

Rag Systems преодолевает барьеры языковых моделей: вот как
25 июля 2025 г.Большие языковые модели (LLMS) очень популярны в мире программного обеспечения в наши дни. Они вводят новые статьи, сообщения в блогах, курсы и модели от ведущих компаний в нашей отрасли, таких как Meta, Huggingface, Microsoft и т. Д., Которые требуют, чтобы мы внимательно следили за новыми технологиями.
Мы решили написать несколько коротких информативных статей, чтобы представить эти темы и быть в курсе новейших технологий. Первая тема, которую мы рассмотрим, будет тряпкой (поколение поиска-августа).
Мы создадим серию статей по теме, которую мы определили, с тремя различными статьями, которые полезны и дополняют друг друга. В этой статье мы начинаем нашу серию с определения и базовой информации моделей RAG.
Крупные языковые модели вошли в каждый аспект нашей жизни. Мы могли бы сказать, что они произвели революцию в поле. Тем не менее, они не такие плавные инструменты, как мы любим их называть. У него также есть серьезный недостаток: он верен своему обучению. Это остается верным данным, на которые он был обучен. Они не могут отклониться от этого. Модель, которая завершила обучение в ноябре 2022 года, не сможет освоить новости, законы, технологические разработки и т. Д., Которые появились в январе 2023 года.
Это потому, что его разработка была завершена до этой даты. Конечно, эта проблема не осталась нерешенной, и был введен новый продукт, новая система. Система тряпичной (поисковой генерации) появилась, чтобы предоставить вам актуальную информацию, когда вам это нужно. В остальной части нашей статьи давайте внимательно рассмотрим как систему, созданную моделью LLM, так и системой Rag, один за другим, чтобы узнать их.
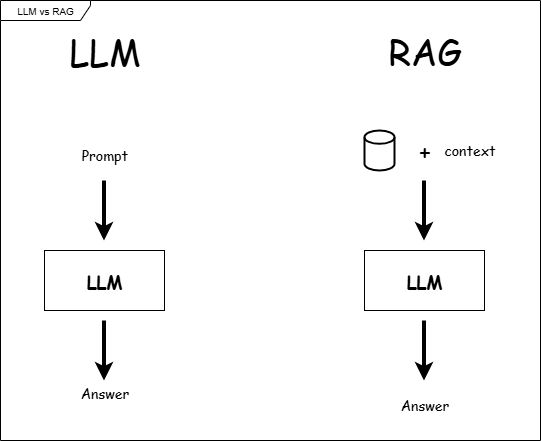
Доступ к информации в моделях LLM
Принцип работы крупных языковых моделей основан на данных, преподаваемых во время обучения, другими словами, статическими знаниями. Они не имеют возможности извлекать внешние данные любыми средствами. Чтобы привести пример, рассмотрим ребенка. Если мы отрежем внешнее общение этого ребенка и научим его только английскому, мы не сможем услышать от них ни одного китайского слова.
Это потому, что мы воспитали ребенка, который свободно говорит на английском языке, а не на китайском языке. Сократив их связь с внешним миром, мы также ограничили их способность учиться на внешних источниках. Как и этот ребенок, модели LLM также наполнены базовыми знаниями, но закрыты для внешних данных.
Другая характеристика моделей LLM заключается в том, что они черные ящики. Эти модели не полностью осознают, почему они выполняют операции, которые они выполняют. Они основывают свои расчеты исключительно на математических операциях. Спросите любую модель LLM: «Почему вы дали этот ответ?» Вы, вероятно, слишком сильно его толкаете. Они не отвечают на вопросы посредством рассуждений или исследований. Ключевое слово здесь: «Почему?» Мы также можем считать это ошибкой в моделях LLM.
Чтобы лучше понять эту структуру, давайте рассмотрим пример из области здравоохранения. Когда пользователь спрашивает: «У меня боль в лице и глазах, и постоянная постназальная капель. Что мне делать?», Модель LLM может ответить: «Боль в лице и глазах, а постназальная капель может быть признаками синусита. Пожалуйста, проконсультируйтесь с врачом. Острый синусит лечится антибиотиками. Помимо медикации, вы можете использовать спрез, как соли, такая с соленой.
До этого момента все кажется нормальным. Но если мы спросим модель: «Почему вы дали этот ответ?» После этого ответа все становится сложным. Причина, по которой модель предоставила этот ответ, заключается в том, что слова «боль в лице» и «носовая капель» часто появлялись вместе со словом «синусит» в учебных данных. Эти модели предпочитают хранить информацию в своей памяти в качестве статистического шаблона. Математические выражения важны для моделей LLM.
Поскольку он не предпочитает хранить информацию в своей памяти на основе источников, он отвечает на вопрос и мгновенно удовлетворяет большинству людей, но когда люди с более следственным характером спрашивают модель: «Почему вы дали этот ответ?», Модель не дает никакого объяснительного ответа. Я считаю, что теперь у нас есть достаточное понимание моделей LLM. Теперь мы можем обсудить систему RAG и ее решения этих проблем.
Тряпка: комбинирование LLM с системами поиска
Rag Systems предлагает инновации по сравнению с системами, основанными на моделях Pure LLM. Одним из них является то, что они работают с динамической информацией, а не статической информацией, такой как модели LLM. Другими словами, они также сканируют внешние источники, не ограничиваясь данными, на которых они были обучены. Первый "R" в тряпке обозначает поиск. Роль компонента поиска состоит в том, чтобы выполнить поисковые операции.
Генератор является вторым основным компонентом, и его роль состоит в том, чтобы сгенерировать правильный ответ на основе возврата данных. В этой статье мы кратко рассмотрим принцип работы RAG: поиск информации из внешних источников и получает документы, относящиеся к вопросу пользователя, разбивая их на мелкие части, называемые «кусочками».
