

Умное спутниковое зрение с несколькими выстрелами
11 июня 2025 г.Таблица ссылок
- Аннотация и введение
- Фон
- Тип данных датчика дистанционного зондирования
- Clarkmark Demote Sensing Dataets для оценки моделей обучения
- Метрики оценки для нескольких ударов дистанционного зондирования
- Недавние методы обучения в дистанционном зондировании
- Обнаружение и сегментация объекта на основе нескольких выстрелов в дистанционном зондировании
- Обсуждения
- Численные эксперименты нескольких выстрелов в наборе данных на основе БПЛА
- Объяснимый ИИ (XAI) в дистанционном зондировании
- Выводы и будущие направления
- Благодарности, декларации и ссылки
7 обнаружение и сегментацию объекта на основе нескольких выстрелов в дистанционном зондировании
В домене дистанционного зондирования большая часть основного внимания была сосредоточена на задачах классификации изображений, таких как картирование земного покрова. Тем не менее, также важно продвигать задачи зрения на более высоком уровне, такие как обнаружение объектов и семантическая сегментация, которая извлекает более богатую информацию из изображений. Например, обнаружение объектов может точно локализовать и идентифицировать транспортные средства, здания и другие сущности в сцене. Между тем, сегментация может определить границы земли, растительность, инфраструктуру и воды на уровне пикселей. Был достигнут значительный прогресс в разработке и оценке методов обнаружения объектов и сегментации для данных дистанционного зондирования. Различные тесты и соревнования были организованы с использованием крупномасштабных спутниковых и воздушных наборов данных [85, 86]. Современные модели глубокого обучения, такие как R-CNNS, SSD и маски R-CNN [17], показали сильную производительность. Тем не менее, многие из них полагаются на обширные аннотированные данные обучения, которые могут быть дорогостоящими и трудоемкими для получения в разных географических областях. Следовательно, продвижение обнаружения и сегментации объектов в дистанционном зондировании с использованием ограниченного надзора остается открытой проблемой. Несколько выстрелов предлагает многообещающий подход, позволяющий эффективно обобщать от скудных примеров обучения. В то время как некоторые первоначальные работы изучали обнаружение объектов для аэрофотоснимков [87–91], все еще отсутствует комплексный опрос, включающий последние достижения. Кроме того, до сих пор несколько выстрела в семантической сегментации до сих пор получила относительно мало внимания к дистанционному зондированию.
7.1 Обнаружение объекта с несколькими выстрелами в дистанционном зондировании
Основная задача в обнаружении объектов с несколькими выстрелами заключается в разработке модели, которая может хорошо обобщать небольшое количество примеров [92–95]. Это обычно достигается за счет использования предыдущих знаний, полученных из большого количества примеров из разных классов (известных как базовые классы). Затем модель точно настроена на несколько примеров из новых классов (известных как новые классы) [96].
Существуют различные методы, используемые в обнаружении нескольких выстрелов, включая методы метрического обучения, методы мета-обучения и методы увеличения данных [97–99]. Методы метрического обучения направлены на изучение дистанционной функции, которая может измерить сходство между объектами. Методы мета-обучения направлены на изучение модели, которая может быстро адаптироваться к новым задачам с несколькими примерами обучения с помощью других доменных информации [100]. Методы увеличения данных направлены на создание большего количества обучающих примеров путем применения преобразований к существующим примерам [101]. Кроме того, более полный анализ FSOD на основе воздушного изображения доступен в суммированной таблице 6.
