

Решение вопросов для собеседования с аналитиком данных Noom
9 ноября 2022 г.Noom помогает похудеть. Мы поможем вам устроиться на работу в Noom. В сегодняшней статье мы покажем вам один из сложных вопросов Noom на собеседовании по SQL.
Мы привыкли выбирать сложные вопросы для интервью с аналитиком данных для вас. Это наверное не плохо. Если вам удастся ответить на эти вопросы, то вопросы среднего и легкого уровня будут для вас пустяком.
Кусок пирога, который мы не отговариваем вас есть. Это бизнес Noom как приложения для фитнеса и похудения на основе подписки. Наша миссия здесь состоит в том, чтобы сделать вас пригодными, но только с точки зрения ваших навыков кодирования SQL.
Интервью, которое мы рассмотрим, является прекрасным примером использования JOIN и агрегировать функции более сложным способом, который включает в себя написание подзапросов.
Мы рассмотрим все объяснения шаг за шагом, чтобы их было легко понять. Если что-то становится слишком сложным, вы всегда можете помочь себе с помощью нашего видеоурока, в котором рассматривается тот же вопрос.
Вопрос интервью с аналитиком данных Noom
Вот вопрос, на который мы покажем вам, как ответить:
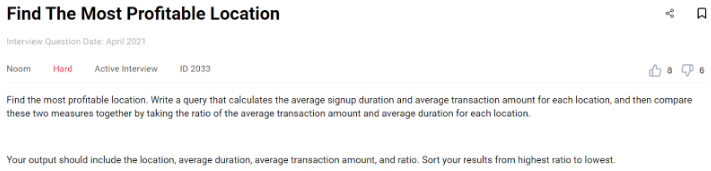
Ссылка на вопрос: https:/ /platform.stratascratch.com/coding/2033-найти-самое-доходное-местоположение
Чтобы найти наиболее выгодное местоположение, компания хочет сравнить среднюю продолжительность регистрации и среднюю сумму транзакции для каждого местоположения, взяв соотношение между ними.
Они ожидают, что вы предоставите таблицу с описанием каждого местоположения, средней продолжительности, средней суммы транзакции и коэффициента. Результат должен быть отсортирован от наибольшего отношения к наименьшему.
Теперь было бы неразумно сразу переходить к написанию кода и надеяться, что вы каким-то образом найдете решение. Стратегия важна так же, как и ваше знание SQL. Стратегия здесь включает в себя основу для решения этого и других вопросов интервью аналитика данных SQL.
Структура подхода к решению (Noom) вопроса интервью с аналитиком данных

Мы будем использовать трехэтапную структуру, которая поможет вам решить сложную проблему и упростить ее до нескольких шагов. Если вы наш постоянный читатель, вы, вероятно, знакомы с ним.
Для тех из вас, кто плохо знаком с этим или нуждается в повторении, три шага:
- Изучение набора данных
- Написание подхода
- Кодирование решения
Во-первых, вам нужно понять набор данных. Это означает понимание столбцов в таблицах, их типов данных и того, что эти данные представляют на самом деле. Кроме того, следите за ловушками, скрытыми в данных, которые могут привести к учету пограничных случаев при написании решения.
Когда вы закончите с этим шагом, вы должны наметить шаги, которые вы предпримете для решения проблемы. Нет, вы еще не кодируете! Вы всего лишь записываете свой подход в виде предложений или псевдокода. Здесь вы создаете каркас своего решения, а код добавит ему плоти.
И последний шаг, которого вы, вероятно, с трудом ждали: начните программировать!
Пришло время показать вам, как эта структура работает на вопросе интервью с аналитиком данных Noom.
1. Изучение набора данных
Вам предоставлены две таблицы: регистрации и транзакции.
Первая таблица представляет собой запись регистраций и имеет следующие столбцы.

Вот некоторые важные моменты, на которые стоит обратить внимание:
- column signup_id — будем считать, что это первичный ключ таблицы
- столбцы signup_start_date и signup_stop_date — отформатированы как дата и время
- столбец plan_id — представляет тип плана и имеет целочисленный формат
- расположение столбца — показывает город пользователя, значения могут повторяться
Обычно у вас нет возможности просмотреть данные во время интервью. Но раз у нас есть, почему бы не использовать этот вариант?
