

Исследователи выдвигают модели на языке зрения, чтобы схватить метафоры, идиомы и сарказм
19 июня 2025 г.Авторы:
(1) Arkadiy Saakyan, Колумбийский университет (a.saakyan@cs.columbia.edu);
(2) Шреяс Кулкарни, Колумбийский университет;
(3) Тухин Чакрабарти, Колумбийский университет;
(4) Смаранда Мюресан, Колумбийский университет.
Примечание редактора: это часть 6 из 6 исследований, рассматривая, насколько хорошо крупные модели искусственного интеллекта обрабатывают фигуративный язык. Прочитайте остальное ниже.
Таблица ссылок
- Аннотация и 1. Введение
- 2. Связанная работа
- 3. v-Flute Задача и набор данных
- 3.1 Метафоры и сравнения
- 3.2 идиомы и 3,3 сарказма
- 3.4 Юмор и 3,5 Статистика набора данных
- 4. Эксперименты и 4.1 модели
- 4.2 Автоматические метрики и 4.3 результаты автоматической оценки
- 4.4 Человеческий базовый уровень
- 5. Оценка человека и анализ ошибок
- 5.1 Как модели работают в соответствии с людьми?
- 5.2 Какие ошибки допускают модели? и 5.3 Насколько хорошо оценка объяснения предсказывает человеческое суждение о адекватности?
- 6. Выводы и ссылки
- Статистика набора данных
- B API модели гиперпараметры
- C тонкая настройка гиперпараметров
- D подсказки для LLMS
- E Модель таксономия
- F By-Phenomenon Performance
- G Аннотаторский набор и компенсация
6 выводов
Мы вводим высококачественный набор данных для понимания фигуративных явлений при мультимодальном входе, V-Flute, обрамленном как объяснимое визуальное введение. Наш набор данных состоит из 6027 экземпляров, охватывающих различные фигуративные явления, такие как метафора, идиома, рисунок, сарказм и юмор. Мы используем этот набор данных, чтобы сравнить производительность современных моделей на языке зрения, используя как автоматическую, так и человеческую оценку, и для определения критических областей улучшения для VLM для этой задачи.
Ссылки
Шурья Аггарвал, Дивьяншу Мандовара, Вишваджит Агравал, Динеш Ханддельвал, Параг Сингла и Динеш Гарг. 2021. Объяснения для CommonsenseQA: новый набор данных и модели. В материалах 59 -го ежегодного собрания Ассоциации вычислительной лингвистики и 11 -й Международной совместной конференции по обработке естественного языка (том 1: длинные документы), страницы 3050–3065, онлайн. Ассоциация вычислительной лингвистики.
Арджун Р. Акула, Брендан Дрисколл, Прадьюмна Нараяна, Соравит Чанпиньо, Чживей Цзя, Суяш Дэмл, Гарима Прути, Сугато Басу, Леонидас Гибас, Уильям Т Фриман и др. 2023. Метаклу: к всесторонним исследованиям визуальных метафоров. В материалах конференции IEEE/CVF по компьютерному зрению и распознаванию шаблонов, страницы 23201–23211.
Жан-Баптист Алайрак, Джефф Донахью, Полин Люк, Антуан Мич, Иэн Барр, Яна Хассон, Карел Ленк, Артур Менш, Кэтрин Милликан, Малкольм Рейнольдс и др. 2022. Flamingo: модель визуального языка для нескольких выстрелов. Достижения в системах обработки нейронной информации, 35: 23716–23736.
Антроп. 2024. Клод 3 Модельная семья: Opus, Sonnet, Haiku. https: //www.anthropic.com/news/ claude-3-calemily.
Сэмюэль Р. Боуман, Габор Анжели, Кристофер Поттс и Кристофер Д. Мэннинг. 2015. Большой аннотированный корпус для изучения вывода естественного языка. В материалах конференции 2015 года по эмпирическим методам в обработке естественного языка, страницы 632–642, Лиссабон, Португалия. Ассоциация вычислительной лингвистики.
Оана-Мария Камбуру, Тим Рокташель, Томас Лукасевич и Фил Блунсом. 2018. e-snli: вывод естественного языка с естественным языком. В достижениях в системах обработки нейронной информации, том 31. Curran Associates, Inc.
Скай Ч-Ванг, Аркадий Саакьян, Оливер Ли, Чжоу Ю и Смаранда Мюресан. 2023. Социокультурные нормальные сходства и различия посредством ситуационного выравнивания и объяснимого текста. В материалах конференции 2023 года по эмпирическим методам обработки естественного языка, страницы 3548–3564, Сингапур. Ассоциация вычислительной лингвистики.
Тухин Чакрабарти, Аркадий Саакьян, Дебанджан Гош и Смаранда Мюресан. 2022. Флейта: понимание фигуративного языка посредством текстовых объяснений. В материалах конференции 2022 года по эмпирическим методам обработки естественного языка, страницы 7139–7159, Абу -Даби, Объединенные Арабские Эмираты. Ассоциация вычислительной лингвистики.
Тухин Чакрабарти, Аркадий Саакьян, Оливия Винн, Артемида Панагопулу, Юэ Ян, Марианна Апидианаки и Смаранда Мюресан. 2023. Я шпионю за метафорой: модели больших языков и диффузионные модели совместно создают визуальные метафоры. В результатах Ассоциации вычислительной лингвистики: ACL 2023, стр. 7370–7388, Торонто, Канада. Ассоциация вычислительной лингвистики.
Джейкоб Коэн. 1960. Коэффициент соглашения о номинальных масштабах. Образовательное и психологическое измерение, 20 (1): 37–46.
POWNAV DESAI, TANMOY Chakraborty и MD Shad Akhtar. 2022. Хороший духи. Как долго вы в этом маринули? Мультимодальный сарказм объяснение. Материалы конференции AAAI по искусственному интеллекту, 36 (10): 10563–10571.
Гурам Дей, Адития против Ганесан, Яш Кумар Лал, Манал Шах, Шреяши Синха, Мэтью Матро, Сальваторе Джорги, Вивек Кулкарни и Х. Эндрю Шварц. 2024. Социал-лама: модель для социальных научных задач, настроенная на обучение. Arxiv Preprint arxiv: 2402.01980.
Чарльз Форсвилл. 2002. ПИСЬ МЕТАПОНА В РЕКЛАМЕНТАХ. Routledge.
Сьюзен Р. Фусселл и Малли М. Мосс. 2014. Фигуративный язык в эмоциональном общении. В социальных и когнитивных подходах к межличностному общению, страницы 113–141. Психология пресса.
Мэтт Гарднер, Уильям Меррилл, Джесси Додж, Мэтью Питерс, Алексис Росс, Самир Сингх и Ноа А. Смит. 2021. Проблемы с компетенцией: при поиске и удалении артефактов в языковых данных. В материалах конференции 2021 года по эмпирическим методам обработки естественного языка, страницы 1801–1813, онлайн и Пунта -Кана, Доминиканская Республика. Ассоциация вычислительной лингвистики.
