

Обслуживание LLMS с помощью ваттций: рабочий процесс и интеграция API
12 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
2.1 Модели больших языков
2.2 Фрагментация и Pagegataturation
3 проблемы с моделью Pagegatatturetion и 3.1 требуют переписывания ядра внимания
3.2 Добавляет избыточность в рамки порции и 3,3 накладных расходов
4 понимания систем обслуживания LLM
5 Vattument: проектирование системы и 5.1 Обзор дизайна
5.2 Использование поддержки CUDA низкого уровня
5.3 Служение LLMS с ваттенцией
6 -й ваттиция: оптимизация и 6,1 смягчения внутренней фрагментации
6.2 Скрытие задержки распределения памяти
7 Оценка
7.1 Портативность и производительность для предпочтений
7.2 Портативность и производительность для декодов
7.3 Эффективность распределения физической памяти
7.4 Анализ фрагментации памяти
8 Связанная работа
9 Заключение и ссылки
5.3 Служение LLMS с ваттенцией
Мы строим ваттенцию как библиотеку Python, которая внутренне использует расширение CUDA/C ++ для взаимодействия с драйверами CUDA. Наша библиотека разоблачает набор простых API, перечисленных в таблице 4, в рамках обслуживания.
5.3.1 Первоначальная настройка:Когда запускается структура порции, каждый работник модели загружает библиотеку Vattument и настраивает ее с параметрами модели 𝑁 ′, 𝐻, 𝐷, 𝑃, 𝐵 и предпочтительного размера страницы через API init. Внутренне, Vattument оставляет 2 × 𝑁 ′ Virtual Tensors (с использованием нашего модифицированного распределения кэширования Pytorch) для KV-кэша у каждого работника. Эти виртуальные тензоры зарезервированы для срока службы подачи заявления. Кроме того, ваттенция также предварительно выделяет страницы физической памяти во время инициализации. Тем не менее, эти страницы еще не отображаются в KV-кэш.
5.3.2 Планирование нового запроса:Когда новый запрос запланирован в первый раз, структура обслуживания получает новый Reqid от vattution через Alloc_Reqid. Все последующие операции по управлению памятью запроса помечены этим ReqID.
5.3.3 Выполнение модели:Прежде чем планировать партию для выполнения, фреймворк должен гарантировать, что подтяжки KV-Cache каждого активного запроса поддерживаются физической памятью. Для этой цели, прежде чем отправлять первое ядро итерации в GPU, структура вызывает API шага, указывая текущую длину контекста каждого запроса (длина контекста устанавливается на 0 для каждого неактивного ReqID). Внутренне, ваттенция гарантирует, что достаточное количество физических страниц отображается для каждого активного возврата, прежде чем вернуть выполнение обратно в структуру. Если поватификация не может удовлетворить спрос на память, она возвращается с отказом в ответ на то, что структура обслуживания может предотвратить один или несколько запросов, чтобы разрешить прогресс вперед (это похоже на поведение по умолчанию VLLM). Мы оставляем более сложные политики, такие как замена KV-Cache на память CPU в качестве будущей работы.
В зависимости от того, находится ли запрос в фазе предварительной заполнения или фазы декодирования, может потребоваться отображение различного количества страниц физической памяти для данной итерации. Фаза предварительной заполнения обрабатывает входные токены заданного приглашения параллельно и заполняет один слот в K-Cache (и V-Cache) запроса на каждом уровне модели. Следовательно, количество страниц, необходимого нанести на карту, зависит от количества

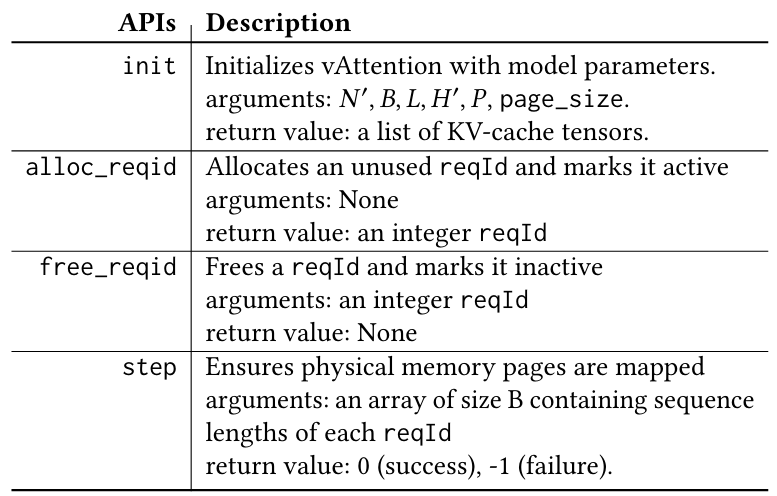
Запланированы быстрые токены. Если общий размер k-cache всех приглашенных токенов на одном слое модели составляет 𝑠, а размер страницы равен 𝑡, то каждый работник необходимо обеспечить, чтобы, по крайней мере, (𝑠 +𝑡-1)/𝑡 Страницы физической памяти отображаются в каждом из подтяжек 2 ° к-кэше данных данного ReqID.