Вот пример данных из первой таблицы.
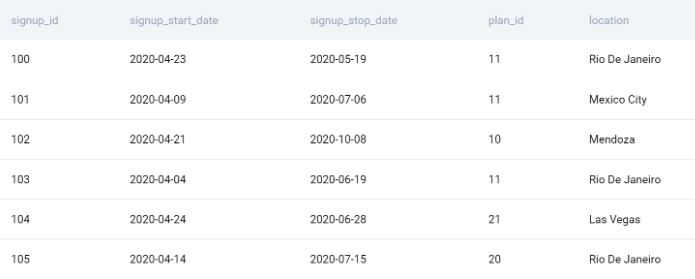
Не совсем понятно, что означают даты начала и окончания регистрации. Это даты, когда клиент зарегистрировался на платформе/покинул ее, или дата, когда он подписался на план/отменил подписку? Во время интервью это идеальный шанс задать эти вопросы в интервью. У нас нет такой возможности, поэтому мы предполагаем, что даты начала и окончания показывают, когда клиент подписался и отменил свой план.
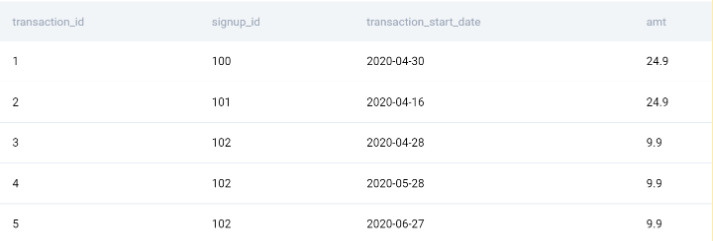
Вторая таблица, transactions, содержит эти столбцы.

Из этого мы можем сделать следующее.
- column transaction_id — первичный ключ таблицы
- column signup_id — тот же столбец, что и в первой таблице, что означает, что это внешний ключ
- столбец transaction_start_date — эта дата также отформатирована как дата и время
- столбец amt — должна быть сумма, относящаяся к транзакции
Посмотрите на предварительный просмотр таблицы.
Как две таблицы работают вместе? Понимание этого в основном откроет, как работает Noom.
Когда клиенты регистрируются, им присваивается уникальный идентификатор регистрации (столбец signup_id), а запись записывается в таблицу signups. Эта запись также включает даты, когда они подписались на свой план и отменили его (столбцы signup_start_date и signup_stop_date), тип плана, на который они подписались (столбец plan_id), и их город (расположение столбца).
Поскольку Noom предоставляет свои услуги клиенту, а клиент их оплачивает, происходит транзакция. Эта транзакция регистрируется в таблице transactions. Там каждая транзакция получает уникальный идентификатор (столбец transaction_id), который ссылается на идентификатор регистрации клиента из первой таблицы (столбец signup_id). Также есть дата (столбец transaction_start_date) и сумма, взимаемая за транзакцию (столбец amt).
Для предприятий на основе подписки, таких как Noom, с клиента обычно взимается плата на регулярной основе, например, ежемесячно. Что это означает для записей в наборе данных вопросов? Вы должны ожидать несколько транзакций за регистрацию. Другими словами, существует взаимосвязь между таблицей регистраций и таблицей транзакций: у одного клиента может быть несколько транзакций.
Уточните это у своего интервьюера! Аналогом интервьюера на нашей платформе является написание простого кода для проверки того, что мы только что сказали.
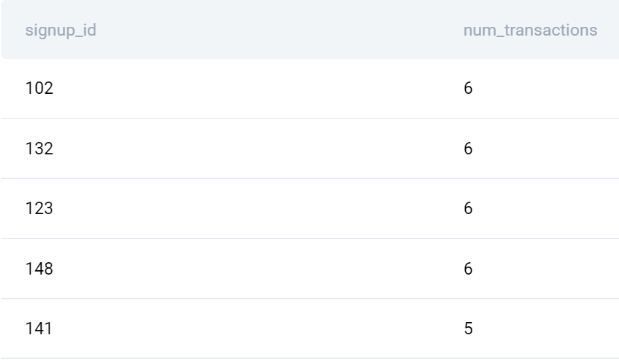
Запустите код, чтобы увидеть, что для каждого идентификатора регистрации имеется несколько записей.
