

Обучение ИИ сказать «я не знаю»: четырехэтапное руководство по вменению контекстуальных данных
2 июля 2025 г.Авторы:
(1) Ахатшам Хаят, кафедра электрической и компьютерной инженерии, Университет Небраски-Линкольна (aahatsham2@huskers.unl.edu);
(2) Мохаммад Рашедул Хасан, кафедра электрической и компьютерной инженерии, Университет Небраски-Линкольна (hasan@unl.edu).
Таблица ссылок
Аннотация и 1 введение
2 метод
2.1 Составление проблем и 2.2 Схемы отсутствия.
2.3. Создание пропущенных значений
2.4 Описание претензии
3 эксперименты
3.1 Результаты
4 Связанная работа
5 Заключение и будущие направления
6 Ограничения и ссылки
2 метод
2.1 Составление проблемы

2.2 Образцы пропавших
Мы представляем механизм отсутствующих данных как условное распределение M, данное x, которое параметризовано неизвестным ϕ, следующим образом.
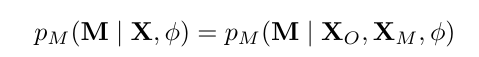
В литературе определены следующие три стандартных механизмы для пропущенных данных [21].
Отсутствует полностью случайным образом (MCAR).Случай MCAR происходит, когда вероятность того, что значение переменной отсутствует, не зависит от самой переменной и любых других переменных, выраженных следующим образом.
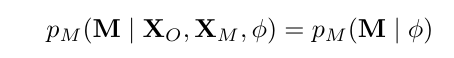
В MCAR вероятность отсутствия не зависит ни от отсутствующей переменной, ни от наблюдаемых переменных.
Отсутствует случайно (март).Вероятность того, что значение переменной отсутствует, зависит только от наблюдаемых значений других переменных xo. Таким образом, отсутствие не зависит от отсутствующих переменных, и отсутствующее значение предсказуемо из наблюдаемых переменных, формализованных следующим образом.
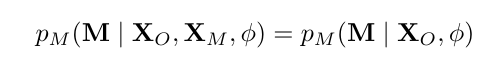
Отсутствует не случайно (MNAR).Этот случай соответствует отсутствующим механизмам, которые не являются ни макаром, ни Мар. В MNAR причина отсутствия значения может зависеть от других переменных, а также от отсутствующего значения.
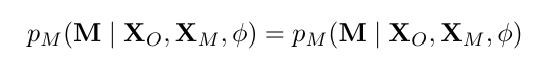
В отличие от MAR, пропавность в MNAR не может быть предсказана только из наблюдаемых переменных. Не существует общего метода обработки MNAR отсутствующих данных [14].
Часто причины пропущенных данных игнорируются, когда пропавность связана с MCAR или MAR, поэтому методы вменения могут быть упрощены [33]. По этой причине большинство исследований охватывает случаи, когда отсутствующие данные относятся к MAR или типу MCAR.
2.3. Создание пропущенных значений
Мы построили синтетические наборы данных с пропущенными до 30% значениями, применяя следующие три механизма недостания на полных наборах данных: MCAR, MAR и MNAR. Реализации этих механизмов изменяются из [20].
МакарПолем Он был введен путем случайного удаления 30% наблюдений из каждой функции.
МартаПолем Во-первых, мы выбираем все наблюдения в диапазоне 30-го процентиля независимой функции (обычно первый столбец в наборе данных). Затем мы случайным образом удаляем 60% наблюдений из каждой соответствующей (зависимой) функции.
МнарПолем Мы удаляем наблюдения функции, если наблюдения попадают в диапазон 30-го процентиля значения признака.
