
Прекратите удалять выбросы - это то, что вы должны сделать вместо этого
31 июля 2025 г.Если вы работаете с реальными данными, вы столкнетесь с выбросами. Это странные ценности, которые находятся в нескольких милях от остальных. Возможно, клиент потратил 10 000 долларов, когда средний заказ составляет 50 долларов. Или датчик сбоялся и зарегистрировал -9999.
Эти значения искажают вашу статистику и делают вывод вашего эксперимента ненадежным. А поскольку так много решений ездит на средствах (A/B -тесты, ценообразование, прогнозирование), игнорирование выбросов может серьезно возиться с вашими результатами.
Это опасность. Выбросы не просто искажают ваши графики. Они отбрасывают все: доверительные интервалы, p-значения, независимо от того, отправляете ли вы функцию или убиваете ее. Если ваши решения полагаются на среднее, вам лучше знать, что скрывается в хвостах.
Хорошие новости? Вам не нужна расширенная статистика, чтобы исправить выбросы. Несколько чистой линии кода и некоторого здравого смысла будут иметь большое значение.
ОбрамлениеПроблема
Скажем, вы сравниваете две группы в эксперименте. Группа А имеет среднюю стоимость заказа 10 долларов США, группа B составляет 12 долларов. Похоже, тестовая группа становится лучше, но оба включают выбросы. Эти экстремальные значения искажают среднее и стандартное отклонение, что делает разницу от 10 до 12 долларов труднее доверять.
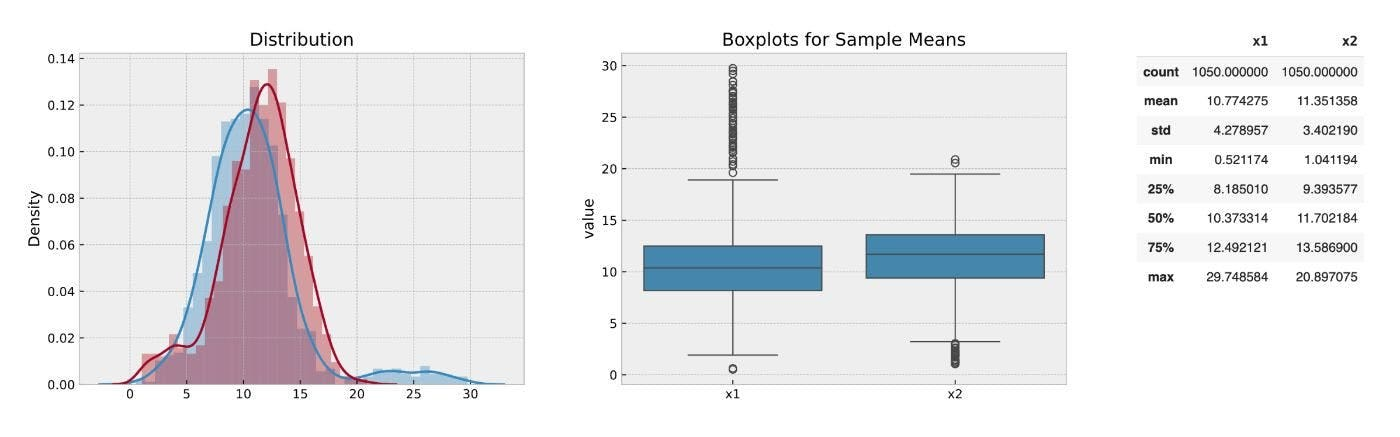
Вот как генерировать синтетическую версию этой проблемы:
import numpy as np
N = 1000
# Group A: mean 10, with some large outliers
x1 = np.concatenate((
np.random.normal(10, 3, N), # Normal distribution
10 * np.random.random_sample(50) + 20 # Outliers: values between 20–30
))
# Group B: mean 12, with some moderate outliers
x2 = np.concatenate((
np.random.normal(12, 3, N), # Normal distribution
4 * np.random.random_sample(50) + 1 # Outliers: values between 1–5
))
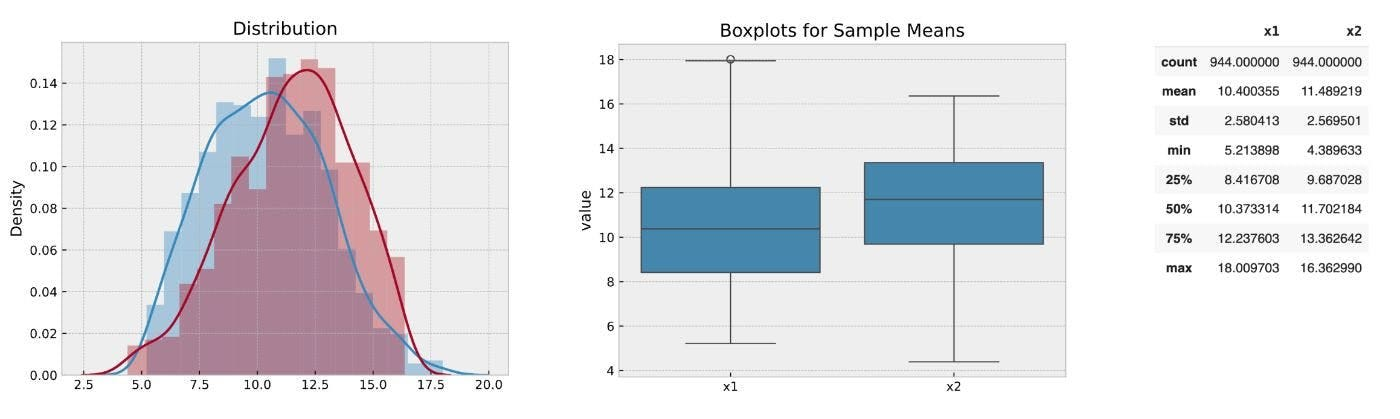
Метод 1: обрезать хвосты
Быстрый способ исправить выбросы - это сократить крайности: удалить самые низкие 5% и самые высокие 5% значений. Конечно, вы теряете некоторые данные, но вы избавляетесь от самых странных 10%, которые обычно не добавляют ценность в любом случае.