Сучин Гуруранган, Свабха Сэйамдипта, Омер Леви, Рой Шварц, Сэмюэль Боуман и Ноа А. Смит. 2018. Аннотация артефакты в данных о естественном языке. В материалах Конференции Северной Америки в Северной Америке Ассоциации вычислительной лингвистики: технологии человеческого языка, том 2 (короткие документы), стр. 107–112, Новый Орлеан, Луизиана. Ассоциация вычислительной лингвистики.
Пенгчэн он, Сяодон Лю, Цзянфенг Гао и Вейху Чен. 2021. {Deberta}: {decoding}-{Enhanced} {bert} {с} {disEneangled} {внимание}. В Международной конференции по обучению.
Джек Хессель, Ана Марасович, Йена Д. Хван, Лилиан Ли, Джефф Д.А., Роуэн Зеллерс, Роберт Манкофф и Еджин Чой. 2023. Смеются ли андроиды на электрических овец? Юмор «Понимание» тестов из конкурса заголовков Нью -Йорка. В материалах 61 -й ежегодного собрания Ассоциации вычислительной лингвистики (том 1: Лонг), стр. 688–714, Торонто, Канада. Ассоциация вычислительной лингвистики.
Эдвард Дж. Ху, Йелонг Шен, Филипп Уоллис, Зейуан Аллен-зху, Юаньжи Ли, Шин Ван, Лу Ван и Вейху Чен. 2022. LORA: Низкая адаптация крупных языковых моделей. В Международной конференции по обучению.
Eunjeong Hwang и Vered Shwartz. 2023. Memecap: набор данных для подписания и интерпретации мемов. В материалах конференции 2023 года по эмпирическим методам обработки естественного языка, страницы 1433–1445, Сингапур. Ассоциация вычислительной лингвистики.
Альберт К. Цзян, Александр Саблайроллес, Артур Менш, Крис Бэмфорд, Девендра Сингх Чаприз, Диего де Лас Касас, Флориан Брессанд, Джанна Ленгьель, Гийом Лейпл, Люсиль Саулньер, Лелио Ренард Лав, Мари-Энн Лэчаус, Пьерная Стокол, Тен Лей. Ван, Тимофеи Лакруа и Уильям Эль Сайед. 2023. Мисстраль 7b.
Максим Кайзер, Оана-Мария Камбуру, Леонард Салевски, Корнелиус Эмде, Вирджини До, Зейнеп Аката и Томас Лукасевич. 2021. E-VIL: набор данных и эталон для объяснений естественного языка в задачах на языке зрения. В материалах Международной конференции IEEE/CVF по компьютерному видению, страницы 1244–1254.
Филипп Кен. 2004. Статистические тесты значимости для оценки машинного перевода. В материалах конференции 2004 года по эмпирическим методам в обработке естественного языка, страницы 388–395, Барселона, Испания. Ассоциация вычислительной лингвистики.
Видиа Лестари. 2019. Анализ иронии мемов в социальных сетях в Instagram. Пионер: журнал языка и литературы, 10 (2): 114–123.
Джуннан Ли, Донгксу Ли, Кайминг Сионг и Стивен Хой. 2022. Blip: начальная загрузка языкового изображения перед тренировкой для Unified VisionLanguage Понимание и поколение. На Международной конференции по машинному обучению, страницы 12888–12900. PMLR.
Алиса Лю, Swabha Swayamdipta, Noah A. Smith и Yejin Choi. 2022. Wanli: Сотрудничество работников и ИИ для создания набора данных о выводе естественного языка. В результатах Ассоциации вычислительной лингвистики: EMNLP 2022, стр. 6826–6847, Абу -Даби, Объединенные Арабские Эмираты. Ассоциация вычислительной лингвистики.
Хаотиан Лю, Чуньюан Ли, Юхенг Ли и Юн Чже Ли. 2023a. Улучшенные базовые показатели с настройкой визуальной инструкции.
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen и Yong Jae Lee. 2024. Llava-next: улучшенные рассуждения, OCR и мировые знания.
Хаотиан Лю, Чунюань Ли, Циньян Ву и Юн Чже Ли. 2023b. Настройка визуальной инструкции. В достижениях в системах обработки нейронной информации, том 36, страницы 34892–34916. Curran Associates, Inc.
Пан Лу, Сваруп Мишра, Тони Ся, Лян Цю, Кай-Вей Чанг, Сонг-Чун Чжу, Ойвинд Тафьорд, Питер Кларк и Эшвин Калян. 2022. Научитесь объяснять: мультимодальные рассуждения через мыслительные цепочки для ответа на вопрос о науке. В 36 -й конференции по системам обработки нейронной информации (Neurips).
Билл Маккартни и Кристофер Д. Мэннинг. 2008. Моделирование семантической сдерживания и исключения в выводе естественного языка. В материалах 22 -й Международной конференции по вычислительной лингвистике (Coling 2008), стр. 521–528, Манчестер, Великобритания. Coling 2008 Организационный комитет.
Том Маккой, Элли Павлик и Тал Линзен. 2019. Правильно по неправильным причинам: диагностика синтаксической эвристики в выводе естественного языка. В материалах 57 -го ежегодного собрания Ассоциации вычислительной лингвистики, страницы 3428–3448, Флоренция, Италия. Ассоциация вычислительной лингвистики.
Чанчарик Митра, Брэндон Хуанг, Тревор Даррелл и Рой Херциг. 2023. Композиционная цепь, подсказывающая мысль для крупных мультимодальных моделей.
Openai. 2023. Системная карта GPT-4V (ISION). https://cdn.openai.com/papers/ gptv_system_card.pdf.
Анна Пиата. 2016. Когда метафора становится шуткой: метафора путешествий от политической рекламы в интернет -мемы. Журнал прагматики, 106: 39–56.
Адам Полиак, Джейсон Нарадовский, Апараджита Халдар, Рэйчел Рудингер и Бенджамин Ван Дурм. 2018. Гипотеза только базовые показатели в выводе естественного языка. В материалах Седьмой совместной конференции по лексической и вычислительной семантике, страницы 180–191, Новый Орлеан, Луизиана. Ассоциация вычислительной лингвистики.
Эми Пу, Хен Вин Чунг, Анкур П. Парих, Себастьян Германн и Тибо Селлам. 2021. Изучение компактных метрик для Mt. В материалах EMNLP.
Алек Рэдфорд, Чон Вук Ким, Крис Халласи, Адитья Рамеш, Габриэль Го, Сандхини Агарвал, Гириш Штри, Аманда Аскалл, Памела Мишкин, Джек Кларк и др. 2021. На Международной конференции по машинному обучению, страницы 8748–8763. PMLR.
Назнин Фатема Раджани, Брайан Макканн, Кайминг Сионг и Ричард Сохер. 2019. Объясните себя! Использование языковых моделей для здравого смысла. В материалах 57 -го ежегодного собрания Ассоциации вычислительной лингвистики, страницы 4932–4942, Флоренция, Италия. Ассоциация вычислительной лингвистики.
Ричард М. Робертс и Роджер Дж. Кройз. 1994. Почему люди используют фигуративный язык? Психологическая наука, 5 (3): 159–163.