Объяснение в обнаружении нескольких выстрелов относится к способности понимать и интерпретировать решения, принятые моделью. Это важно для проверки правильности прогнозов модели и для получения информации о поведении модели. Объяснение может быть достигнуто путем визуализации карт внимания модели, которые показывают, на каких частях изображения модель фокусируется при прогнозировании. Другие методы включают карты значимости [102], которые подчеркивают наиболее важные пиксели для прогнозирования и деревья решений, которые обеспечивают простое и интерпретируемое представление процесса принятия решений модели [103]. Следовательно, методы обнаружения объектов с несколькими выстрелами показали многообещающие результаты в обнаружении новых объектов на аэрозольных изображениях с ограниченными аннотированными образцами. Особенность внимания модуля подсветка и двухфазная схема обучения способствуют эффективности и адаптивности модели в нескольких сценариях. Тем не менее, все еще существуют проблемы, которые необходимо решить, такие как расхождение в производительности между воздушными и естественными изображениями, а также путаница между некоторыми классами. Будущие исследования должны сосредоточиться на разработке более универсальных методов обнаружения объектов, которые могут эффективно обрабатывать небольшие, средние и крупные объекты, и предоставлять более интерпретируемые и объяснимые результаты.
7.2 FSOD BEDECMARK DATATS для изображений воздушного дистанционного зондирования
• NWPUВиртунникСодержит 10 категорий, с тремя выбранными в качестве новых классов. Исследователи обычно используют раздел, который включает в себя базовую подготовку на изображениях без новых объектов и тонкой настройки на сете с k-аннотированными коробками (где K составляет 1, 2, 3, 5 или 10) для каждого нового класса. Тестовый набор имеет около 300 изображений, каждое из которых содержит хотя бы один новый объект.
• ДиореПолем Набор данных имеет 20 классов и более 23 000 изображений. Пять категорий обозначены как новые, и применяются различные подходы к обучению. Точная настройка выполняется с помощью k-аннотированных коробок (где k может быть 3, 5, 10, 20 или 30) для каждого нового класса, а производительность оценивается в комплексном наборе проверки.
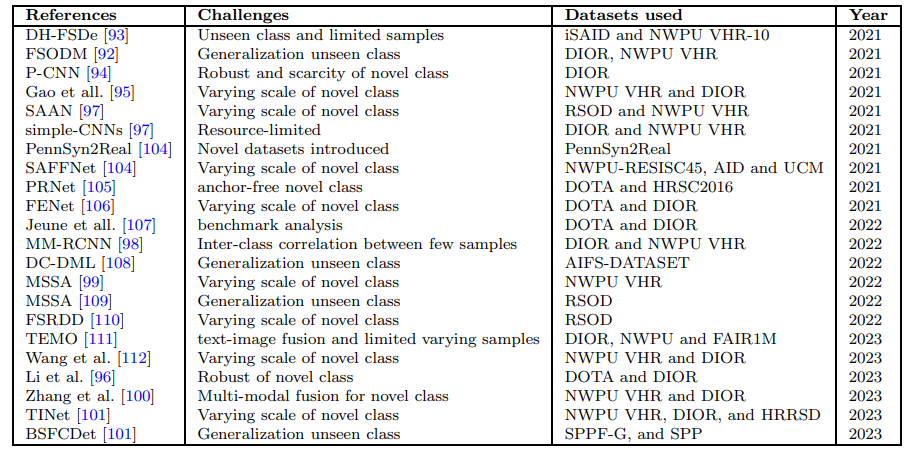
• RsodПолем Набор данных состоит из четырех классов. Один класс случайным образом выбран в качестве нового класса, оставшиеся три в качестве базовых классов. Во время базового обучения 60% образцов для каждого базового класса используются для обучения, а остальные для тестирования. Точная настройка выполняется на k-аннотированных коробках в новых классах, где K может быть 1, 2, 3, 5 или 10.
• isAidНабор данных включает в себя 15 классов и использует три различных базовых/новых расщепления, разработанных в соответствии с характеристиками данных. Каждое разделение фокусируется на различном аспекте, например, размер объекта или дисперсии в внешности. Третье разделение специально выбирает шесть наименее частых классов как новые. Базовая обучение использует все объекты из базовых классов, а тонкая настройка использует 10, 50 или 100 аннотированных коробок на класс.
