отключенные 2 -е или 3D -ключевые точки к
Представляйте тело, позволяя извлекать по более низкой стоимости, но с ограниченной точностью. С другой стороны, наборы данных MOCAP предоставляют аннотации для ограниченных частей тела, при этом некоторые фокусируются исключительно на голове [9, 5, 65] или корпусе [57, 10]. В отличие от них, Beatx [31] содержит сетку данных как головы, так и тела. Тем не менее, эти наборы данных обычно фокусируются на речи к генерации движения. Наш Rapverse, напротив, содержит парные данные текстового вокального движения, обеспечивая одновременное движение и вокальное поколение.
Аудио-модели модели.Модели аудио-движения [59, 56, 72, 31, 68] стремятся произвести человеческое движение из аудиоинтионов. Признавая сложные отношения между аудио и человеческим лицом, Talkshow [68] отдельно генерирует части лица и другие части тела. Однако этот подход демонстрирует ограничения, такие как отсутствие генерации нижнего тела и глобального движения. Emage [31] использует жесты в масках вместе с вокалом для поколения. Наша модель, однако, идет на шаг дальше, будучи первой, которая генерирует парные аудио-мощные данные непосредственно из текста.
Авторы:
(1) Цзябен Чен, Университет штата Массачусетс Амхерст;
(2) Синь Ян, Университет Ухана;
(3) Ихан Чен, Университет Ухан;
(4) Сиюань Сен, Университет штата Массачусетс Амхерст;
(5) Qinwei MA, Университет Цинхуа;
(6) Хаою Чжэнь, Университет Шанхай Цзяо Тонг;
(7) Каижи Цянь, MIT-IBM Watson AI Lab;
(8) ложь Лу, Dolby Laboratories;
(9) Чуан Ган, Университет штата Массачусетс Амхерст.
Эта статья есть
Оригинал