Arkadiy Saakyan, Tuhin Chakrabarty, Debanjan Ghosh и Smaranda Muresan. 2022. Отчет о Figlang 2022 Общей задачи по пониманию образного языка. В материалах 3 -го семинара по обработке фигуративного языка (FLP), страницы 178–183.
Линда М Скотт. 1994. Изображения в рекламе: потребность в теории визуальной риторики. Журнал потребительских исследований, 21 (2): 252–273.
Тибо Селлам, Дипанджан Дас и Анкур Парих. 2020. Bleurt: обучение надежным метрикам для генерации текста. В материалах 58 -го ежегодного собрания Ассоциации вычислительной лингвистики, страницы 7881–7892, онлайн. Ассоциация вычислительной лингвистики.
Ekaterina v Shutova. 2011. Вычислительные подходы к фигуративному языку. Технический отчет, Кембриджский университет, Компьютерная лаборатория.
Settalaluri Lakshmi Sravanthi, Meet Doshi, Tankala Pavan Kalyan, Rudra Murthy, Pushpak Bhattacharyya и Raj Dabre. 2024. Паб: контрольный эталон понимания прагматики для оценки прагматических возможностей LLMS. Arxiv Preprint arxiv: 2401.07078.
Кевин Стоу, Празета Утама и Ирина Гуревич. 2022. IMPAI: Изучение эффективности моделей NLI на фигуративном языке. В материалах 60 -го ежегодного собрания Ассоциации по вычислительной лингвистике (том 1: длинные документы), стр. 5375–5388, Дублин, Ирландия. Ассоциация вычислительной лингвистики.
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, David Silver, Slav Petrov, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lillicrap, Angeliki Lazaridou, Orhan Firat, James Molloy, Michael Isard, Paul R. Barham, Tom Hennigan, Benjamin Lee, Fabio Viola, Malcolm Reynolds, Yuanzhong Xu, Ryan Doherty, Eli Collins, Clemens Meyer, Eliza Rutherford, Erica Moreira, Kareem Ayoub, Megha Goel, George Tucker, Enrique Piqueras, Maxim Krikun, Iain Barr, Nikolay Savinov, Ivo Danihelka, Becca Roelofs, Anaïs White, Anders Andreassen, Tamara von Glehn, Lakshman Yagati, Mehran Kazemi, Lucas Gonzalez, Misha Khalman, Jakub Sygnowski, Alexandre Frechette, Charlotte Smith, Laura Culp, Lev Proleev, Yi Luan, Xi Chen, James Lottes, Nathan Schucher, Federico Lebron, Alban Rrustemi, Natalie Clay, Phil Crone, Tomas Kocisky, Jeffrey Zhao, Bartek Perz, Dian Yu, Heidi Howard, Adam Bloniarz, Jack W. Rae, Han Lu, Laurent Sifre, Marcello Maggioni, Fred Alcober, Dan Garrette, Megan Barnes, Shantanu Thakoor, Jacob Austin, Gabriel Barth-Maron, William Wong, Rishabh Joshi, Rahma Chaabouni, Deeni Fatiha, Arun Ahuja, Ruibo Liu, Yunxuan Li, Sarah Cogan, Jeremy Chen, Chao Jia, Chenjie Gu, Qiao Zhang, Jordan Grimstad, Ale Jakse Hartman, Martin Chadwick, Gaurav Singh Tomar, Xavier Garcia, Evan Senter, Emanuel Taropa, Thanumalayan Sankaranarayana Pillai, Jacob Devlin, Michael Laskin, Diego de Las Casas, Dasha Valter, Connie Tao, Lorenzo Blanco, Adrià Puigdomènech Badia, David Reitter, Mianna Chen, Jenny Brennan, Clara Rivera, Sergey Brin, Shariq Iqbal, Gabriela Surita, Jane Labanowski, Abhi Rao, Stephanie Winkler, Emilio Parisotto, Yiming Gu, Kate Olszewska, Yujing Zhang, Ravi Addanki, Antoine Miech, Annie Louis, Laurent El Shafey, Denis Teplyashin, Geoff Brown, Elliot Catt, Nithya Attaluri, Jan Balaguer, Jackie Xiang, Pidong Wang, Zoe Ashwood, Anton Briukhov, Albert Webson, Sanjay Ganapathy, Smit Sanghavi, Ajay Kannan, MingWei Chang, Axel Stjerngren, Josip Djolonga, Yuting Sun, Ankur Bapna, Matthew Aitchison, Pedram Pejman, Henryk Michalewski, Tianhe Yu, Cindy Wang, Juliette Love, Junwhan Ahn, Dawn Bloxwich, Kehang Han, Peter Humphreys, Thibault Sellam, James Bradbury, Varun Godbole, Sina Samangooei, Bogdan Damoc, Alex Kaskasoli, Sébastien M. R. Arnold, Vijay Vasudevan, Shubham Agrawal, Jason Riesa, Dmitry Lepikhin, Richard Tanburn, Srivatsan Srinivasan, Hyeontaek Lim, Sarah Hodkinson, Pranav Shyam, Johan Ferret, Steven Hand, Ankush Garg, Tom Le Paine, Jian Li, Yujia Li, Minh Giang, Alexander Neitz, Zaheer Abbas, Sarah York, Machel Reid, Elizabeth Cole, Aakanksha Chowdhery, Dipanjan Das, Dominika Rogozinska, Vitaly ´ Nikolaev, Pablo Sprechmann, Zachary Nado, Lukas Zilka, Flavien Prost, Luheng He, Marianne Monteiro, Gaurav Mishra, Chris Welty, Josh Newlan, Dawei Jia, Miltiadis Allamanis, Clara Huiyi Hu, Raoul de Liedekerke, Justin Gilmer, Carl Saroufim, Shruti Rijhwani, Shaobo Hou, Disha Shrivastava, Anirudh Baddepudi, Alex Goldin, Adnan Ozturel, Albin Cassirer, Yunhan Xu, Daniel Sohn, Devendra Sachan, Reinald Kim Amplayo, Craig Swanson, Dessie Petrova, Shashi Narayan, Arthur Guez, Siddhartha Brahma, Jessica Landon, Miteyan Patel, Ruizhe Zhao, Kevin Villela, Luyu Wang, Wenhao Jia, Matthew Rahtz, Mai Giménez, Legg Yeung, Hanzhao Lin, James Keeling, Petko Georgiev, Diana Mincu, Boxi Wu, Salem Haykal, Rachel Saputro, Kiran Vodrahalli, James Qin, Zeynep Cankara, Abhanshu Sharma, Nick Fernando, Will Hawkins, Behnam Neyshabur, Solomon Kim, Adrian Hutter, Priyanka Agrawal, Alex Castro-Ros, George van den Driessche, Tao Wang, Fan Yang, Shuo yiin Chang, Paul Komarek, Ross McIlroy, Mario Luciˇ c, Guodong Zhang, Wael ´ Farhan, Michael Sharman, Paul Natsev, Paul Michel, Yong Cheng, Yamini Bansal, Siyuan Qiao, Kris Cao, Siamak Shakeri, Christina Butterfield, Justin