Вот как это сделать:
low = np.percentile(x, 5)
high = np.percentile(x, 95)
x_clean = [i for i in x if low < i < high]
Сделанный. Теперь ваши средние значения не будут оттянуты этими немногими экстремальными значениями. Это тупой, но эффективный метод, который идеально подходит для быстрой очистки.
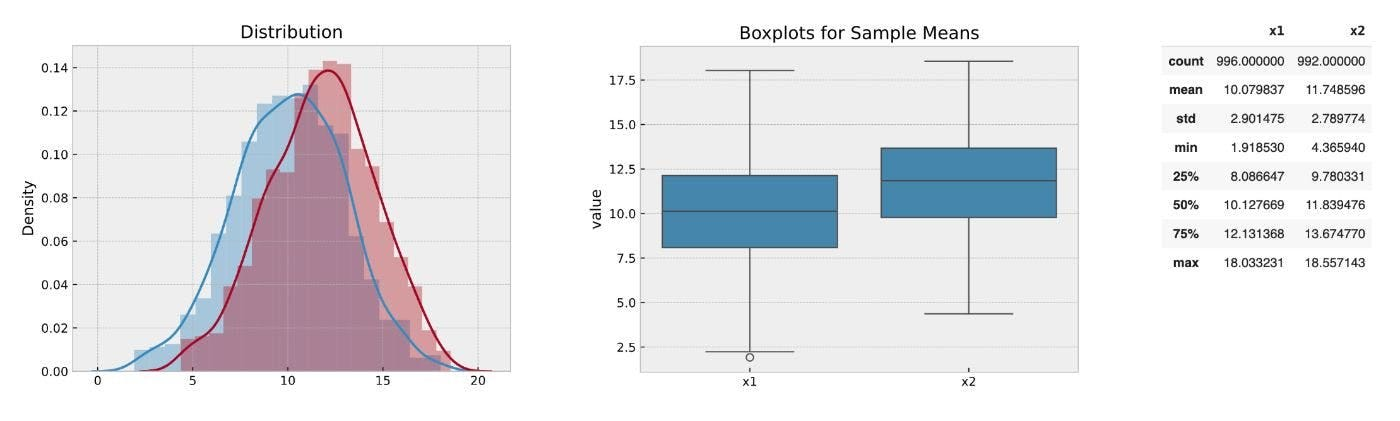
Метод 2: Используйте полосы IQR
Другой подход заключается в исключении значений за пределами диапазона, основанного на межквартильном диапазоне (IQR). В частности, вы падаете что -либо ниже 25 -го процентиля минус в 1,5 раза превышают стандартное отклонение или выше 75 -го процентиля плюс в 1,5 раза превышают стандартное отклонение.
Этот метод обычно удаляет только около 1,0% данных, но уменьшает распределение и повышает точность ваших оценок. Это солидный способ отфильтровать экстремальные значения, не выбрасывая слишком много информации.
Вот как это сделать:
Q1 = np.percentile(x, 25)
Q3 = np.percentile(x, 75)
low = Q1 - 1.5 * np.std(x)
high = Q3 + 1.5 * np.std(x)
x_clean = [i for i in x if low < i < high]
Метод 3: начальная загрузка
Иногда самый умный ход - вообще не удалять что -либо. Вместо этого используйте начальную загрузку, чтобы сгладить шум. Вы повсеместно выбираете свои данные с заменой кучу раз, каждый раз вычисляете среднее значение и используете среднее из них. Это часто дает более стабильную оценку среднего значения, даже если выбросы остаются в данных.