• ДотаНабор данных имеет увеличение с 15 до 18 категорий и почти в десятикратное расширение до 1,79 миллиона случаев. Он имеет два базовых/новых классовых распада, с тремя классами, обозначенными как новые. Во время строительства эпизода количество снимков для новых классов варьируется как 1, 3, 5 и 10.
• ДанНабор данных представляет собой объединение наборов данных DOTA и NWPU VHR, включающих 15 категорий. Он обозначает три класса как новые, оставшиеся в качестве базовых классов.
7.3 сегментация изображения в дистанционном зондировании
Несколько выстрела сегментации изображений (FSIS)-это сложная задача в компьютерном зрении, особенно в контексте воздушных изображений. Эта задача направлена на то, чтобы сегментировать объекты на изображениях только с несколькими меченными примерами, что особенно важно из -за высокой стоимости сбора меченных данных в области воздушных изображений. Последние достижения в сегментации изображений с несколькими выстрелами были обусловлены методами глубокого обучения, которые показали многообещающие результаты в различных задачах компьютерного зрения. Метрические модели мета-обучения, такие как сиамские сети и прототипные сети, широко использовались в сегментации нескольких выстрелов [113, 114]. Эти модели учатся сравнивать сходство между поддержкой и изображениями запроса и используют эту информацию для сегмента новых классов [115].
Другим распространенным подходом в сегментации изображений в нескольких выстрелах является использование сети глубокого обучения, в частности, сверточные нейронные сети (CNNS) [116]. Эти сети показали большой успех в задачах сегментации изображений и были адаптированы для нескольких сценариев обучения. Исследователи изучили различные архитектуры и стратегии обучения для повышения эффективности CNN в сегментации изображений в нескольких выстрелах [116]. Мета-обучение, которое включает в себя обучение модели, чтобы узнать, как учиться, также применяется к сегментации нескольких выстрелов с многообещающими результатами [116]. Алгоритмы мета-обучения направлены на то, чтобы извлечь мета-знание из набора задач и использования этих знаний, чтобы быстро адаптироваться к новым задачам только с несколькими маркированными примерами. С точки зрения приложений, сегментация с небольшим выстрелом на воздушных изображениях имеет различные потенциальные приложения. Одно из приложений заключается в городском планировании, где можно использовать сегментацию изображений с небольшим выстрелом для идентификации и сегмента различных типов зданий, дорог и другой городской инфраструктуры [117–119]. Другое применение-определение землепользования и определения землепользования, где для классификации различных типов земельного покрова можно использовать небольшую сегментацию изображений, такие как леса, сельскохозяйственные земли и водолеты. Немного выстрела сегментации изображений также можно использовать в мониторинге окружающей среды и моделировании климата для анализа изменений в растительном покровах, водных ресурсах и других факторах окружающей среды. В области распознавания, обнаружения и сегментации лесных пожаров модели глубокого обучения показали большой потенциал [120]. Эти модели были успешно применены к воздушным и наземным изображениям, чтобы точно классифицировать лесные пожары, обнаружить их присутствие и сегментировать огненные области. Были исследованы различные архитектуры глубокого обучения, в том числе CNNS, одноэтапные детекторы (такие как YOLO), двойные детекторы (такие как более быстрые R-CNN) и модели Encoder-Decoder (такие как U-Net и Deeplab). В контексте изображений БПЛА была предложена структура для удаления пространственно -временных объектов из изображений БПЛА, прежде чем генерировать ортомозаику. Структура состоит из двух основных процессов: сегментация изображений и инпонирование изображения. Сегментация изображения выполняется с использованием алгоритма маски R-CNN, который обнаруживает и сегментирует транспортные средства на изображениях БПЛА. Затем сегментированные области маскируются для удаления. Изображение проводятся с использованием метода большой маски (LAMA), метода глубокого обучения, которая реконструирует поврежденные или отсутствующие части изображения [121]. Кроме того, в таблице 7 можно найти более обширное исследование FSI на основе воздушных изображений.
