

Парнинг данных Python: Pandas и Polars, сравнение
1 августа 2025 г.Введение
В недавнем проекте мне пришлось сравнить несколько наборов извне хранимых данных. Используя Python более пяти лет, я инстинктивно обратился к Pandas для своих потребностей в споре.
Панды
Pandas - это библиотека Python, используемая для анализа данных и манипуляций на маркированных наборах данных. Основная миссия команды по разработке Pandas заключается в том, чтобы «... быть фундаментальным высокоуровневым строительным блоком для выполнения практического анализа данных реального мира в Python. Кроме того, у него есть более широкая цель-стать самым мощным и гибким инструментом анализа данных/манипуляций с открытым исходным кодом, доступным на любом языке». Он предоставляет инструменты и методы для выравнивания, слияния, преобразования, а также загрузки и написания данных из различных постоянных хранилищ, таких как базы данных Excel, CSV и SQL. Он существует с 2008 года и в настоящее время рассматривается как окончательный инструмент для анализа данных в Python, с широким использованием от продаж до биоинформатики.
Поляр
По мере того, как наборы данных стали больше, с некоторыми таблицами превышали 5 миллионов строк, я заметил более длительное время ожидания определенных функций. Именно тогда я начал исследовать способы оптимизировать свой код и обнаружить поляры. Поляры, которые являются относительно новыми, возникли в 2020 году. Он работает аналогично пандам и предлагает инструменты и методы для выравнивания, объединения, преобразования и загрузки, а также для написания данных из различных форматов, включая Excel, CSV, SQL и формат Apache Arrow Arrow. Некоторые из основных целей команды по разработке Polars:
- Использует все доступные ядра на вашей машине.
- Оптимизируют запросы, чтобы уменьшить ненужные распределения работы/памяти.
- Обрабатывает наборы данных намного больше, чем ваша доступная оперативная память.
- Последовательный и предсказуемый API.
- Придерживается строгой схемы (до запуска запроса должны быть известны типы данных).
Методология тестирования
