

Анализ чувствительности параметров эксперимента в исследованиях мутаций ошибок
4 июня 2025 г.Авторы:
(1) Бо Ван, Университет Пекин Цзиотонг, Пекин, Китай (wangbo_cs@bjtu.edu.cn);
(2) Mingda Chen, Пекинский университет Цзиотонга, Пекин, Китай (23120337@bjtu.edu.cn);
(3) Youfang Lin, Пекинский университет Цзиотонг, Пекин, Китай (yflin@bjtu.edu.cn);
(4) Майк Пападакис, Университет Люксембурга, Люксембург (michail.papadakis@uni.lu);
(5) Цзе М. Чжан, Королевский колледж Лондон, Лондон, Великобритания (jie.zhang@kcl.ac.uk).
Таблица ссылок
Аннотация и1 Введение
2 предыстория и связанная с ним работа
3 Учебный дизайн
3.1 Обзор и исследования исследований
3.2 Наборы данных
3.3 генерация мутаций через LLMS
3.4 Метрики оценки
3.5 Настройки эксперимента
4 Результаты оценки
4.1 RQ1: производительность по стоимости и юзабилити
4.2 RQ2: сходство поведения
4.3 RQ3: воздействие различных подсказок
4.4 RQ4: воздействие различных LLMS
4.5 RQ5: основные причины и типы ошибок некомпилируемых мутаций
5 Обсуждение
5.1 Чувствительность к выбранным настройкам эксперимента
5.2 Последствия
5.3 Угрозы достоверности
6 Заключение и ссылки
5 Обсуждение
5.1 Чувствительность к выбранным настройкам эксперимента
5.1.1 Настройка эксперимента длины контекста.Чтобы сравнить сходство с реальными дефектами, мы намеренно выбираем контекст вокруг местоположений ошибок для создания мутаций для всех подходов. Чтобы проверить влияние выбора контекста на производительность, мы проводим эксперименты на 60 ошибках от Defects4j, сравнивая, как различные длины контекста влияют на производительность. В наших предыдущих экспериментах длина контекста устанавливается на три строки вокруг местоположения ошибки, поэтому мы проводим эксперименты, чтобы сравнить эффекты двухстрочных и однострочных контекстов, как показано в таблице 9. Чтобы измерить их сходство в производительности, мы используем коэффициент Спирмена и корреляцию Пирсона, как показано в таблице 10. Мы видим, что их взаимная сходство превышает 0.95, что выше типичности. 69], а 𝑝-значения все ниже 0,05. Различные длины контекста работают одинаково, подтверждая тем самым настройку нашего эксперимента.
5.1.2 Влияние разных примеров.Чтобы измерить влияние различных примеров нескольких выстрелов на результаты, мы проводим сравнительные эксперименты с различными примерами. Во -первых, мы случайным образом выбираем 3, 6 и 9 дополнительных примеров из Quixbugs, и убедитесь, что с примерами по умолчанию 6 и примеров. Кроме того, несмотря на риск утечки данных, мы выбираем 6 примеров из набора данных Defects4j. Результаты представлены в таблице 11.
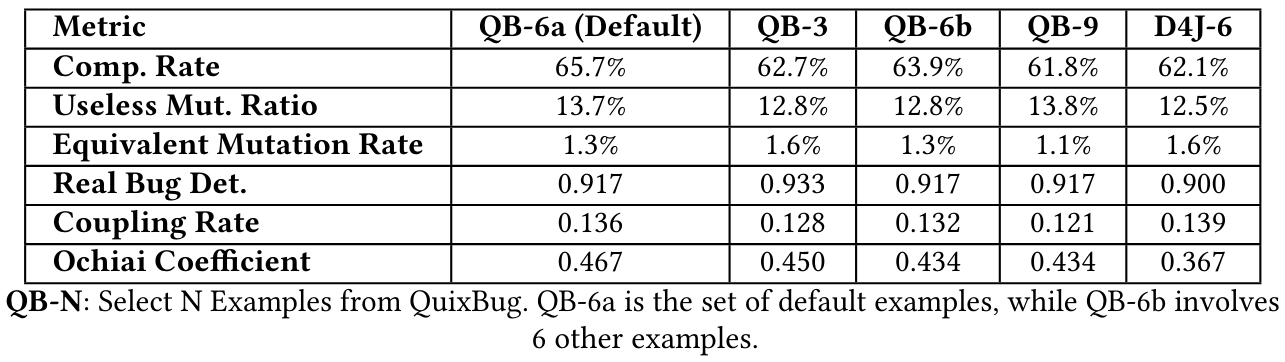

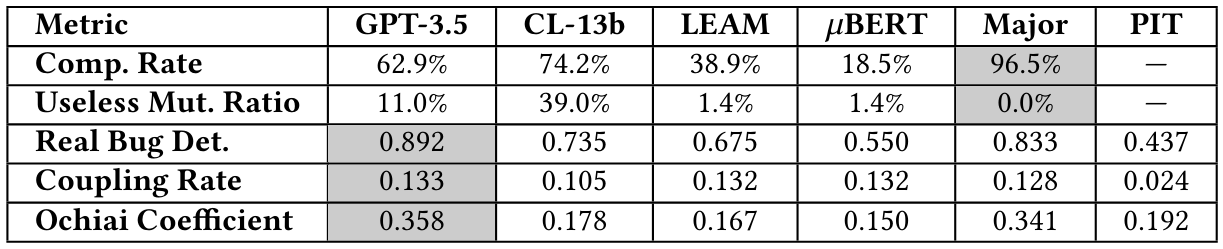
Мы также рассчитываем их сходство, показанную как таблица 12. Мы можем обнаружить, что их сходство превышает 0,95, что значительно превышает типичный порог 0,85, а 𝑝-значения-все ниже 0,05. Поэтому мы можем сделать вывод, что производительность различных подсказок очень похожа.
5.1.3 Эффективность использования того же количества мутаций.В разделе 4 мы не ограничивали количество мутаций, генерируемых каждым подходом. Чтобы изучить производительность каждого подхода в условиях фиксированного количества, мы следовали на условиях существующего исследования [28, 70] и ограничивали количество мутаций, генерируемых всеми методами, минимальным, произведенным 𝜇bert [15], который составляет 16 785. Для подсчета, превышающих это число, мы случайным образом выбрали указанное количество мутаций для анализа. Мы провели 10 раундов случайных сравнений выборки, и результаты представлены в таблице 13. Следовательно, в условиях фиксированного количества мутации, генерируемые GPT-3.5-Turbo, все еще являются самыми близкими к реальным ошибкам в поведении.
Эта статья есть
Оригинал