Он векторирует эти куски и вопрос пользователя, а затем генерирует наиболее эффективный ответ, изучая соответствие между ними. Эта задача создания ответа выполняется «поколением». Мы подробно обсудим это в следующей статье в этой серии. Эти основные компоненты, которые составляют тряпичные системы, делают его более сильной структурой. Они мешают им застрять в статической информации, такой как модели Pure LLM. Rag Systems предлагает значительные преимущества, особенно во многих областях, которые требуют актуальной информации. Например, вы можете создать модель врача в области медицины.
Поскольку ваша модель будет служить жизненно важной области, у нее не будет устаревшей или неполной информации. Медицинский мир, как и ИТ -сектор, развивается каждый день, и выдвигаются новые исследования. Поэтому ожидается, что ваша модель оведите даже последние исследования. В противном случае вы рискуете подвергать опасности человеческую жизнь вводящей в заблуждение моделью. В таких случаях системы, поддерживаемые RAG, устраняют проблему устаревшей информации, подключаясь к внешним базам данных.
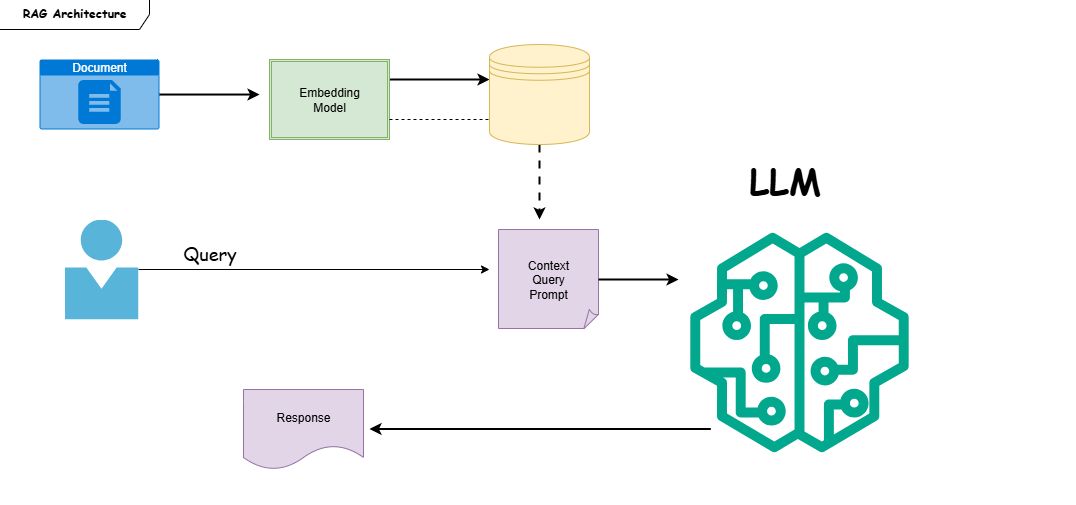
Основная разница между Rag Systems и LLM -моделями является основная философия Rag: «Не храните информацию, получайте доступ к ней, когда вам это нужно!» В то время как чистые крупные языковые модели хранят информацию в своих воспоминаниях и дают ответы после обучения, тряпичные системы получают доступ к информации, поиска и сканирования снаружи, когда они нуждаются в ней, в соответствии с их философией.
Так же, как человек, ищущий интернет, это преодолевает один из самых значительных недостатков моделей Pure LLM: их религиозность памяти. Чтобы дополнительно проиллюстрировать нашу точку зрения, мы можем сравнить эти две системы.
Сценарий:
Пользователь: «Каков уровень инфляции в декабре 2024 года Соединенных Штатов?»
LLM: «Согласно данным декабря 2022 года, это было 6,5%». (Не обновленный ответ)
Тряпка:
- Получает данные в декабре 2024 года из надежного источника или базы данных (Всемирный банк, торговля экономикой и т. Д.).
- LLM использует эти данные и отвечает: «Согласно торговой экономике, инфляция в Соединенных Штатах за декабрь 2024 года объявляется как 2,9%».
Давайте кратко сравним то, что мы обсуждали до сих пор, и представим его в таблице ниже.
Функции | LLM (статическая модель) | Тряпка (поколение поиска-аугментирования) |
|---|---|---|
Информация | Ограничено данными обучения | Может получить информацию в реальном времени из внешних источников |
Текущий уровень | Низкий | Высокий |
Прозрачность | Источник решения не может быть раскрыт (черный ящик) | Источник можно цитировать |
В заключение, чтобы кратко изложить суммирование, в то время как модели LLM ограничены данными, на которые они обучены, RAG Systems создаются не только на конкретной модели LLM и обладают базовыми знаниями, но также имеют возможность рисовать информацию в реальном времени из внешних источников. Это преимущество гарантирует, что оно всегда в курсе. Это завершает первую статью в нашей серии. В следующей статье мы углубимся в более технические аспекты. Для друзей, которые хотят получить доступ или изучить практику этой работы, они могут найти ссылки на соответствующие репо, которые я создал с помощью Python и связанных библиотек в моей учетной записи Github в конце статьи.
Надеюсь увидеть вас в следующей статье серии.
МЕТИН ЮРДУСЕВЕН.
Дальнейшее чтение
«Мы также хотели бы поблагодарить основополагающий вклад тряпичной бумаги Facebook AI 2020 года, который значительно сообщил об перспективе этой статьи».
Metinyurdev Github
Multi-Model Rag Chatbot Project
PDF PDF Rag Chatbot Project
Оригинал