Для наборов данных с неизбежными выбросами (например, дохода или поведения пользователя) начальная загрузка дает вам лучшее представление о «типичном» результате, не решая, что оставить или бросить. Это вычислительно дешево и удивительно мощно.
Вот как применить начальную загрузку к вашим данным:
def bootstrap_mean(x, n=1000):
return np.mean([np.mean(np.random.choice(x, size=len(x), replace=True)) for _ in range(n)])
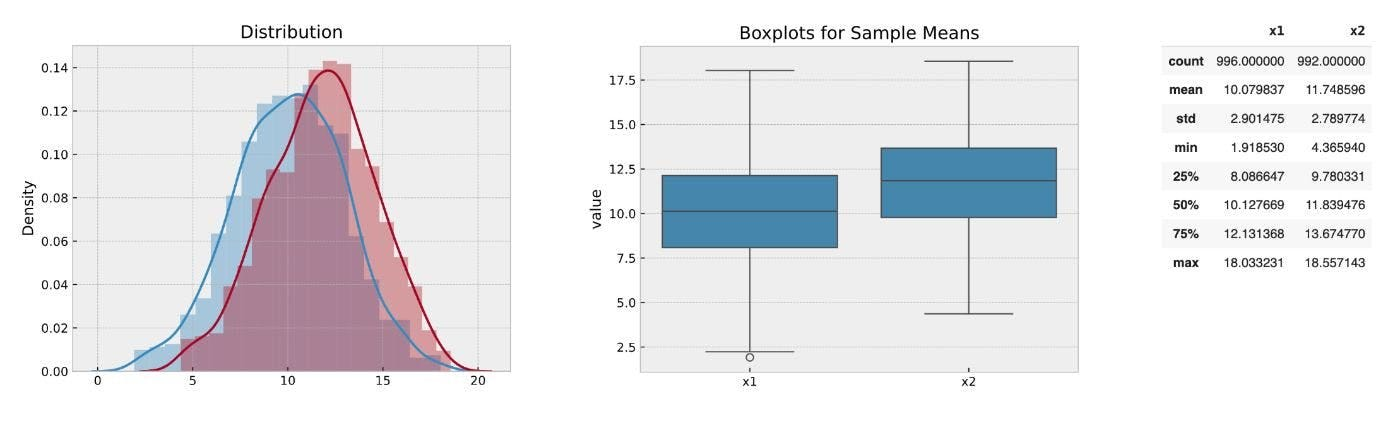
Какой из них вы должны использовать?
- Обрежьте хвосты: Быстро, просто, агрессивно. Используйте его, когда вы знаете, что ваши крайности являются мусором или вам нужна быстрая очистка.
- Метод IQR: Сбалансированный, статистически здоровый. Используйте его, если вы хотите, чтобы статистика был определяемым способом фильтрации шума без резки до глубокого в данных.
- Начальная загрузка: Нет фильтрации, лучшие центральные оценки. Используйте его, когда удаление значений не является опцией или когда ваши данные естественным образом включают редкие, но экстремальные экстремальные.
Не задумывайтесь над этим. Попробуйте все три метода и сравните средние значения и отклонения. Вы быстро увидите, что даст вам самый стабильный, заслуживающий доверия результат. Речь идет не о совершенстве, а о использовании правильного инструмента для работы.
Общие ловушки, которых следует избегать
Здесь люди испортят: они слепо удаляют все, что выглядит странно. Не делай этого. Всегда проверяйте, что вы сокращаете. Этот заказ в размере 9000 долларов может быть редким - но законным. Отбрасывание выбросов без контекста может стереть реальные сигналы или создать слепые пятна.
Если вы автоматически удаляете все, что не соответствует вашим ожиданиям, вы рискуете отфильтировать точную вещь, которую вы должны расследовать.
Выбросы могут быть ранними предупреждениями, новыми тенденциями или краями, которые превращаются в идеи продукта. Относитесь к ним как к подсказкам, а не к мусору.
Кроме того, перестаньте полагаться только на среднее значение. Это хрупкое. Всего несколько выбросов могут полностью его сбросить. ИспользуйтемедианаилиподстриженоКогда все выглядит грязным. И всегда - серьезно, всегда - сначала постройте ваши данные. Быстрая гистограмма или ящик не дадут вам делать глупые предположения.
Окончательная мысль
Выбросы не проблема. Неправильно их прочитать. Иногда они мусор. В других случаях они сигнализируют, что вы не ожидали. Ваша работа не в том, чтобы слепо разрезать их, это выяснить, что они на самом деле имеют в виду.
Используйте приведенные выше методы, когда вам нужны чистые, надежные данные. Но не игнорируйте, что выбросы могут вам сказать.
Они могут указывать на ошибку ... или на вашу следующую большую возможность.
Ваша работа - узнать разницу.
Оригинал