Chung, Paul Kishan Rubenstein, Shivani Agrawal, Arthur Mensch, Kedar Soparkar, Karel Lenc, Timothy Chung, Aedan Pope, Loren Maggiore, Jackie Kay, Priya Jhakra, Shibo Wang, Joshua Maynez, Mary Phuong, Taylor Tobin, Andrea Tacchetti, Maja Trebacz, Kevin Robinson, Yash Katariya, Se- bastian Riedel, Paige Bailey, Kefan Xiao, Nimesh Ghelani, Lora Aroyo, Ambrose Slone, Neil Houlsby, Xuehan Xiong, Zhen Yang, Elena Gribovskaya, Jonas Adler, Mateo Wirth, Lisa Lee, Music Li, Thais Kagohara, Jay Pavagadhi, Sophie Bridgers, Anna Bortsova, Sanjay Ghemawat, Zafarali Ahmed, Tianqi Liu, Richard Powell, Vijay Bolina, Mariko Iinuma, Polina Zablotskaia, James Besley, Da-Woon Chung, Timothy Dozat, Ramona Comanescu, Xiance Si, Jeremy Greer, Guolong Su, Martin Polacek, Raphaël Lopez Kaufman, Simon Tokumine, Hexiang Hu, Elena Buchatskaya, Yingjie Miao, Mohamed Elhawaty, Aditya Siddhant, Nenad Tomasev, Jinwei Xing, Christina Greer, Helen Miller, Shereen Ashraf, Aurko Roy, Zizhao Zhang, Ada Ma, Angelos Filos, Milos Besta, Rory Blevins, Ted Klimenko, Chih-Kuan Yeh, Soravit Changpinyo, Jiaqi Mu, Oscar Chang, Mantas Pajarskas, Carrie Muir, Vered Cohen, Charline Le Lan, Krishna Haridasan, Amit Marathe, Steven Hansen, Sholto Douglas, Rajkumar Samuel, Mingqiu Wang, Sophia Austin, Chang Lan, Jiepu Jiang, Justin Chiu, Jaime Alonso Lorenzo, Lars Lowe Sjösund, Sébastien Cevey, Zach Gleicher, Thi Avrahami, Anudhyan Boral, Hansa Srinivasan, Vittorio Selo, Rhys May, Konstantinos Aisopos, Léonard Hussenot, Livio Baldini Soares, Kate Baumli, Michael B. Chang, Adrià Recasens, Ben Caine, Alexander Pritzel, Filip Pavetic, Fabio Pardo, Anita Gergely, Justin Frye, Vinay Ramasesh, Dan Horgan, Kartikeya Badola, Nora Kassner, Subhrajit Roy, Ethan Dyer, Víctor Campos, Alex Tomala, Yunhao Tang, Dalia El Badawy, Elspeth White, Basil Mustafa, Oran Lang, Abhishek Jindal, Sharad Vikram, Zhitao Gong, Sergi Caelles, Ross Hemsley, Gregory Thornton, Fangxiaoyu Feng, Wojciech Stokowiec, Ce Zheng, Phoebe Thacker, Çaglar ˘ Ünlü, Zhishuai Zhang, Mohammad Saleh, James Svensson, Max Bileschi, Piyush Patil, Ankesh Anand, Roman Ring, Katerina Tsihlas, Arpi Vezer, Marco Selvi, Toby Shevlane, Mikel Rodriguez, Tom Kwiatkowski, Samira Daruki, Keran Rong, Allan Dafoe, Nicholas FitzGerald, Keren Gu-Lemberg, Mina Khan, Lisa Anne Hendricks, Marie Pellat, Vladimir Feinberg, James Cobon-Kerr, Tara Sainath, Maribeth Rauh, Sayed Hadi Hashemi, Richard Ives, Yana Hasson, YaGuang Li, Eric Noland, Yuan Cao, Nathan Byrd, Le Hou, Qingze Wang, Thibault Sottiaux, Michela Paganini, JeanBaptiste Lespiau, Alexandre Moufarek, Samer Hassan, Kaushik Shivakumar, Joost van Amersfoort, Amol Mandhane, Pratik Joshi, Anirudh Goyal, Matthew Tung, Andrew Brock, Hannah Sheahan, Vedant Misra, Cheng Li, Nemanja Rakicevi ´ c, Mostafa Dehghani, Fangyu Liu, Sid ´ Mittal, Junhyuk Oh, Seb Noury, Eren Sezener, Fantine Huot, Matthew Lamm, Nicola De Cao, Charlie Chen, Gamaleldin Elsayed, Ed Chi, Mahdis Mahdieh, Ian Tenney, Nan Hua, Ivan Petrychenko, Patrick Kane, Dylan Scandinaro, Rishub Jain, Jonathan Uesato, Romina Datta, Adam Sadovsky, Oskar Bunyan, Dominik Rabiej, Shimu Wu, John Zhang, Gautam Vasudevan, Edouard Leurent, Mahmoud Alnahlawi, Ionut Georgescu, Nan Wei, Ivy Zheng, Betty Chan, Pam G Rabinovitch, Piotr Stanczyk, Ye Zhang, David Steiner, Subhajit Naskar, Michael Azzam, Matthew Johnson, Adam Paszke, Chung-Cheng Chiu, Jaume Sanchez Elias, Afroz Mohiuddin, Faizan Muhammad, Jin Miao, Andrew Lee, Nino Vieillard, Sahitya Potluri, Jane Park, Elnaz Davoodi, Jiageng Zhang, Jeff Stanway, Drew Garmon, Abhijit Karmarkar, Zhe Dong, Jong Lee, Aviral Kumar, Luowei Zhou, Jonathan Evens, William Isaac, Zhe Chen, Johnson Jia, Anselm Levskaya, Zhenkai Zhu, Chris Gorgolewski, Peter Grabowski, Yu Mao, Alberto Magni, Kaisheng Yao, Javier Snaider, Norman Casagrande, Paul Suganthan, Evan Palmer, Geoffrey Irving, Edward Loper, Manaal Faruqui, Isha Arkatkar, Nanxin Chen, Izhak Shafran, Michael Fink, Alfonso Castaño, Irene Giannoumis, Wooyeol Kim, Mikołaj Rybinski, Ashwin Sreevatsa, Jen- ´ nifer Prendki, David Soergel, Adrian Goedeckemeyer, Willi Gierke, Mohsen Jafari, Meenu Gaba, Jeremy Wiesner, Diana Gage Wright, Yawen Wei, Harsha Vashisht, Yana Kulizhskaya, Jay Hoover, Maigo Le, Lu Li, Chimezie Iwuanyanwu, Lu Liu, Kevin Ramirez, Andrey Khorlin, Albert Cui, Tian LIN, Marin Georgiev, Marcus Wu, Ricardo Aguilar, Keith Pallo, Abhishek Chakladar, Alena Repina, Xihui Wu, Tom van der Weide, Priya Ponnapalli, Caroline Kaplan, Jiri Simsa, Shuangfeng Li, Olivier Dousse, Fan Yang, Jeff Piper, Nathan Ie, Minnie Lui, Rama Pasumarthi, Nathan Lintz, Anitha Vijayakumar, Lam Nguyen Thiet, Daniel An- dor, Pedro Valenzuela, Cosmin Paduraru, Daiyi Peng, Katherine Lee, Shuyuan Zhang, Somer Greene, Duc Dung Nguyen, Paula Kurylowicz, Sarmishta Velury, Sebastian Krause, Cassidy Hardin, Lucas Dixon, Lili Janzer, Kiam Choo, Ziqiang Feng, Biao Zhang, Achintya Singhal, Tejasi Latkar, Mingyang Zhang, Quoc Le, Elena Allica Abellan, Dayou Du, Dan McKinnon, Natasha Antropova, Tolga Bolukbasi, Orgad Keller, David Reid, Daniel