
Переопределение операций данных с помощью программирования потока данных в кокоиндексе
18 июля 2025 г.В большинстве рамках оркестровки данных способ обработки данных является запоздалой мыслью. Вы создаете рабочие процессы, компоненты проводов вместе и надеетесь, что данные ведет себя так, как вы ожидаете. Под капотом значения мутируют, трансформируются неявно или скрываются в состоянии компонентов. Если вы любите эту статью, пожалуйста, бросьте нам звезду ⭐ наGitHub RepoЧтобы помочь нам расти.
Но Cocoindex переворачивает этот подход к голове.
Проработав в этой области в течение многих лет, мы наблюдали, что побочные эффекты в традиционных системах часто приводят к повышению сложности, отладки и непредсказуемому поведению. Этот опыт побудил нас принять подход к программированию чистого потока данных в Cocoindex, где преобразования данных являются ясными, неизменными и прослеживаемыми, обеспечивая надежность и простоту по всему трубопроводу.
Вместо того, чтобы рассматривать данные как черный ящик, который проходит между задачами,Кокоиндекс охватывает парадигму программирования потока данных- где данные и их преобразованиянаблюдаемый, прослеживаемый и неизменныйПолем Этот сдвиг делает мир разницы, когда вы работаете со сложными трубопроводами, особенно в извлечении знаний, здании графика и семантическом поиске.
Что такое программирование потока данных?
Программирование потока данныхэто декларативная модель программирования, где:
- Данные «потоки» через графиктрансформаций.
- Каждое преобразование естьчистый- Нет скрытых побочных эффектов, нет государственных мутаций.
- Структура вашего кода отражает структуру вашей логики данных.
Это принципиально отличается от оркестров рабочих процессов, где задачи организуются во времени, а данные часто являются непрозрачными.
В кокосочеДанные являются основной единицей композиции, не задачи.
Простой поток данных в кокоиндексе
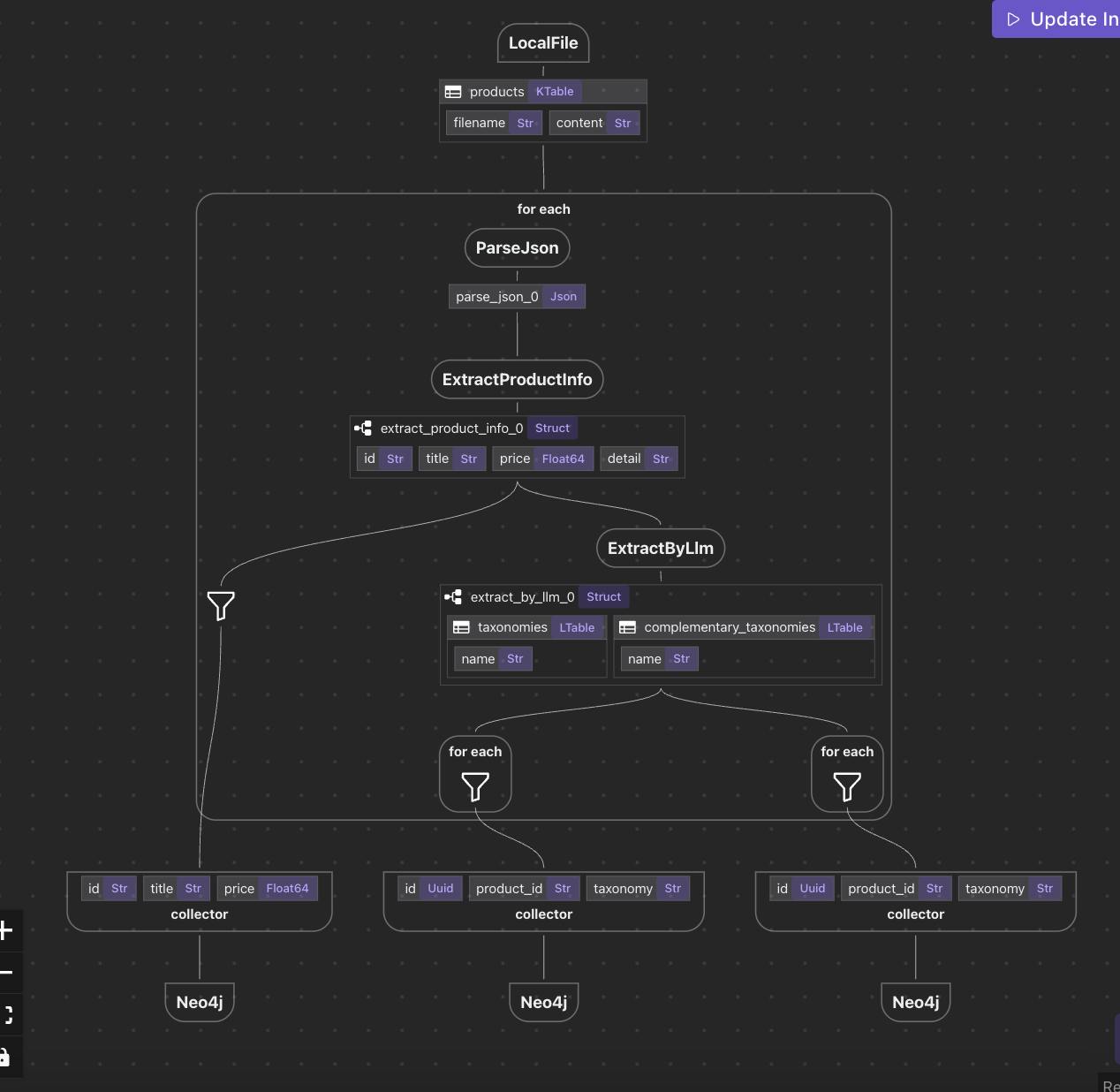
Давайте посмотрим на концептуальный поток данных:
Parse files → Data Mapping → Data Extraction → Knowledge Graph