SELECT
signup_id,
COUNT(transaction_id) AS num_transactions
FROM transactions
GROUP BY signup_id
ORDER BY 2 DESC;
Возвращаясь к тому, как работают подписки, когда клиент решает прекратить подписку, это отражается в обновлении столбца signup_stop_date в таблице signups.
2. Описание подхода
В этом вопросе интервью с аналитиком данных Noom вас просят указать местоположение, среднюю продолжительность, среднюю сумму транзакции и соотношение этих двух средних значений.
Теперь средние значения доступны вам не сразу. Поэтому, прежде чем отображать окончательные результаты с коэффициентом, вы должны рассчитать среднюю продолжительность и сумму транзакции для каждого местоположения.
Вот как это сделать и найти решение.
<сильный>1. Рассчитать среднюю продолжительность для каждого местоположения
Продолжительность – это разница между датами начала и окончания регистрации. С точки зрения бизнеса, это жизненный цикл клиента.
Вы можете найти все столбцы для этого расчета в таблице signups.
<сильный>2. Рассчитайте среднюю транзакцию по местоположению
Чтобы рассчитать среднюю транзакцию по местоположению, вам потребуется использовать таблицу транзакций и регистраций.
Эти две таблицы можно соединить с помощью общего столбца signup_id.
<сильный>3. Соедините две расчетные таблицы
Чтобы рассчитать соотношение, вам нужны оба средних значения в одной таблице. Использование ВНУТРЕННЕГО СОЕДИНЕНИЯ безопасно, поскольку обе вычисляемые таблицы будут иметь одинаковые местоположения.
<сильный>4. Рассчитать соотношение
Теперь, когда все необходимые данные находятся в одной таблице, можно рассчитать коэффициент. Формула:
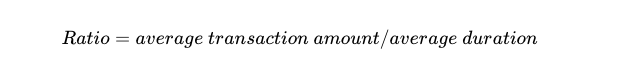
<сильный>5. Отсортируйте результаты от наибольшего к наименьшему соотношению
Чтобы отсортировать вывод, используйте ORDER BY.
При написании подхода к написанию кода рекомендуется подумать о пограничных случаях.
В этом вопросе пограничным случаем может быть то, как учитывать активных пользователей, т. е. тех, кто еще не завершил подписку на Noom. Как написать такой запрос и влияет ли этот пограничный случай на интерпретацию результатов?
Чтобы ответить на этот вопрос, важно выяснить, как система записывает даты окончания регистрации для активных клиентов.
Есть две возможности:
1. Даты окончания регистрации не указаны для активных клиентов.
Если это так, описанные выше шаги будут ошибочными. Чтобы избежать этого, вы должны сначала отфильтровать строки, в которых дата окончания регистрации не равна нулю, а затем выполнить вычисления. Таким образом, вы ограничиваете свой анализ только клиентами с установленным сроком службы.
2. В качестве даты остановки активных клиентов используется прокси-дата.
Если текущая дата указана как прокси-дата, дата окончания регистрации обновляется ежедневно.
В этом случае средняя продолжительность также меняется ежедневно, поскольку продолжительность активных пользователей увеличивается.
Это проблематично, потому что клиент, который зарегистрировался вчера, будет иметь продолжительность в один день, что является неверным представлением времени жизни клиента. Мы рекомендуем вам ограничить анализ текущими клиентами или историческими показателями, чтобы избежать искажений.
Теперь, когда вы записали все шаги, рассмотрели крайние случаи и все проверили с интервьюером, вы можете приступать к программированию.
Из предварительного просмотра таблицы видно, что даты окончания регистрации указаны для каждого клиента. Поэтому мы напишем код, предполагая, что таблица signups содержит только исторические данные.
3. Кодирование решения
Эта часть платформы просто переводит вышеуказанные шаги в код SQL.
<сильный>1. Рассчитать среднюю продолжительность для каждого местоположения
Сначала найдите разницу между датами начала и окончания. Затем используйте функцию AVG(), чтобы получить среднюю продолжительность для каждого местоположения.
