

Примерно половина специалистов по данным считают мониторинг моделей серьезной неприятностью: так ли это должно быть?
9 ноября 2022 г.Как правило, жизненный цикл машинного обучения (ML) включает шесть ключевых этапов: сбор данных, обработка данных, маркировка данных, обучение/оценка модели, развертывание модели и мониторинг модели.
Недавний крупномасштабный проект одного из крупных сообществ специалистов по данным создали новый ландшафт цепочки создания стоимости машинного обучения, который подробно исследовал весь жизненный цикл машинного обучения. Исследование, проведенное многочисленными специалистами по данным и инженерами по машинному обучению, среди прочего показало, что последний этап цепочки (то есть мониторинг модели) был одним из наименее любимых и наиболее страшных этапов всего жизненного цикла.
Лицом к музыке
Мало кто из практикующих остановится, чтобы задаться вопросом, почему это так. Очевидный ответ связан с аддитивным эффектом, то есть каждый этап цепочки может содержать проблемы, и к тому времени, когда вы дойдете до самого конца, все они, как правило, сойдутся вместе, чтобы пролить дождь на ваш парад. На самом деле, как объяснили некоторые респонденты исследования, эта неприятная закономерность проявляется уже во время разработки, потому что, оказывается, «большинство решений просто вообще не оптимизированы для мониторинга моделей, прошедших начальный этап».
В результате многие инженеры машинного обучения, работающие над продуктами ИИ, часто вынуждены «сталкиваться с музыкой» на последних этапах жизненного цикла, что иногда может больше походить на закодированную какофонию. В довершение всего существует проблема записей проектов. Мониторинг моделей, как выразился один из моих коллег, включает в себя «много просеивания журналов, чтобы быстро найти интеллектуальную информацию», что может быть чрезвычайно сложно, поскольку у разных специалистов, как правило, разные рабочие предпочтения и привычки.
Текущие данные
Но даже эти проблемы можно преодолеть, если вы будете усердны, дисциплинированы и постоянно будете в курсе дела. Однако, несмотря на это, самая большая проблема для инженеров машинного обучения по-прежнему актуальна — мониторинг моделей не является статичным. Скажем, ваши журналы чисты, ваши данные должным образом помечены, и ваша модель предположительно соответствует задаче. Как бы то ни было, это не значит, что вы можете передохнуть. Наоборот, во многих смыслах это начало самой важной части процесса — этапа монетизации продукта в реальном времени, и, вероятно, именно поэтому вы начали этот трудный путь в первую очередь. Большой вопрос заключается в том, как узнать, хорошо ли работает ваша модель, когда начинают поступать новые пользовательские данные?
Ярким примером того, как новые пользовательские данные могут повлиять на вашу развернутую модель, является обзоры ароматических свечей во время COVID-19. Давайте представим, что вы производите или продаете ароматические свечи и получаете отзывы пользователей, которые указывают на то, что ваши свечи практически не имеют запаха. Сегодня мы знаем, что это явление наблюдалось из-за того, что люди, зараженные коронавирусом, временно теряли обоняние, т. е. дело вовсе не в продукте.
Другими словами, здесь мы наблюдаем явный случай дрейфа данных (или распределения) из-за внешних факторов: одни и те же обзоры в разных условиях могут привести к совершенно разным выводам. Но если мы неосознанно используем эти ошибочные выводы для переобучения нашей модели, что также может включать в себя дрейф меток (изменения в деталях задачи) или перекосы обучения (нерепрезентативные данные), это может привести и приведет к потенциально нежелательным результатам.
Оперативный мониторинг
Имея все это в виду, перспектива мониторинга моделей может заставить нас, инженеров машинного обучения, чувствовать себя неловко. В конце концов, мы должны не только устранять возможные ранее проблемы, но и обрабатывать тонны новых данных с каждым препятствием, которое это создает. Один из способов, которым я смог сделать этот процесс менее утомительным и безумным, — это так называемый подход "человек в цикле".
