

Sutra превосходит ведущие LLM на многоязычном эталонном эталоне MMLU
27 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 подход сутры
3.1 Что такое сутра?
3.2 Архитектура
3.3 Данные обучения
4 тренинги многоязычных токенизаторов
5 многоязычных MMLU
5.1 Массивное многозадачное понимание языка
5.2 Расширение MMLU на несколько языков и 5.3 последовательная производительность между языками
5.4 по сравнению с ведущими моделями для многоязычной производительности
6 Количественная оценка запросов в реальном времени
7 Обсуждение и заключение, а также ссылки
5.4 по сравнению с ведущими моделями для многоязычной производительности
Для нашей оценки мы используем несколько современных моделей и сравниваем их производительность по многоязычному эталону MMLU, как показано в таблице 6. Мы рассмотрели несколько ведущих моделей, таких как GPT-4 и GPT-3.5 от Openai,
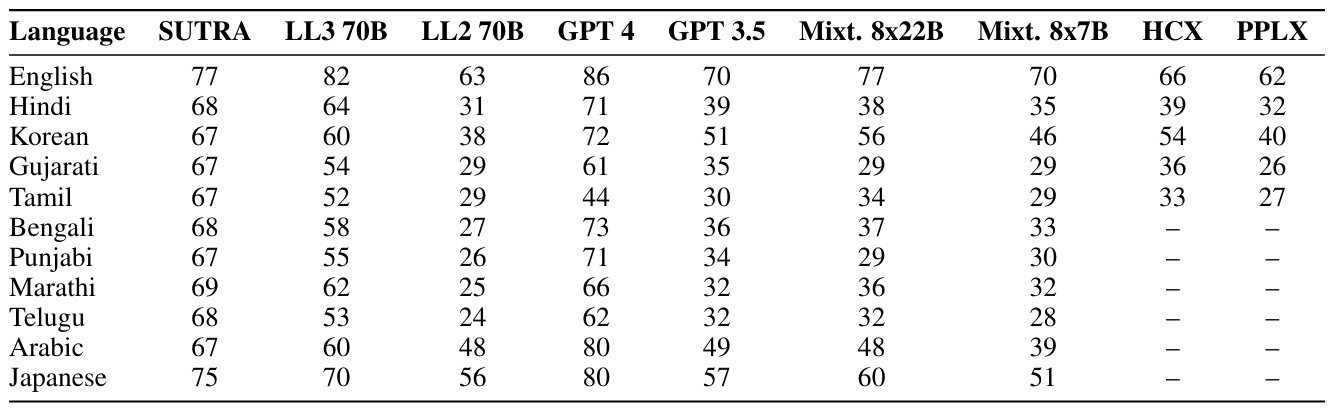
Mixtral-8x7b от Mistral, Llama2-13b, Llama2-70b и Llama3-70b от Meta, сонар-медий от недоумения, гиперкловакс от Naver и модель Airavata от Sarvam ai. Из них GPT-4, GPT-3.5, Mixtral, Llama Series и Nemplexity являются общими моделями, то есть они не были обучены оптимизировать для определенных языков. HyperClovax был специально обучен оптимизировать производительность на корейском языке, в то время как Airavata была специально обучена оптимизировать производительность на хинди.
В целом, результаты оценки показывают, что наши модели Sutra могут соответствовать и даже превосходить GPT-3.5 и Llama-7b в двух связанных случаях использования, особенно для предоставления естественных и привлекательных ответов между языками. Хотя GPT-4 по-прежнему является современным с точки зрения производительности, стоимость по-прежнему остается основным препятствием для широкомасштабного развертывания на чувствительных к стоимости рынках. Превосходная многоязычная производительность GPT-3,5 на 20-30% по ведущему эталону MMLU, модели Sutra преуспевают в понимании и генерировании ответов на многочисленных языках. Мы обнаруживаем, что Sutra преуспевает даже по сравнению с моделями, которые были специально оптимизированы для конкретного языка, демонстрируя перспективу для подхода, за которым следует сутра, как показано в таблице 7. Более подробные результаты, показывающие оценки MMLU по группам категорий, таких как стволование, гуманитарные науки и т. Д., Имеются в таблице 8.
![Table 7: The above table shows comparison of language specific LLMs for multiple languages such as Hindi [Gala et al., 2024], Korean [Son et al., 2024], Arabic [Sengupta et al., 2023] and Japanese [Group et al., 2024]. The selected models are best performing models on respective languages, as they were purposely built and tuned for those languages. Shown on the right is MMLU score for SUTRA on respective languages. From the performance numbers it is evident that the concept and language modeling approach followed by SUTRA yields superior multilingual performance.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-sc934ba.png)
Авторы:
(1) Абхиджит Бендейл, две платформы (abhijit@two.ai);
(2) Майкл Сапенза, две платформы (michael@two.ai);
(3) Стивен Рипплингер, две платформы (steven@two.ai);
(4) Саймон Гиббс, две платформы (simon@two.ai);
(5) Jaewon Lee, две платформы (jaewon@two.ai);
(6) Пранав Мистри, две платформы (pranav@two.ai).
Эта статья есть
Оригинал