Возбудимость в сегментации изображений, особенно в контексте воздушных изображений дистанционного зондирования, сосредоточилась на разработке новых моделей и методов, которые повышают выполнение задач сегментации и дают представление о процессе принятия решений моделями. Одним из таких достижений является предложенная самого загрязненная сеть смешанных вниманий (SEMANET) [122]. Semanet использует трехмодальные (видимые глубины) изображения для нескольких выстрелов в семантических задачах сегментации. Модель состоит из основы

сеть, самопроборник модуля (SE) и смешанный модуль внимания (MA). Модуль SE усиливает особенности каждой модальности, усиливая различия между основными и фоновыми особенностями и укрепляя слабые соединения. Модуль MA объединяет трехмодальные функции, чтобы получить лучшее представление функций. Другим прогрессом является сочетание самоотверженного ученика-фонового ученика и контрастного представления, чтобы повысить производительность моделей сегментации нескольких выстрелов [115]. Самоуправляемый фоновый учащийся учится латентному фоновым функциям, добывая особенности нецелевых классов в фоновом режиме. Компонент обучения контрастного представления модели направлен на изучение общих функций между категориями с использованием контрастного обучения. Этот подход показал потенциал для повышения производительности и способности обобщения моделей сегментации нескольких выстрелов. Тем не менее, в полевых условиях все еще есть некоторые проблемы, например, как справиться с различиями в производительности, вызванных внутриклассовым путем, и как сделать модели, которые просты для понимания и могут быть довольно точными. Будущие исследования должны сосредоточиться на разработке гибких подходов к сегментации объектов, которые способны эффективно обрабатывать легкие модели. Эти модели должны обладать более высоким уровнем интерпретации для каждого из его компонентов и демонстрировать способность обобщать в других областях.
7.3.1 Наборы данных о эталонных данных с несколькими выстрелами для воздушных изображений удаленного зондирования
• isAidявляется крупномасштабным набором данных, например, сегментацией на воздушных изображениях. Он содержит 2806 изображений с высоким разрешением с аннотациями для 655 451 экземпляра по 15 категориям.
• ВайшинСостоит из истинных ортофото (вверху) изображений, снятых над городом Вайхинсен и дерной, Германия. Изображения имеют пространственное разрешение 9 см, что довольно высокое по сравнению со многими другими наборами данных воздушного изображения. Набор данных также включает в себя соответствующие данные о наземных истинах, которые предоставляют пиксельные аннотации для шести классов: непроницаемые поверхности (такие как дороги и здания), здания, низкая растительность (такие как трава), деревья, автомобили и беспорядок/фон.
• DlrsdСодержит изображения, где данные метки каждого изображения представляют собой изображение сегментации. Эта карта сегментации анализируется для извлечения мульти-маркировки изображения. DLRSD имеет более богатую информацию об аннотации с 17 категориями и соответствующими идентификаторами этикетки.
Авторы:
(1) Гао Ю Ли, Школа электротехники и электронных инженеров, Нанянг Технологический университет, 50 Нанянг -авеню, 639798, Сингапур (Gaoyu001@e.ntu.edu.sg);
(2) Плотина Танмой, Школа машиностроения и аэрокосмической инженерии, Технологический университет Наняна, 65 Нанянг Драйв, 637460, Сингапур и Департамент компьютерных наук, Университет Нью -Орлеана, Новый Орлеан, 2000 Лейкшор Драйв, LA 70148, США (США (США.tanmoy.dam@ntu.edu.sg);
(3) MD Meftahul Ferdaus, Школа электротехники и электронного инженера, Нанянг Технологический университет, 50 Nanyang Ave, 639798, Сингапур (mferdaus@uno.edu);
(4) Даниэль Пуйу Понар, Школа электротехники и электронных инженеров, Технологический университет Наняна, пр. Наняна, 639798, Сингапур (Epdpuiu@ntu.edu.sg);
(5) Vu N. Duong, Школа машиностроения и аэрокосмической инженерии, Nanyang Technological University, 65 Nanyang Drive, 637460, Сингапур (vu.duong@ntu.edu.sg)
Эта статья есть
Оригинал