SELECT location,
AVG(signup_stop_date - signup_start_date) AS mean_duration
FROM signups
GROUP BY location;
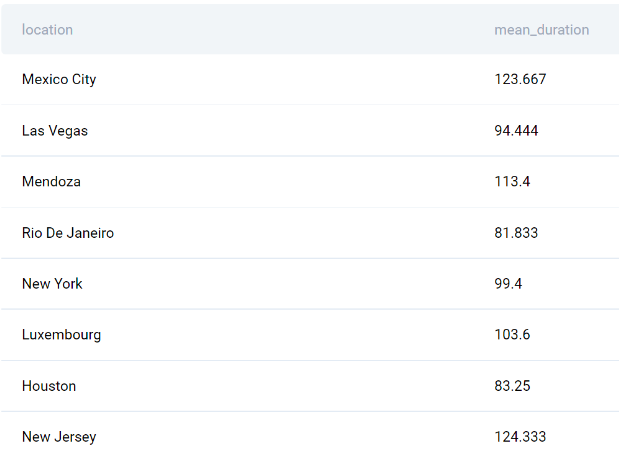
Помните, что мы заметили, что обе даты имеют формат datetime. Вот почему мы можем напрямую их вычесть.
Выходные данные этого запроса показывают все местоположения клиентов и среднюю продолжительность для каждого местоположения.
<сильный>2. Рассчитайте среднюю транзакцию по местоположению
Этот шаг не требует предварительного расчета. Все данные уже доступны; вам нужно только соединить две таблицы.
SELECT location,
AVG(amt) AS mean_revenue
FROM transactions t
JOIN signups s ON t.signup_id = s.signup_id
GROUP BY location;
Это снова местоположения, но со средним доходом вместо продолжительности.
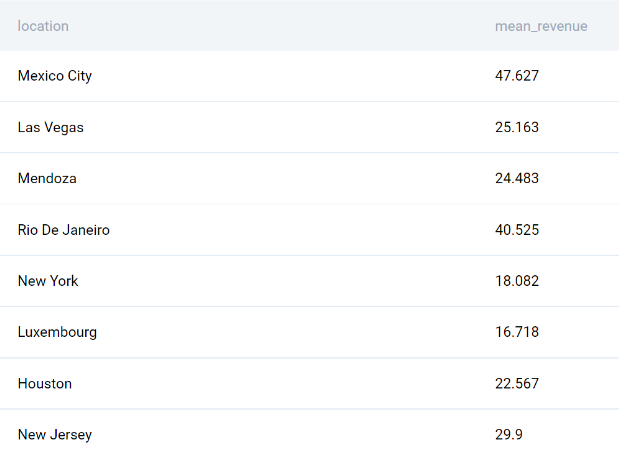
Теперь, когда у вас есть эти два средних показателя, вы можете определить целевой результат.
<сильный>3. Соедините две расчетные таблицы
Эти две таблицы будут двумя подзапросами, соединенными INNER JOIN в предложении FROM основного оператора SELECT.
SELECT dur.location,
mean_duration,
mean_revenue
FROM
(SELECT location,
AVG(signup_stop_date - signup_start_date) AS mean_duration
FROM signups
GROUP BY location) AS dur
JOIN
(SELECT location,
AVG(amt) AS mean_revenue
FROM transactions t
JOIN signups s ON t.signup_id = s.signup_id
GROUP BY location) AS rev
ON dur.location = rev.location;
В выходном коде есть почти все, что вам нужно в окончательном выводе. У вас есть все местоположения и средние значения в одной таблице. Теперь вы должны использовать их для расчета коэффициента.
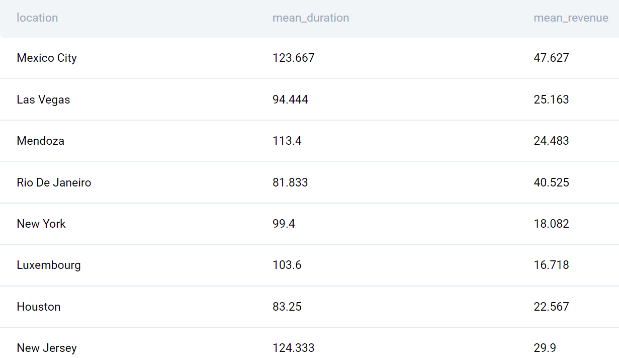
<сильный>4. Рассчитать соотношение
Соотношение – это просто отношение среднего дохода к средней продолжительности. Кроме того, преобразуйте результат деления в число с плавающей запятой, чтобы получить десятичные числа.