Каждая стрелка представляет собой преобразование: функция, которая принимает данные и создает новые данные. Результатом является цепочка прослеживаемых шагов, где вы можете осмотреть как входы, так и выходы - в каждой точке.
Каждая стрелка представляет собой преобразование: функция, которая принимает данные и создает новые данные. Результатом является цепочка прослеживаемых шагов, где вы можете осмотреть как входы, так и выходы - в каждой точке.
Каждая коробка в этой диаграмме представляет собойдекларативная трансформация- Нет побочных эффектов, нет скрытой логики. Просто ясно, видимый поток данных.
Пример кода: декларативный и прозрачный
Вот как этот поток может выглядеть в кокодекс:
# ingest
data['content'] = flow_builder.add_source(...)
# transform
data['out'] = data['content']
.transform(...)
.transform(...)
# collect data
collector.collect(...)
# export to db, vector db, graph db ...
collector.export(...)
Красота здесь в том, что:
- Каждый
.transform()детерминированный и прослеживаемый. - Вы не пишете логику CRUD - кокосоиндекс фигурирует.
- Ты можешьнаблюдатьВсе данные до и после любого этапа.
Нет обязательных мутаций - просто логика
В традиционных системах вы можете написать:
if entity_exists(id):
update_entity(id, data)
else:
create_entity(id, data)
Но в кокоиндекс вы говорите:
data['entities'] = data['mapped'].transform(extract_entities)
И система выясняет, подразумевает ли это создание, обновление или удаление. ЭтотАннотация логика жизненного цикла, позволяя вам сосредоточиться на том, что действительно важно: как должны быть ваши данныеполученный, не как это должно храниться.
Почему это важно: преимущества потока данных в кокоиндексе
🔎 Полная линия данных
Хотите знать, откуда взялся кусочек знаний? С моделью DataFlow от CocoIndex вы можете отследить ее обратно через каждое преобразование в исходный файл или поле.
🧪 Наблюдаемость на каждом этапе
Cocoindex позволяет наблюдать данные на любом этапе. Это делает отладку и аудитзначительно прощечем в непрозрачных трубопроводных системах.
🔄 Реакционная способность
Изменить источник? Каждое преобразование вниз по течению автоматически переоценивается. Кокоиндекс позволяет реактивные трубопроводы без дополнительной сложности.