Первоначально ничто не выделяется значительно. Обе библиотеки обрабатывают табличные данные и поиск поддержки, агрегации и другие вычисления на наборах данных. Они также используют серию (маркированная структура данных, похожая на массив) и DataFrames (коллекция серий) в качестве основных элементов. Вы также можете создавать пользовательские функции Python для генерации новых данных из существующих данных. Однако после рефакторирования некоторых основных задач от Pandas до поляр и использования команды %% Timeit Magic я смог объективно заметить значительные улучшения производительности, что явно согласуется с основной философией.
Набор тестирования состоит из следующих полей:
uuid: строка
ip_address: строка
Дата: строка
Страна: строка
200: целое число
400: целое число
500: целое число
И был сгенерирован с использованием следующего кода:
import random
import uuid
from faker import Faker
large_data_set = {'uuid': [str(uuid.uuid4()) for _ in range(0,6000000)],\
'ip_address': [f"{random.randint(1,254)}.{random.randint(1,254)}.{random.randint(1,254)}.{random.randint(1,254)}" for _ in range(0,6000000)],\
'date': [f"{random.randint(1990,2026)}-{random.randint(1,13):02}-{random.randint(1,29):02}" for _ in range(0,6000000)],\
'country':[f"{Faker().country()}" for _ in range(0,6000000)],\
'200': [random.randint(1,300) for _ in range(0,6000000)],\
'400': [random.randint(1,300) for _ in range(0,6000000)],\
'500': [random.randint(1,300) for _ in range(0,6000000)]\
}
Мое тестирование включало в себя создание случайного набора данных из шести миллионов строк для тестирования четырех основных операций:
- Фильтрация
- Арифметические операции (например, добавление столбцов вместе)
- Манипуляция по струнам
- и преобразование с использованием пользовательской функции Python
Основное использование
Установка
Оба могут быть установлены удобно с помощью PIP
Панды:
pip install pandas
Поляры:
pip install polars
Загрузка набора данных
Как панды, так и поляры поддерживают чтение CSVS, и заявления импорта идентичны.
Панды:
import pandas as pd
large_df = pd.read_csv('large_dataset_20250728.csv')
Поляры:
import polars as pl
large_df = pl.read_csv('large_dataset_20250728.csv')
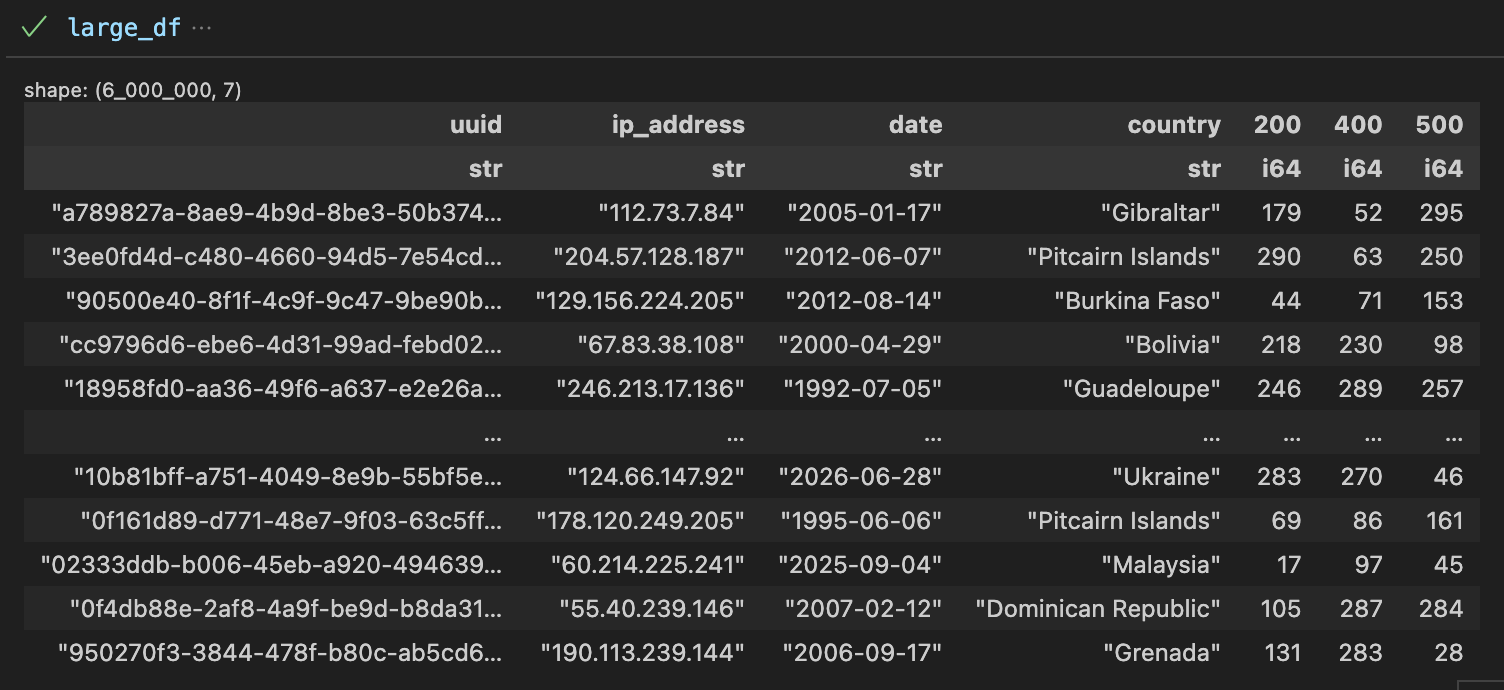
Оба представляют свои соответствующие данные о данных в табличном формате; Тем не менее, Pandas также включает в себя индексную серию.
Панды:
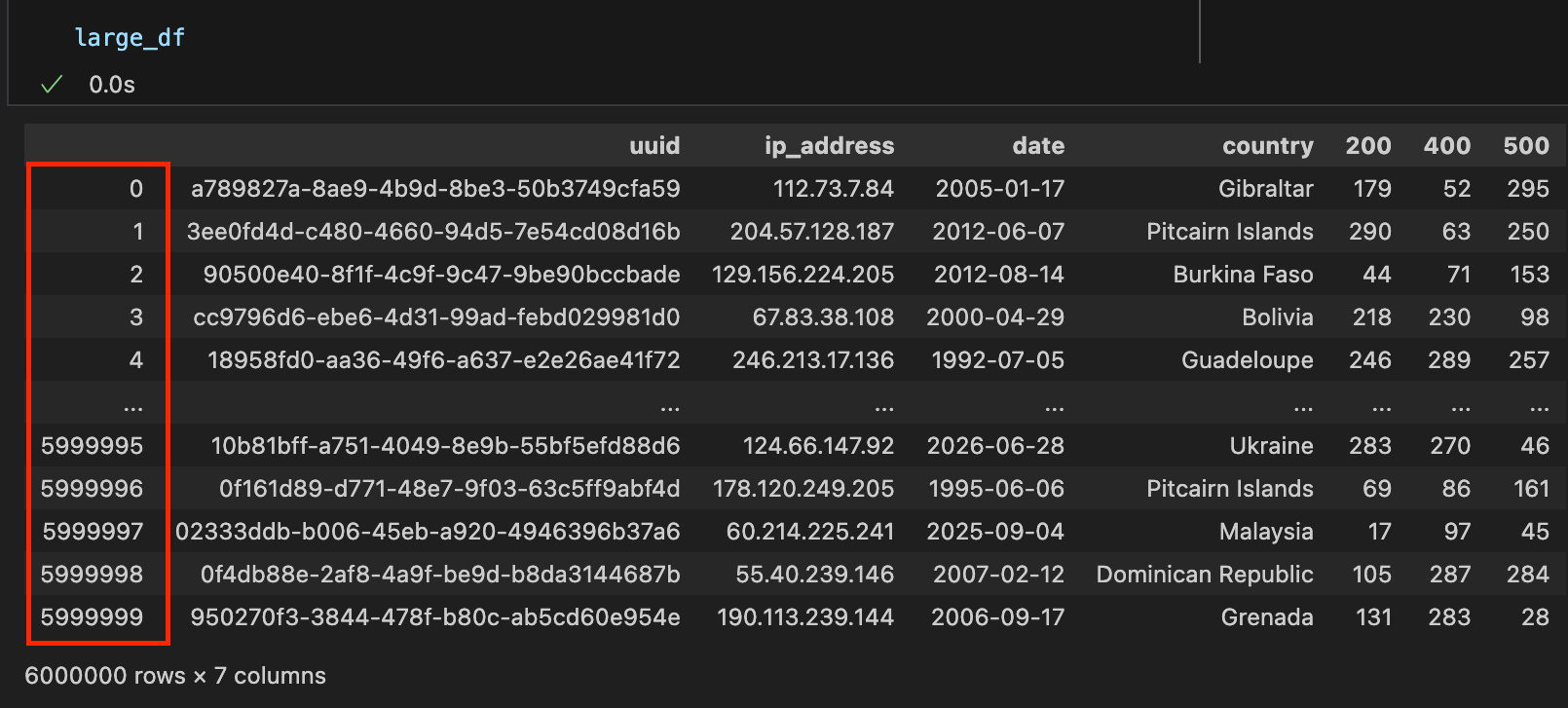
Поляры:
Фильтрация
Синтаксис фильтрации немного отличается. Синтаксис фильтрации Pandas несколько более компактен, где Polars представляет явный метод «фильтра». В этом примере я фильтрую на основе страны, "Гуам" и даты "2023-07-11". Из результатов вы можете видеть, как поляры явно быстро!
Панды:

Поляры:

Добавление
В дополнение к фильтрации, мне иногда нужно выполнить некоторую легкую арифметику в рамках колонн. В этом примере я суммирую три столбца, «200», «400» и «500», а затем храню результат в новой колонке «Общий». С полярами это значительно быстрее.
Панды:

Поляры:

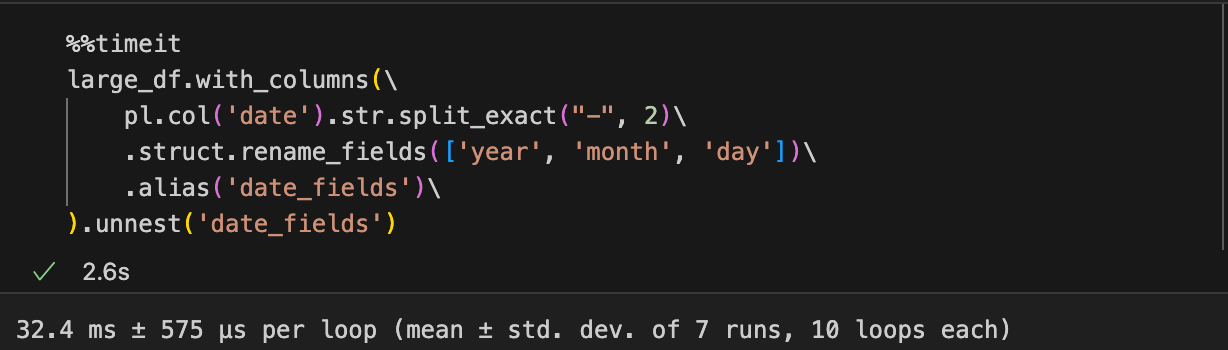
Строковые операции
Как панды, так и поляры предлагают методы для выполнения различных операций по типам строковых данных. С пандами синтаксис прост и более Pythonic. Однако синтаксис для аналогичной операции в Polars кажется более сложным, но он обеспечивает значительный повышение производительности. В этом примере я разделяю колонку «дата», которая содержит строки, которые выглядят как «yyyy-mm-dd», на отдельный «год», «Месяц» и «День».
Панды:

Поляры:
Операции по элементам
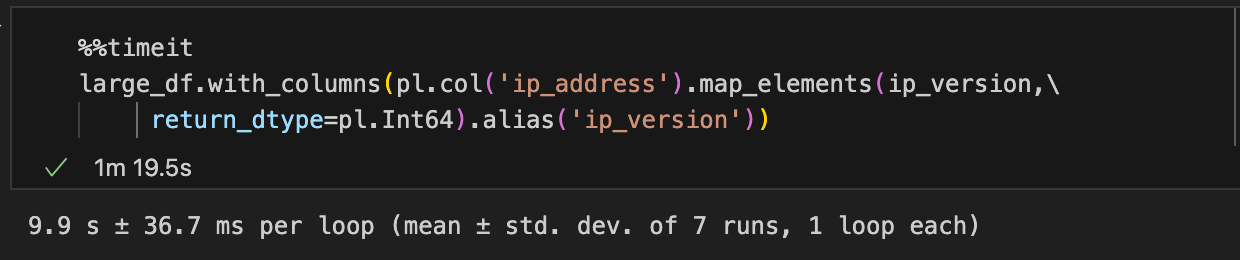
Вот где все начинает становиться немного интереснее! В то время как функции, установленные в пандах и полярах, являются довольно мощными, бывают случаи, когда вам может потребоваться написать пользовательскую функцию для итерации по всем элементам в серии для создания новых данных для последующего использования. В этом примере я использую библиотеку Python iPaddress, чтобы определить IP -версию столбца IP_ADDRESS, возвращая значение в качестве целого числа и создавая новый столбец с результатом.
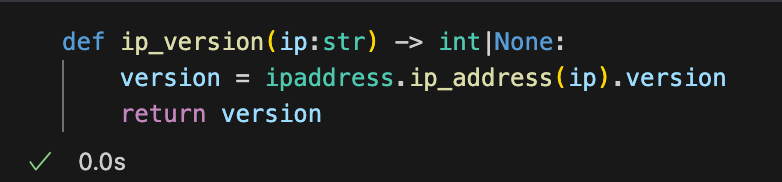
Опять же, синтаксис Pandas, по -видимому, намного проще по сравнению с полярами. Однако, по-видимому, нет никакого значительного повышения производительности в использовании поляр для преобразования для каждого элемента. Это связано с тем, что функция IP_Version не является внутренним методом поляров и, следовательно, подлежит глобальной блокировке интерпретатора (GIL). Python не является назначенным оптимизирует производительность так, как это делает Polars, и нет никакого преимущества в использовании поляров для таких операций.
Панды:

Поляры:
Заключение
Резюме результатов
| Время за считанные секунды | Панды | Поляр | Разница | % Улучшение |
| Запрос | 0,43 | 0,00249 | 0,42751 | 99,42% |
| Добавление | 0,0157 | 0,00254 | 0,01316 | 83,82% |
| Строковые операции | 3.21 | 0,0324 | 3.1776 | 98,99% |
| Пользовательские функции на элементах | 10.5 | 9.9 | 0,6 | 5,71% |
Некоторые ключевые моменты
- Polars предлагает значительный прирост производительности для собственных серий и операций DataFrame.
- Операции, которые не являются местными методами поляров, не наследуют повышение производительности в какой -либо степени.
- Синтаксис немного сложнее, чем панда.
Помимо всего этого, Pandas - более зрелая библиотека, которая хорошо играет с другими инструментами анализа данных.
Основываясь на моем опыте работы с обоими инструментами, я бы порекомендовал
Используйте поляры, когда:
Расчеты и операции DataFrame могут быть выполнены с использованием нативного инструмента Polars.
Скорость операций необходима, и набор данных может вписаться в память.
Используйте панды, когда:
DataFrame
Тем не менее, Polars предлагает метод для экспорта DataFrame Polars в DataFrame Pandas, чтобы компенсировать это ограничение, с дополнительной библиотекой Pyarrow. Это позволяет вам работать с Polars DataFrames, где есть прирост производительности, и возможность экспортировать его в DataFrame Pandas для других утилит и библиотек, которые ожидают его в рамках проекта.
import polars as pl
import pandas as pd
large_polars_df = pl.read_csv('large_dataset_20250728.csv')
large_pandas_df = large_polars_df.to_pandas()
В конечном итоге это будет зависеть от вашего конкретного варианта использования, чтобы определить, стоит ли рефакторировать существующие проекты по использованию поляров или интеграции в будущие проекты.
Оригинал