Finchelstein, Maria Abi Raad, Remi Crocker, Peter Hawkins, Robert Dadashi, Colin Gaffney, Sid Lall, Ken Franko, Egor Filonov, Anna Bulanova, Rémi Leblond, Vikas Yadav, Shirley Chung, Harry Askham, Luis C. Cobo, Kelvin Xu, Felix Fischer, Jun Xu, Christina Sorokin, Chris Alberti, Chu-Cheng Lin, Colin Evans, Hao Zhou, Alek Dimitriev, Hannah Forbes, Dylan Banarse, Zora Tung, Jeremiah Liu, Mark Omernick, Colton Bishop, Chintu Kumar, Rachel Sterneck, Ryan Foley, Rohan Jain, Swaroop Mishra, Jiawei Xia, Taylor Bos, Geoffrey Cideron, Ehsan Amid, Francesco Piccinno, Xingyu Wang, Praseem Banzal, Petru Gurita, Hila Noga, Premal Shah, Daniel J. Mankowitz, Alex Polozov, Nate Kushman, Victoria Krakovna, Sasha Brown, MohammadHossein Bateni, Dennis Duan, Vlad Firoiu, Meghana Thotakuri, Tom Natan, Anhad Mohananey, Matthieu Geist, Sidharth Mudgal, Sertan Girgin, Hui Li, Jiayu Ye, Ofir Roval, Reiko Tojo, Michael Kwong, James LeeThorp, Christopher Yew, Quan Yuan, Sumit Bagri, Danila Sinopalnikov, Sabela Ramos, John Mellor, Abhishek Sharma, Aliaksei Severyn, Jonathan Lai, Kathy Wu, Heng-Tze Cheng, David Miller, Nicolas Sonnerat, Denis Vnukov, Rory Greig, Jennifer Beattie, Emily Caveness, Libin Bai, Julian Eisenschlos, Alex Korchemniy, Tomy Tsai, Mimi Jasarevic, Weize Kong, Phuong Dao, Zeyu Zheng, Frederick Liu, Fan Yang, Rui Zhu, Mark Geller, Tian Huey Teh, Jason Sanmiya, Evgeny Gladchenko, Nejc Trdin, Andrei Sozanschi, Daniel Toyama, Evan Rosen, Sasan Tavakkol, Linting Xue, Chen Elkind, Oliver Woodman, John Carpenter, George Papamakarios, Rupert Kemp, Sushant Kafle, Tanya Grunina, Rishika Sinha, Alice Talbert, Abhimanyu Goyal, Diane Wu, Denese Owusu-Afriyie, Cosmo Du, Chloe Thornton, Jordi Pont-Tuset, Pradyumna Narayana, Jing Li, Sabaer Fatehi, John Wieting, Omar Ajmeri, Benigno Uria, Tao Zhu, Yeongil Ko, Laura Knight, Amélie Héliou, Ning Niu, Shane Gu, Chenxi Pang, Dustin Tran, Yeqing Li, Nir Levine, Ariel Stolovich, Norbert Kalb, Rebeca Santamaria-Fernandez, Sonam Goenka, Wenny Yustalim, Robin Strudel, Ali Elqursh, Balaji Lakshminarayanan, Charlie Deck, Shyam Upadhyay, Hyo Lee, Mike Dusenberry, Zonglin Li, Xuezhi Wang, Kyle Levin, Raphael Hoffmann, Dan Holtmann-Rice, Olivier Bachem, Summer Yue, Sho Arora, Eric Malmi, Daniil Mirylenka, Qijun Tan, Christy Koh, Soheil Hassas Yeganeh, Siim Põder, Steven Zheng, Francesco Pongetti, Mukarram Tariq, Yanhua Sun, Lucian Ionita, Mojtaba Seyedhosseini, Pouya Tafti, Ragha Kotikalapudi, Zhiyu Liu, Anmol Gulati, Jasmine Liu, Xinyu Ye, Bart Chrzaszcz, Lily Wang, Nikhil Sethi, Tianrun Li, Ben Brown, Shreya Singh, Wei Fan, Aaron Parisi, Joe Stanton, Chenkai Kuang, Vinod Koverkathu, Christopher A. Choquette-Choo, Yunjie Li, TJ Lu, Abe Ittycheriah, Prakash Shroff, Pei Sun, Mani Varadarajan, Sanaz Bahargam, Rob Willoughby, David Gaddy, Ishita Dasgupta, Guillaume Desjardins, Marco Cornero, Brona Robenek, Bhavishya Mittal, Ben Albrecht, Ashish Shenoy, Fedor Moiseev, Henrik Jacobsson, Alireza Ghaffarkhah, Morgane Rivière, Alanna Walton, Clément Crepy, Alicia Parrish, Yuan Liu, Zongwei Zhou, Clement Farabet, Carey Radebaugh, Praveen Srinivasan, Claudia van der Salm, Andreas Fidjeland, Salvatore Scellato, Eri Latorre-Chimoto, Hanna Klimczak-Plucinska, David Bridson, Dario ´ de Cesare, Tom Hudson, Piermaria Mendolicchio, Lexi Walker, Alex Morris, Ivo Penchev, Matthew Mauger, Alexey Guseynov, Alison Reid, Seth Odoom, Lucia Loher, Victor Cotruta, Madhavi Yenugula, Dominik Grewe, Anastasia Petrushkina, Tom Duerig, Antonio Sanchez, Steve Yadlowsky, Amy Shen, Amir Globerson, Adam Kurzrok, Lynette Webb, Sahil Dua, Dong Li, Preethi Lahoti, Surya Bhupatiraju, Dan Hurt, Haroon Qureshi, Ananth Agarwal, Tomer Shani, Matan Eyal, Anuj Khare, Shreyas Rammohan Belle, Lei Wang, Chetan Tekur, Mihir Sanjay Kale, Jinliang Wei, Ruoxin Sang, Brennan Saeta, Tyler Liechty, Yi Sun, Yao Zhao, Stephan Lee, Pandu Nayak, Doug Fritz, Manish Reddy Vuyyuru, John Aslanides, Nidhi Vyas, Martin Wicke, Xiao Ma, Tay- lan Bilal, Evgenii Eltyshev, Daniel Balle, Nina Martin, Hardie Cate, James Manyika, Keyvan Amiri, Yelin Kim, Xi Xiong, Kai Kang, Florian Luisier, Nilesh Tripuraneni, David Madras, Mandy Guo, Austin Waters, Oliver Wang, Joshua Ainslie, Jason Baldridge, Han Zhang, Garima Pruthi, Jakob Bauer, Feng Yang, Riham Mansour, Jason Gelman, Yang Xu, George Polovets, Ji Liu, Honglong Cai, Warren Chen, XiangHai Sheng, Emily Xue, Sherjil Ozair, Adams Yu, Christof Angermueller, Xiaowei Li, Weiren Wang, Julia Wiesinger, Emmanouil Koukoumidis, Yuan Tian, Anand Iyer, Madhu Gurumurthy, Mark Goldenson, Parashar Shah, MK Blake, Hongkun Yu, Anthony Urbanowicz, Jennimaria Palomaki, Chrisantha Fernando, Kevin Brooks, Ken Durden, Harsh Mehta, Nikola Momchev, Elahe Rahimtoroghi, Maria Georgaki, Amit Raul, Sebastian Ruder, Morgan Redshaw, Jinhyuk Lee, Komal Jalan, Dinghua Li, Ginger Perng, Blake Hechtman, Parker Schuh, Milad Nasr, Mia Chen, Kieran Milan, Vladimir Mikulik, Trevor Strohman, Juliana Franco, Tim Green, Demis Hassabis, Koray Kavukcuoglu, Jeffrey Dean, and Oriol Vinyals. 2023. Gemini: A family of highly capable multimodal models.
