
Темная сторона AI тонкой настройки
10 июня 2025 г.Таблица ссылок
- Аннотация и введение
- Связанная работа
- Эксперименты
- 3.1 Дизайн
- 3.2 Результаты
- 3.3 Сравнение 2: Настраиваемые и настройки
- 3.4 Сравнение 3: Настройка инструкции и настройки сообщества
- Дискуссия
- Ограничения и будущая работа
- Заключение, подтверждение и раскрытие финансирования и ссылки
А. Модели оцениваются
B. Данные и код
Neurips Paper Checklist
2 Связанная работа
Модели с тонкой настройкойПолем Поскольку модели трансформаторов стали более широко доступными для разработчиков, был увеличен интерес к моделям тонкой настройки, часто на наборах инструкций, чтобы продемонстрировать, как модель должна реагировать на различные типы запросов (известный как «настройка инструкции») (Ouyang et al., 2022; Zhang et al., 2024). Было показано, что настройка инструкций позволяет относительно небольшим открытым моделям для достижения улучшенной производительности по сравнению с базовыми моделями по указанным задачам, таким как фактическая способность (Tian et al., 2023). Тем не менее, (Y. Wang et al., 2023) демонстрируют, что, хотя настройка инструкции на конкретных наборах данных может способствовать конкретным навыкам, ни один набор данных не обеспечивает оптимальную производительность во всех возможностях. Авторы обнаруживают, что точная настройка наборов данных может ухудшить производительность на контрольных показателях, не представленных в наборах данных настройки инструкций, вероятно, из-за «забывания». Предыдущие работы изучали проблемы забывания, с Luo et al. Обнаружение того, что меньшие модели (от 1 до 7 миллиардов параметров по размеру) более подвержены забыванию по сравнению с более крупными моделями (Luo et al., 2024; Zhao et al., 2024). Тем не менее, было показано, что Lora Fine-Tuning «забывает меньше» информацию за пределами целевой домены с тонкой настройкой по сравнению с полной точной настройкой (Biderman et al., 2024). Эти результаты указывают на то, что тонкая настройка может оказать непреднамеренное влияние на свойства модели, однако тонкая настройка Лора может быть менее восприимчивой к проблеме забывания.
Безопасность и тонкая настройкаПолем Точная настройка может использоваться для повышения эффективности безопасности моделей. Документация для PHI-3, LLAMA-3 и GEMMA все описывает, как смягчения после тренировки, такие как тонкая настройка, повышают эффективность безопасности (Bilenko, 2024; Gemma Team et al., 2024; Meta, 2024). Тем не менее, предыдущие эксперименты показали, как тонкая настройка может повлиять на свойства безопасности моделей. Было продемонстрировано небольшое количество состязательных примеров, чтобы отменить настройку безопасности в якобы выровненных языковых моделях (Lermen et al., 2023; Qi et al., 2023; Yang et al., 2023; Zhan et al., 2024). Способность отменить настройку безопасности была продемонстрирована на моделях, варьирующихся от небольших открытых моделей до крупных проприетарных моделей, которые обеспечивают тонкую настройку, такие как GPT-4 (Qi et al., 2023; Zhan et al., 2024). Было продемонстрировано, что состязательная точная настройка обеспечивает личную идентифицируемую информацию (PII) и облегчает отравление моделями для манипулирования поведением модели (Sun et al., 2024; Wan et al., 2023).
Исследования показали, что воздействие на свойства безопасности не всегда преднамеренные и не требуют затрат на полнопараметрическую точную настройку. (He et al., 2024; Kumar et al., 2024; Qi et al., 2023) демонстрируют, что точная настройка на доброкачественные наборы данных может отменить смягчение безопасности на моделях, включая Llama-2-7b и GPT-3.5. Также было продемонстрировано более эффективные формы тонкой настройки, такие как адаптация с низким уровнем ранга (LORA), позволяют регулировать свойства безопасности моделей, несмотря на то, что они взаимодействуют только с подмножеством параметров модели (Lermen et al., 2023; Liu et al., 2024). Тем не менее, эти эксперименты часто проводились на мелкомасштабных и не рассматривали, как может проявляться точная настраиваемая воздействие в моделях, настроенных на более низких сообщества, развернутых пользователями.