Обычно процесс вывода машинного обучения может выглядеть примерно так:
n
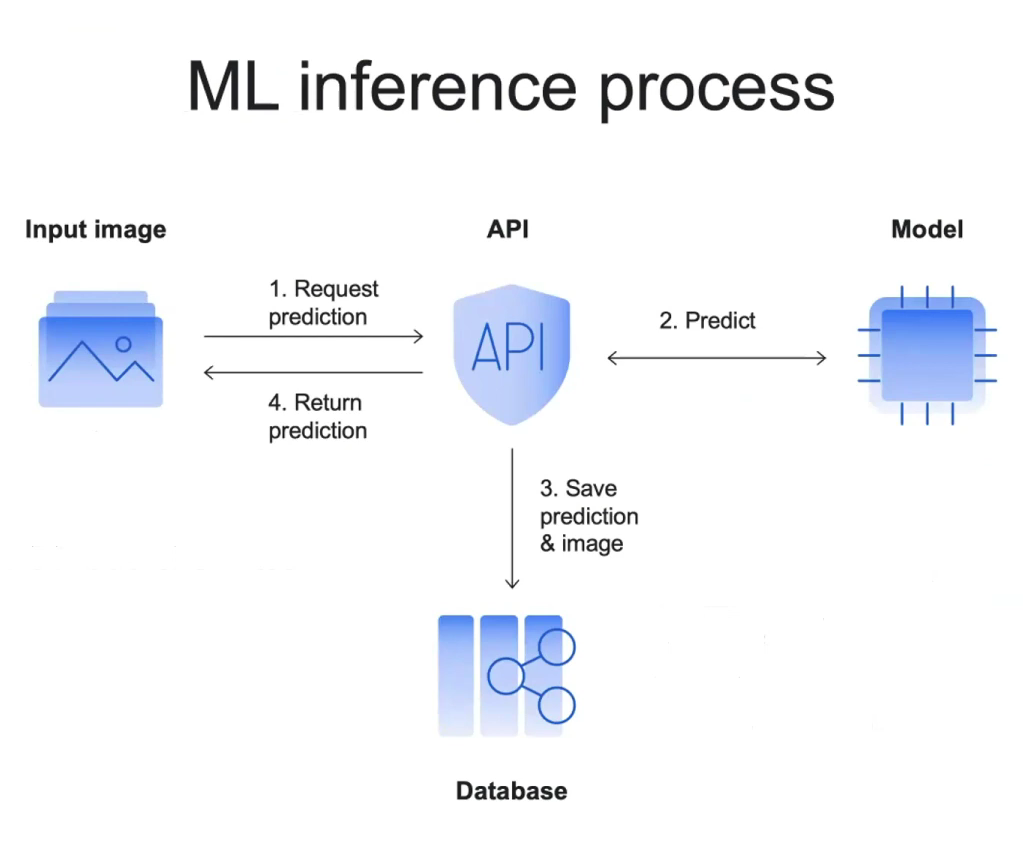
В этом сценарии мы можем использовать сохраненные прогнозы в базе данных. Проблема в том, что нет возможности проверить их достоверность в текущем пайплайне. Но что мы можем сделать, чтобы определить, на каком уровне находится наша модель, так это получить достоверные ответы, используя аннотаторов-людей, и сравнить их с ответами машины. Тогда наш процесс мониторинга будет выглядеть примерно так:
n
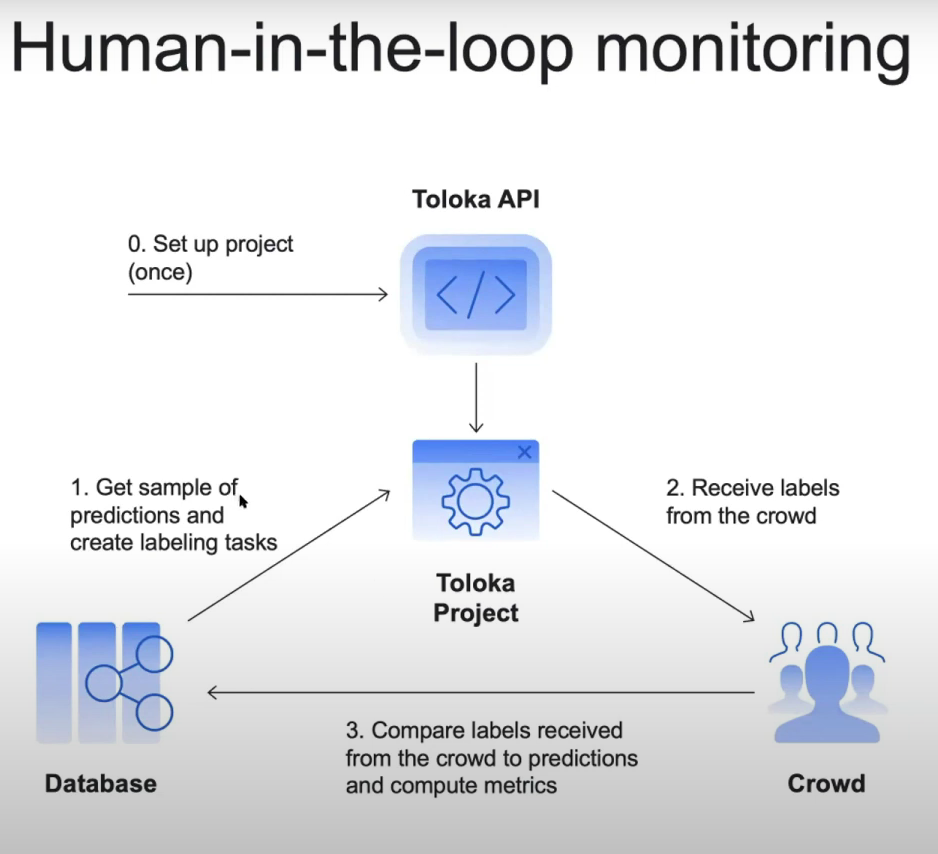
В этом расширенном сценарии данные передаются реальным людям, которые в случае краудсорсинговых платформ являются конкретными участниками краудсорсинга, выбранными для выполнения задач.