Тони Вил, Экатерина Шоува и Бита Бейгман Клебанов. 2016. Метафора: вычислительная перспектива. Morgan & Claypool Publishers.
Сара Вигрефф, Джек Хессель, Свабха Сэйамдипта, Марк Ридл и Йецзин Чой. 2022. Переосмысление сотрудничества Human-AI для создания объяснений свободного текста. В материалах Конференции Северной Америки в Северной Америке Ассоциации вычислительной лингвистики: технологии человеческого языка, страницы 632–658, Сиэтл, США. Ассоциация вычислительной лингвистики.
Сара Вигрефф и Ана Марасович. 2021. Научите меня объяснять: обзор наборов данных для объяснимой обработки естественного языка. В материалах систем обработки нейронной информации отслеживает наборы данных и контрольные показатели, том 1. Curran.
Адина Уильямс, Никита Нанья и Сэмюэль Боуман. 2018. Корпус с широким покрытием для понимания предложений посредством вывода. В материалах конференции Северной Америки в Северной Америке Ассоциации вычислительной лингвистики: технологии человеческого языка, том 1 (длинные документы), стр. 1112–1122, Новый Орлеан, Луизиана. Ассоциация вычислительной лингвистики.
Нин Се, Фарли Лай, Дерек Доран и Асим Кадав. 2019. Визуальное введение: новая задача для мелкозернистого понимания изображения. Arxiv, ABS/1901.06706.
Рон Йосеф, Йонатан Биттон и Дафна Шахаф. 2023. IRFL: распознавание изображения фигуративного языка. В результатах Ассоциации вычислительной лингвистики: EMNLP 2023, стр. 1044–1058, Сингапур. Ассоциация вычислительной лингвистики.
Сян Юэ, Юансхенг Н.И., Кай Чжан, Тянью Чжэн, Руоки Лю, Г. Г. Чжан, Сэмюэл Стивенс, Донгфу Цзян, Вейминг Рен, Юксюан Сан, Конг Вей, Ботао Ю, Руибин Юан, Ренлан, Мин Инь, Бойан Занг. Венхао Хуан, Хуан Сан, Ю Су и Венху Чен. 2024. MMMU: массовый междисциплинальный многомодальный эталон понимания и рассуждения для экспертов AGI. В материалах CVPR.
Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger и Yoav Artzi. 2020. Bertscore: оценка генерации текста с Bert. В Международной конференции по обучению.
Цзянинг Чжоу, Хонгю Гонг и Сума Бхат. 2021. Пирог: параллельное идиоматическое выражение корпуса для идиоматического генерации предложений и перефразирования. В материалах 17 -го семинара по выражениям с несколькими словами (MWE 2021), стр. 33–48, онлайн. Ассоциация вычислительной лингвистики.
Калеб Зимс, Уильям Худ, Омар Шейх, Цзяо Чен, Чжэхао Чжан и Дийи Ян. 2024. Могут ли крупные языковые модели преобразовать вычислительные социальные науки? Вычислительная лингвистика, страницы 1–55.
A. Статистика набора данных
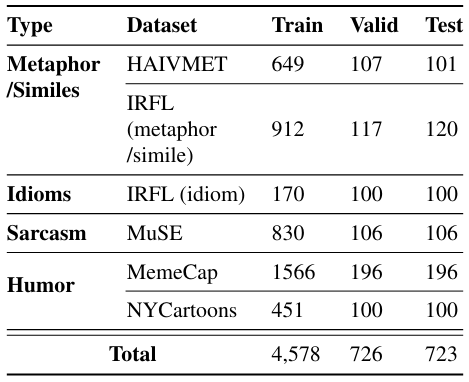
В таблице 7 показано количество выборок из каждого набора данных источника, которые включены в случайно выбранную обучение, валидацию и удерживающие тесты.
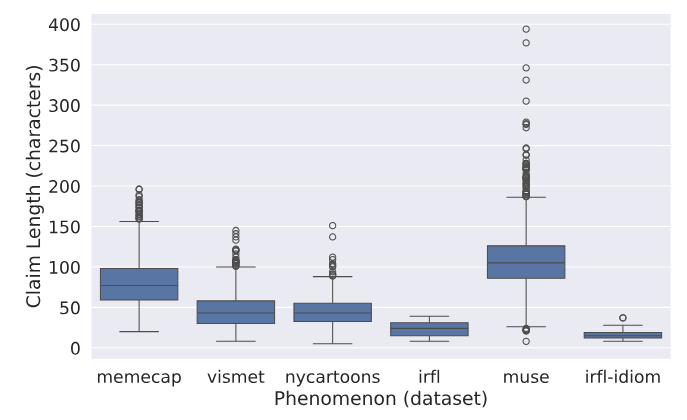
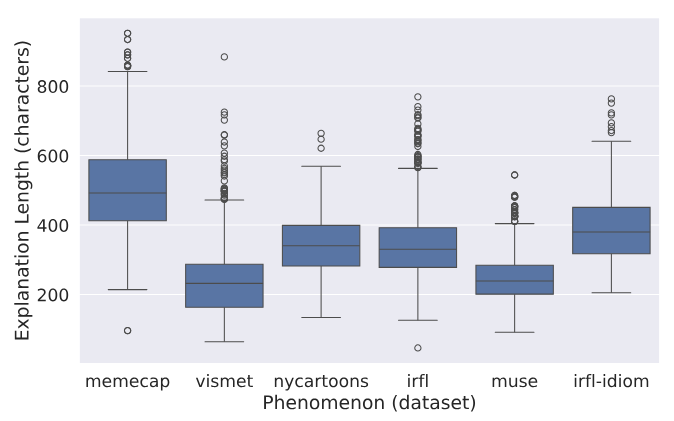
Распределение длиныСредняя длина претензии в V-Flute составляет ≈ 61 символа. Средняя длина объяснения составляет ≈ 367 символов. На рисунке 8 показано распределение длины претензий, а на рисунке 9 показано распределение длина объяснения по набору данных источника. Мы вручную подтвердили, что экземпляры выбросов верны.