Токсичность и тонкая настройкаПолем Одним из аспектов безопасности, который подвергался обширному анализу, является вопрос токсичности, иногда называемый ненавистным или вредным языком (Davidson et al., 2017). Токсичное генерация содержания может быть оскорбительным или ненавистным текстом, выведенным языковой моделью, которая может возникнуть при вызванном или непосредственном вредном содержании. RealtoxicityPrompts - это популярный репозиторий данных, касающихся токсичности, который широко использовался для изучения модельной токсичности (Gehman et al., 2020). Действительно, была проведена работа по сравнению склонности различных языковых моделей с выводом токсического содержания (Cecchini et al., 2024; Nadeau et al., 2024). Эти типы оценки токсичности проводятся не только учеными, но и в каждой из технических документов Gemma, PHI-3 и Llama 2 сообщают информацию о показателях токсичности по моделям, демонстрируя ее важность для разработчиков модели (Gemma Team et al., 2024; Microsoft, 2024; Touvron et al., 2023).
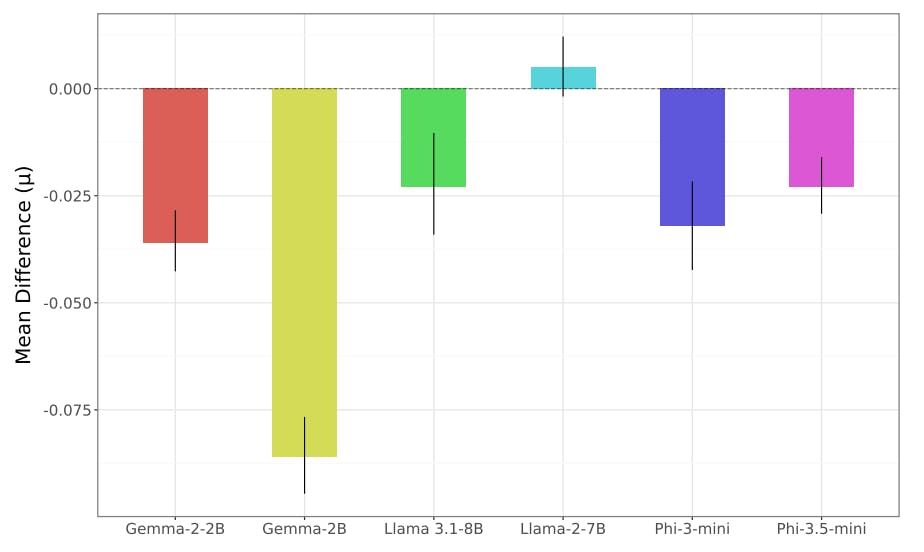
Несмотря на то, что создатели модели сообщают о показателях токсичности, чтобы продемонстрировать безопасность модели и показать, как точная настройка может улучшить показатели токсичности, было ограничено внимание на то, как тонкая настройка может отрицательно повлиять на токсичность. Это особенно важно из -за растущей простоты, с которой может быть проведена создание, и растущую популярность платформ, таких как обнимание лица. Эта работа направлена на то, чтобы заполнить этот пробел и изучить, как эффективная точная настройка параметров может непреднамеренно сдвинуть метрики токсичности на широкий спектр моделей и настраиваемых сообществ.
Авторы:
(1) Уилл Хокинс, Оксфордский интернет -институт Оксфордского университета;
(2) Брент Миттельштадт, Оксфордский институт Интернета в Оксфордском университете;
(3) Крис Рассел, Оксфордский интернет -институт Оксфордского университета.
Эта статья естьДоступно на ArxivПо лицензии CC 4.0.
Оригинал