2.4 Описание претензии
На рисунке 1 иллюстрирует процесс претензии, который охватывает четыре этапа: (1) Создание контекстуализированного набора данных естественного языка, (2) генерируя подходящие дескрипторы для
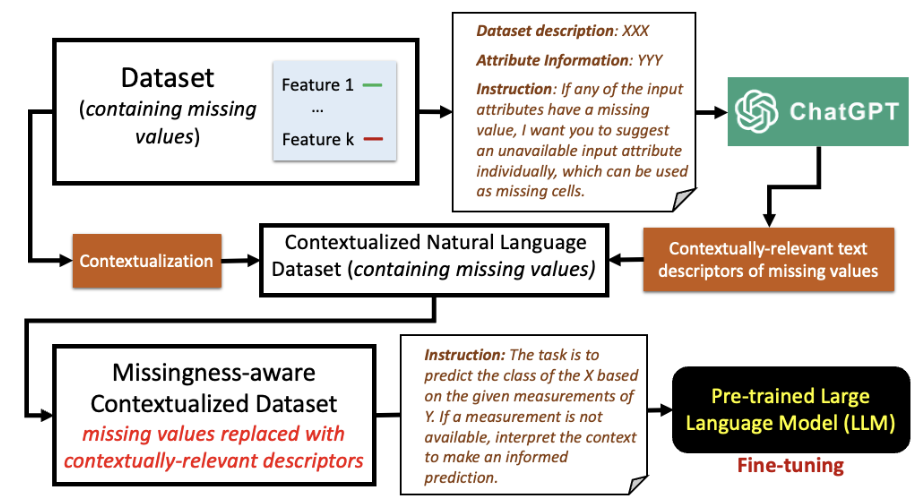
Отсутствующие значения, (3) создание контекстуализированного набора данных с учетом отсутствия недостания и (4) адаптации LLM для нижестоящих задач. Мы подробно описываем эти этапы ниже.
Создание контекстуализированного набора данных естественного языка.Мы строим контекстуализированный набор данных естественного языка из числового набора данных x, содержащего недостающие значения. Цель состоит в том, чтобы генерировать контекстуально подходящее описание каждого атрибута и его меры на естественном языке. Например, запись из набора данных вина UCI [12] с числовыми атрибутами ввода и вывода контекстуализирована следующим образом:«Содержание алкоголя в вине составляет 12,47. Уровень яловой кислоты в вине составляет 1,52 ... класс вина классифицируется как вино 1 класса».[1] Этот шаг преобразует числовые значения в подробные описания, подготавливая набор данных для внедрения дескрипторов отсутствующих значений.
Генерирование подходящих дескрипторов для пропущенных значений.В отличие от традиционных методов вменения, которые оценивают пропущенные значения из наблюдаемых данных с использованием численных методов, мы используем контекстно-релевантные дескрипторы пропущенных значений для вменения. Мы генерируем эти дескрипторы с помощью разговорного LLM (например, CHATGPT-3.5 OpenAI [2]). Мы предпринимаем LLM с описанием набора данных и инструктируем его генерировать дескрипторы пропущенных значений, такие как:«Для любых пропущенных значений атрибутов предложите дескриптор для отсутствующих данных, которые я могу разместить в этих ячейках».Этот метод опирается на обширную базу знаний LLM для создания соответствующих дескрипторов пропущенных значений. Список специфических для контекстных релевантных дескрипторов недостающих значений для выбранных наборов данных представлен в приложении.
Создание контекстуализированного набора данных с отсутствием.Мы построим контекстуализированный набор данных естественного языка, знаящий недостаток, xmissingsing_aware, заменив пропущенные значения сгенерированными дескрипторами. Этот процесс гарантирует, что каждый экземпляр данных знает о его отсутствующих атрибутах, таким образом, способным улучшить способность LLM учиться на неполных данных, предоставляя явный контекст. Кроме того, мы используем различные дескрипторы для отдельных функций в наборе данных, которые содержат недостающие значения, тем самым неявно информируя LLM для обработки недостания каждой функции контекстуально подходящим способом для повышения производительности задачи нижнего потока.
Адаптация LLM для решения вниз по течению задач.Последний шаг включает в себя создание предварительно обученного LLM с помощью набора данных, богатого контекстами. Мы включаем конкретные инструкции и стратегии для обработки пропущенных данных в процесс тонкой настройки. Например, для задач классификации мы могли бы включить такие инструкции, как:«Прогнозируйте класс на основе заданных измерений. Используйте контекст, предоставляемый пропущенными дескрипторами стоимости, чтобы информировать о вашем прогнозе».
Этот структурированный подход, от преобразования наборов данных до тонкой настройки LLMS, означает комплексный метод решения недостащения данных посредством возможностей LLMS.
Эта статья естьДоступно на Arxivв соответствии с CC по 4.0 Deed (Attribution 4.0 International) лицензия.
[1] Сценарий Python, используемый для контекстуализации, представлен в дополнительном материале.
Оригинал