B API модели гиперпараметры
B.1 Клод
• Название модели: Claude-3-Opus-201240229
• Max Tokens: 256
• Изображения более 5 МБ были изменены
B.2 GPT-4
• Имя модели: GPT-4-1106-Vision-Preview
• Max Tokens: 256
• Семя: 42
• Деталь URL изображения: «Высокий»
B.3 Близнецы
• Название модели: Близнечное протокол
• Max Tokens: 256
• Настройки безопасности: «Блок нет»
• Изображения более 5 МБ были изменены
C. тонкая настройка гиперпараметров
Мы используем Lora (Hu et al., 2022), чтобы точно настроить модели. Мы используем одни и те же гиперпараметры для всех тонких настрой, изложенных в Приложении C, и используем раннюю остановку на основе V-Flute Valite, чтобы предотвратить переосмысление. Из -за размера данных мы тренируемся только для 3 эпох как в злом, так и в злом+Vflute, но мы сохранили промежуточные шаги и выбрали контрольную точку, где потери проверки являются самыми низкими.
Тонкая настройка
• Семя: 42
• Vision Tower: Openai-Clip-Vit-Large-Patch14- 336
• Количество тренировочных эпох: 3
• Размер партии поезда (на устройство): 16
• Размер партии Eval (на устройство): 4
• Скорость обучения: 2E-5
• Затухание веса: 0
• Коэффициент разминки: 0,03
• Тип планировщика: косинус
• Количество эпох: 4 для зла и зла + vflute, 10 для vflute
• MM-проектор-тип: MLP2X Gelu
• MM-Vision-Select-Layer: -2
• MM-USE-IM-Start-END: ложь
• MM-USE-IM-PATCH-TOKEN: FALSE
• Изображение-Асплекс-Ратио: Pad
• Групповая длина: ложь
Лора
• Lora R: 128
• Лора Альфа: 256
• MM-проектор-LR: 2E-5
Конфигурация DeepSpeed
• FP16 включен: Auto
• BF16 включен: Auto
• Размер микро -партии на GPU: Авто
• Размер партии поезда: Авто
• Градиент
• Стадия нулевой оптимизации: 3
Инструкции по обучению и выводу
Все модели оцениваются с использованием поиска пучка с n = 3, температура 0, максимальная длина 256. В случае генерирования графиков сцен для метода композиционной цепи мыслей мы устанавливаем максимальную длину на 256 для стадии генерации графа, как это рекомендовано Mitra et al. (2023). Модели API оцениваются с помощью гиперпараметров по умолчанию. Мы форматируем все данные о тонкой настройке в формате инструкции после Llava (Liu et al., 2023a). Чтобы избежать переосмысления конкретной инструкции для этой задачи, мы генерируем 20 аналогичных инструкций, используя LLM (CHATGPT-4) и случайным образом назначаем одну из них каждому экземпляру в наборе обучения, проверки и тестирования. То же инструкции были отобраны для набора данных E-VIL. В таблице 8 показаны 20 используемых инструкций.
D. Подсказки для LLMS
D.1 Haivmet
D.1.1 Одно выстрел для получения объяснений
Мы описываем наши одноразовые подсказки, предоставленные LLM (GPT-3.5-Turbo-Instruct-0914) для создания объяснений взаимосвязи EntailementContradication. Обратитесь к Таблице 9 для подробной подсказки.
D.2 Irfl
D.2.1 Приглашение с нулевым выстрелом для получения объяснений
Мы предоставляем нашу подсказку с нулевым выстрелом, предоставленную LLM (GPT-4-Vision-Preview) для генерации объяснений, с учетом претензии и изображения. См. Таблицу 10 для подробной подсказки.
D.3 Muse
D.3.1 несколько выстрелов для получения противоположных претензий
Мы предоставляем наше несколько выстрелов, предоставленных LLM ((GPT-4-0613)) для создания противоположных претензий. См. Таблицу 11 для подробной подсказки.
D.3.2 Приглашение с нулевым выстрелом для перефразирования
Мы предоставляем нашу подсказку с нулевым выстрелом, предоставленную LLM (GPT-4-Vision-Preview) для переосмысления объяснений, учитывая утверждение и объяснение работника толпы. См. Таблицу 12 для подробной подсказки.
D.4 Memecap
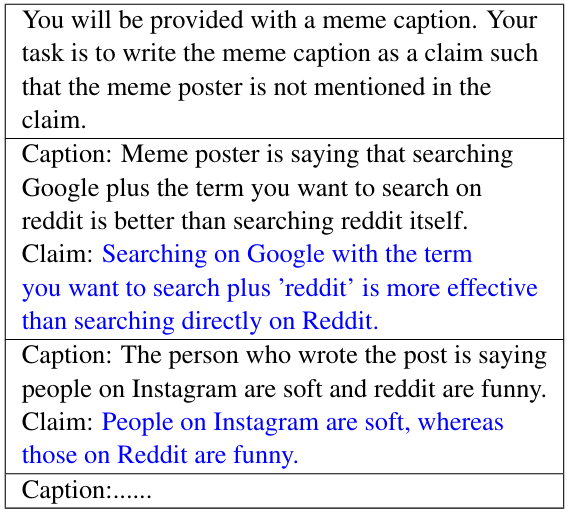
D.4.1 несколько выстрелов для создания влечет за собой претензии
Мы описываем наши несколько выстрелов, предоставленных LLM (GPT-4-0613) для создания введенных претензий в рамках трубопровода. Обратитесь к Таблице 13 для подробной подсказки.
D.4.2 Приглашение с нулевым выстрелом для проверки введенных претензий
Мы описываем нашу подсказку с нулевым выстрелом, предоставленную LLM (GPT-4-Vision-Preview) для проверки претензий, полученных на предыдущем этапе. См. Таблицу 14 для подробной подсказки.






D.4.3 несколько выстрелов для получения противоположных претензий
Мы предоставляем наше несколько выстрелов, предоставленных LLM ((GPT-4-0613)) для создания противоположных претензий. См. Таблицу 15 для подробной подсказки.
D.4.4 Приглашение с нулевым выстрелом для получения объяснений
Мы предоставляем нашу подсказку с нулевым выстрелом, предоставленную LLM (GPT-4-Vision-Preview) для генерации объяснений, с учетом претензии и изображения. См. Таблицу 16 для подробной подсказки.