SELECT dur.location,
mean_duration,
mean_revenue,
mean_revenue/mean_duration::float AS ratio
FROM
(SELECT location,
AVG(signup_stop_date - signup_start_date) AS mean_duration
FROM signups
GROUP BY location) AS dur
JOIN
(SELECT location,
AVG(amt) AS mean_revenue
FROM transactions t
JOIN signups s ON t.signup_id = s.signup_id
GROUP BY location) AS rev
ON dur.location = rev.location;
Вывод такой же, как и на предыдущем шаге, за исключением того, что здесь используется соотношение для каждого местоположения.
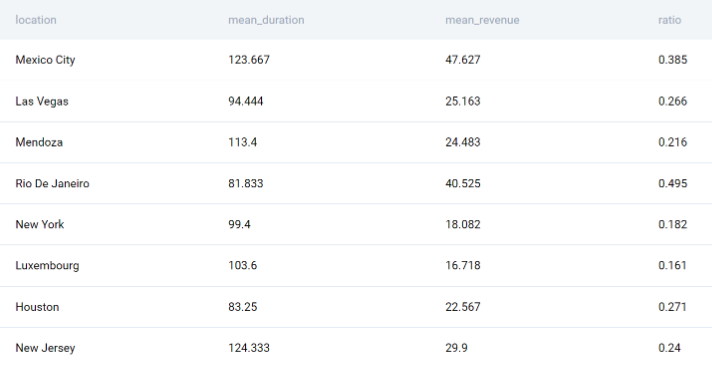
Теперь нужно только правильно отсортировать вывод.
<сильный>5. Отсортируйте результаты от наибольшего к наименьшему соотношению
В вопросе предлагается отсортировать вывод в порядке убывания по соотношению. Просто добавьте предложение ORDER BY в последнюю строку приведенного выше кода.
SELECT dur.location,
mean_duration,
mean_revenue,
mean_revenue/mean_duration::float AS ratio
FROM
(SELECT location,
AVG(signup_stop_date - signup_start_date) AS mean_duration
FROM signups
GROUP BY location) AS dur
JOIN
(SELECT location,
AVG(amt) AS mean_revenue
FROM transactions t
JOIN signups s ON t.signup_id = s.signup_id
GROUP BY location) AS rev
ON dur.location = rev.location
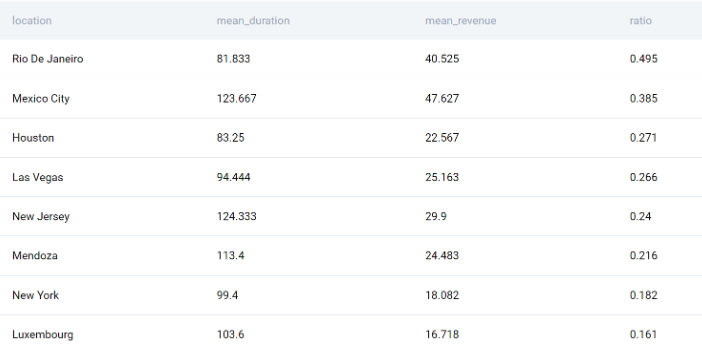
ORDER BY ratio DESC;
Написав это, вы написали ответ на вопрос Нум.
Ваш анализ показывает, что самый высокий доход в день приходится на Рио-де-Жанейро. Самый низкий показатель в Люксембурге. Кроме того, вы можете видеть, что самый высокий доход приходится на Мехико, но он распределяется на более длительный период времени.
Заключение
Надеемся, вам понравилось решать этот вопрос интервью с аналитиком данных Noom!
Мы считаем, что это действительно демонстрирует, как интервьюерам нравится использовать знакомые концепции SQL, такие как агрегация данных и JOIN, чтобы усложнить вопросы. Как только вы усвоите шаги для решения вопросов SQL и поймете, что в этом случае вам следует использовать подзапросы, написание кода станет более управляемым. Вся тяжелая работа была проделана при анализе данного набора данных и формулировании вашего подхода к кодированию.
Если вам понравился этот вопрос Noom, вы также можете попробовать решить другую аналогичную задачу Noom здесь → Вопросы для собеседования по Noom SQL.
:::информация Также опубликовано здесь.
:::
Оригинал