После этого есть два способа сделать это. Первый представляет собой двухэтапный процесс, который включает в себя (а) получение от аннотаторов ответов на те же вопросы, с которыми столкнулась модель (т. е. создание «золотых наборов»), а затем (б) сравнение этих новых наборов с предсказаниями модели. Другой способ — это одноэтапный процесс, который включает в себя получение аннотаторов для просмотра входных данных модели и оценки прогнозов модели из базы данных на их основе (одновременно). Оба подхода предоставят информацию о производительности вашей модели, и хотя второй подход проще и эффективнее, его можно использовать только для оценки, но не для точной настройки модели (в отличие от первого варианта).
В обоих случаях собранные вами оценочные данные могут быть отображены на информационной панели, где обычно проявляются определенные закономерности и ошибки, которые легко обнаруживаются. К счастью, некоторые платформы позволяют использовать их API вместе с Python, что хорошо подходит для большинства моделей машинного обучения — нет проблем с несовместимостью или дополнительной работы.
Тест-драйв и предостережения
Практика ведет к совершенству, поэтому вот пробный пример, чтобы увидеть, как весь процесс работает в реальной жизни. Он содержит практическую демонстрацию с API для прогнозирования моделей и готовый код для настройки и запуска небольшого проекта мониторинга.
В этом намеренно упрощенном, теперь «классическом» примере, задача состоит в том, чтобы идентифицировать изображения кошек и собак на основе гипотетической модели ML с вариантами: (1) кошка, (2) собака и (3) ни ( это сигнал о том, что что-то не так либо с вашей моделью, либо с входящими данными).
Как вы сможете увидеть из примера, мониторинг с участием человека в цикле действительно обеспечивает изящное решение; однако это не волшебная таблетка. Важно учитывать следующие предостережения, чтобы обеспечить наилучшие результаты, если вы решите использовать этот подход:
* Поскольку оценка метрик вашей модели зависит от постоянной оценки пользовательских данных, крайне важно также следить за качеством ваших данных, обработанных человеком, которые вы будете рассматривать как свою основную истину. Например, вы можете назначить небольшое количество проверенных аннотаторов для обеспечения качества остальных и/или использовать другие методы контроля качества.
* Другой полезный подход, обеспечивающий достоверные результаты, заключается в предоставлении одной и той же точки данных не 1, а 3 или 5 комментаторам-человекам. После этого вы можете использовать один из методов, представленных в Crowd-kit, например, выполнить агрегацию.
* Убедитесь, что вы проверяете показатели агрегации, такие как достоверность агрегации, согласованность, неопределенность и/или соглашение между аннотаторами. Для классификации эти показатели уже содержатся в Crowd-kit.
* Не забудьте рассчитать пределы погрешности и добавить планки погрешностей при построении графиков.
* Прежде чем двигаться дальше, всегда проверяйте модель на наличие статистически значимых или незначительных изменений.
Итог
Как мы видели, весь жизненный цикл машинного обучения часто может быть тернистым для инженеров машинного обучения. Мой совет — используйте комбинацию методов для борьбы с текущими проблемами и получения результатов самого высокого качества. Похоже, что на этапе мониторинга модели подход «человек в цикле» может предложить практическое решение, которое также оказывается довольно быстрым и доступным.
Основываясь на результатах моих собственных проектов, мониторинг модели «человек в цикле» может улучшить ваш продукт ИИ, при условии, что никакие проблемы на предыдущих этапах не были скрыты. В то же время, если что-то важное было упущено по пути, этот подход также может помочь выявить эти проблемы, используя людей-аннотаторов в качестве дополнительной точки отсчета. п
Оригинал