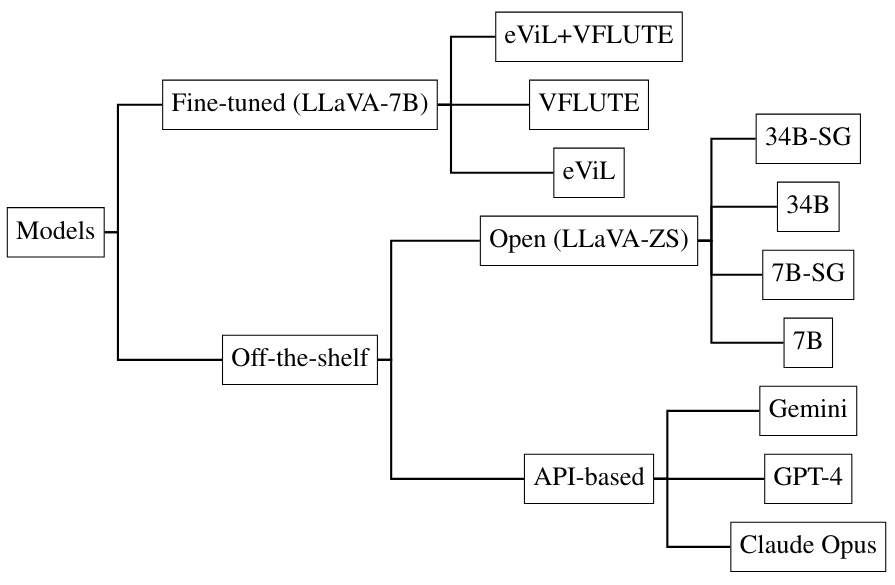
E. Модельная таксономия
Таксономия всех моделей, используемых для автоматической оценки, показана на рисунке 10.


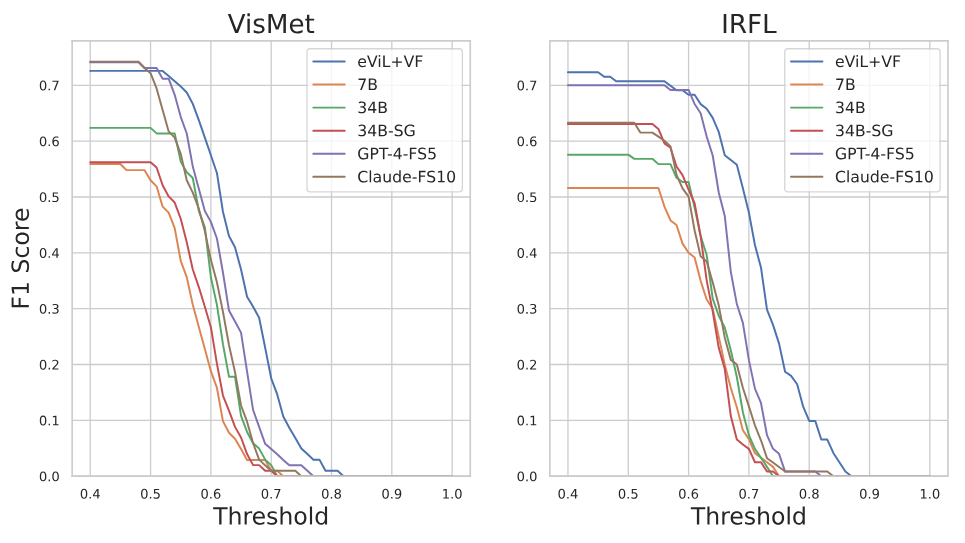
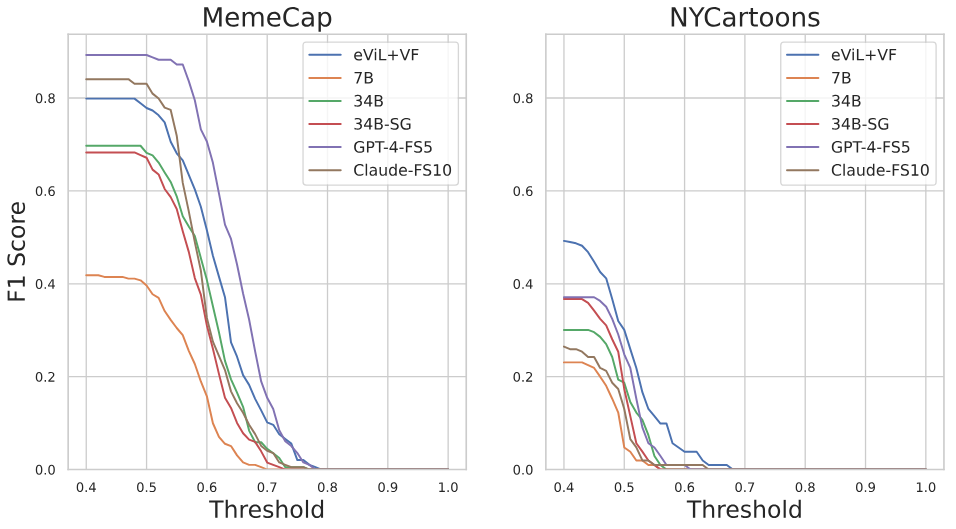
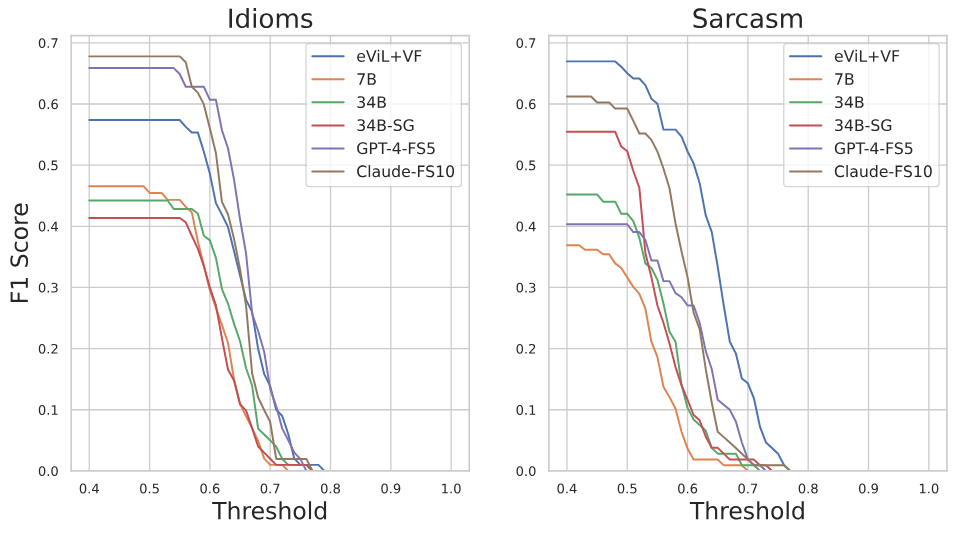
F. Pos-Phenomenon Performance
На рисунке 11 мы показываем производительность моделей с помощью явлений и набора данных по различным пороговым значениям.
Г. Аннотаторский набор и компенсация
Все набранные аннотаторы имеют значительный опыт в переносном понимании языка (имея формальное образование в лингвистике или литературе). Аннотаторы были набраны через платформу Upwork. Все они свободны или местный/двуязычный уровень на английском языке. Все они справедливо компенсируются от 20 до 25 долларов США в час с самоотчетным временем, необходимым для выполнения задач.
Рисунок 11: Производительность моделей по явлению.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Оригинал