🧘♀ Декларативная простота
Вы не имеете дело с мутацией, ошибками в синхронизации состояния или ручной оркестровкой. Вы определяете логику один раз - и позволяете данным течь.
Сдвиг парадигмы в приложениях по строительству данных
Модель программирования потока данных Cocoindex - это не просто особенность - этоФилософский сдвигПолем Это меняет то, как вы думаете о обработке данных:
- ОтЗадача оркестровка→ наПреобразование данных
- Отизменчивые трубопроводы→ нанеизменные наблюдаемые
- Отимперативный код CRUD→ надекларативные формулы
Это делает ваш трубопроводлегче тестировать, легче рассуждать и легче расширитьПолем
Последние мысли
Если вы создаете трубопроводы для извлечения, поиска или графиков знаний,Модель программирования потока данных Cocoindex предлагает новый вид ясностиПолем Вам больше не нужно жонглировать операциями хранения или отслеживать изменения состояния - вы просто определяете, как трансформируются данные.
И это будущее, которое стоит построить.
Мы постоянно улучшаемся, и скоро появятся больше функций и примеров. Если вы любите эту статью, пожалуйста, бросьте нам звезду ⭐ наGitHub RepoЧтобы помочь нам расти.
Оригинал
Recent Post
-
Конец общей аннотации в здравоохранении: визуализация сердца показывает, почему
20 августа 2025 г. -
Действительно ли запрет крипто банкоматов о защите людей - или защите банков?
20 августа 2025 г. -
Все, что я узнал (трудный путь) как начинающий основатель AI SaaS
20 августа 2025 г. -
Секретный приоритет Chatgpt: держать вас в подключении к праву
20 августа 2025 г. -
Как агенты ИИ становятся цифровыми сотрудниками бизнеса
20 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Астрофизика
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика
- Развлечения
- ИТ и автоматизация
- Криптовалюты и блокчейн
- История и идеология
- Медицина и политика
- Личная жизнь миллиардеров
- Образование и Политика
- Туризм и отдых
- Психология и искусственный интеллект
- Удаленная работа и производительность
- Выживание
- Управление командами
- Разработка
- Международная торговля
- Корпоративная ответственность
- Социальные сети и общество
- Управление серверами
- Индустрия компьютерных игр
- Политика и климат
- Онлайн-игры
- Медицинская отрасль
- Искусственный интеллект и технологии
- Религия и мораль
- Путешествия
- Социальные сети и информация
- Технологии и медиа
- Технологии и свобода
- Электронная коммерция
- Бизнес и управление
- Психическое здоровье и технологии
- Технологии и устойчивое развитие
- Технологии и социальные сети
- Профессии
- Экономика и промышленность
- Технологии и трудоустройство
- Иммиграционная политика
- Продуктивность и фокус
- Технологии и робототехника
- Свобода слова
- Психология и власть
- Социальные сети и онлайн-платформы
- Технологии и Права Человека
- СМИ и журналистика
- Окружающая среда и здоровье
- Технологии и сервисы
- Индустрия игр
- Программирование и ИИ
- Медиа и пропаганда
- Социальная сфера
- Социальные сети и общественное мнение
- Поп-культура
- Сервисы потокового вещания
- Рынок развлечений
- Социальные медиа и политика
- Технологии и информация
- Медиа и развлечения
- Квантовая криптография
- Искусственный интеллект в индустрии развлечений
- Технологии и коммуникация
- Индустрия программирования
- Финансовая безопасность
- Международные отношения
- Бизнес и лидерство
- Технологические новости и аналитика
- Программное обеспечение и технологии
- Предпринимательство и малый бизнес
- Политика и общественный контроль
- Здравоохранение и политика
- Управление персоналом и эффективность разработки
- Технологии и ИТ‑управление
- Свобода слова и дезинформация
- Веб-дизайн и разработка
- Веб‑разработка и карьера
- Культура и общество
- Цифровые права и свобода слова
- Безопасность и искусственный интеллект
- Технологии и искусство
- Мобильные приложения
- Продуктивность