Для запроса на этапе декодирования количество требуемых новых страниц составляет не более одного на запрос. Это потому, что каждая итерация производит только один выходной токен для запроса. Внутренняя часть отслеживает количество страниц, отображаемых для каждого запроса, и отображает новую страницу только тогда, когда последняя страница, выделенная на этот запрос, полностью используется.
5.3.4 Запрос завершить.Запрос заканчивается, когда пользователь указал длину контекста или максимальную длину контекста, поддерживаемая моделью, или когда модель создает специальный токен в конце последовательности. Структура уведомляет об исчезновении заполнения запроса с помощью free_reqid. Внутренне, ваттенция может разветвлять страницы заполненного запроса или отложить их, чтобы они были освобождены позже.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Рамья Прабху, Microsoft Research India;
(2) Аджай Наяк, Индийский институт науки и участвовал в этой работе в качестве стажера в Microsoft Research India;
(3) Джаяшри Мохан, Microsoft Research India;
(4) Рамачандран Рамджи, Microsoft Research India;
(5) Ашиш Панвар, Microsoft Research India.
Оригинал
Recent Post
-
Bitpanda запускает Defi Wallet для Power Europe в будущее Onchain
20 августа 2025 г. -
Как Toyota Blockchain Lab хочет сделать автомобили готовыми к финансированию: Внутри предложения Toyota's Mon предложение
20 августа 2025 г. -
Получение звонков клиентов по бюджету в размере 0 долларов США: уроки от стартапа репетиторства
20 августа 2025 г. -
За кулисами эксперимента парного программирования
19 августа 2025 г. -
Простое руководство по измерению времени и труда в программировании
19 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Астрофизика
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика
- Развлечения
- ИТ и автоматизация
- Криптовалюты и блокчейн
- История и идеология
- Медицина и политика
- Личная жизнь миллиардеров
- Образование и Политика
- Туризм и отдых
- Психология и искусственный интеллект
- Удаленная работа и производительность
- Выживание
- Управление командами
- Разработка
- Международная торговля
- Корпоративная ответственность
- Социальные сети и общество
- Управление серверами
- Индустрия компьютерных игр
- Политика и климат
- Онлайн-игры
- Медицинская отрасль
- Искусственный интеллект и технологии
- Религия и мораль
- Путешествия
- Социальные сети и информация
- Технологии и медиа
- Технологии и свобода
- Электронная коммерция
- Бизнес и управление
- Психическое здоровье и технологии
- Технологии и устойчивое развитие
- Технологии и социальные сети
- Профессии
- Экономика и промышленность
- Технологии и трудоустройство
- Иммиграционная политика
- Продуктивность и фокус
- Технологии и робототехника
- Свобода слова
- Психология и власть
- Социальные сети и онлайн-платформы
- Технологии и Права Человека
- СМИ и журналистика
- Окружающая среда и здоровье
- Технологии и сервисы
- Индустрия игр
- Программирование и ИИ
- Медиа и пропаганда
- Социальная сфера
- Социальные сети и общественное мнение
- Поп-культура
- Сервисы потокового вещания
- Рынок развлечений
- Социальные медиа и политика
- Технологии и информация
- Медиа и развлечения
- Квантовая криптография
- Искусственный интеллект в индустрии развлечений
- Технологии и коммуникация
- Индустрия программирования
- Финансовая безопасность
- Международные отношения
- Бизнес и лидерство
- Технологические новости и аналитика
- Программное обеспечение и технологии
- Предпринимательство и малый бизнес
- Политика и общественный контроль
- Здравоохранение и политика
- Управление персоналом и эффективность разработки
- Технологии и ИТ‑управление
- Свобода слова и дезинформация
- Веб-дизайн и разработка
- Веб‑разработка и карьера
- Культура и общество
- Цифровые права и свобода слова
- Безопасность и искусственный интеллект
- Технологии и искусство
- Мобильные приложения
- Продуктивность
- Космические технологии и безопасность
- Технологические тренды и экономика
- Безопасность и конфиденциальность
- Продуктивность и личная эффективность
- Веб‑скрейпинг и автоматизация