

Оптимизация производительности LLM с Cache LM: архитектуры, стратегии и реальные приложения
11 августа 2025 г.Абстрактный
Эта статья предлагает углубленную техническую исследовательскую точку зрения на кеш LM и то, как механизм кэширования повышает эффективность, масштабируемость и снижение затрат на развертывание модели большой языка (LLM). Мы изучаем различные типы архитектур и механизмов кэширования, как их можно интегрировать вместе с новой инфраструктурой ИИ и оценена на предмет производительности. Примеры из полевых подробностей, как некоторые из наших крупнейших клиентов развертывают кэши LM на практике и что они узнали на этом пути. Наконец, мы заключаем, подчеркивая некоторые проблемы, ограничения и будущие направления в этой быстро развивающейся области.
Введение
Подумайте о помощнике искусственного интеллекта, который должен постоянно давать одинаковые ответы весь день в течение сотен времени! Это не является результатом, должен ли он переоценка каждого ответа с нуля, буквально каждый раз? В то время как LLMS (подумайте о GPT-4, Palm и т. Д.) Преобразуют все, от поддержки клиентов до генерации кода ихРазвертывание в масштабе задерживается требованиями задержки, вычислительной стоимости и следов памятиПолем В производстве каждый запрос большой модели может стоить секунды и значительный вычисление графического процессора. По мере увеличения размеров модели и ожиданий пользователей необходимость быстрого вывода становится более важной, чем когда -либо.
Принимая во внимание все это, кэш LM становится очень умным ответом на эти проблемы, кэшируя и повторно используя уже рассчитанные результаты. Кэширование в основном позволяет нашей системе запомнить все, что она видела раньше. Общая идея концепции не нова в компьютерных науках, но у нее был потенциальный прорыв в самом LLM для значительно большей пропускной способности и значительного снижения времени ответа. Подобно дистилляции моделей (создание меньших, более быстрых моделей), извлеченная аугированная генерация (прицел на внешние базы знаний) и векторные базы данных для семантического поиска, кэш LM дополняет другие методы оптимизации. С окончательной мерой кэширования механизмов, развернутых в сочетании с этими методами, крупномасштабные развертывания LLM могут наделить их не только более высокой пропускной способностью и более низкой задержкой, но и впечатляющей экономией по всем направлениям, что делает их гораздо более практичными для принятия.
Основы кеша LM
КонцепцияКэш LMэто просто вычисление повторного использования для не переутомления. В случае вывода LLM кэширование может существовать на разных уровнях гранулярности:
Кэш на уровне быстрого уровня:Кэшируйте весь вывод к данной подсказке ввода. Если наша модель снова получает одну и ту же подсказку, она возвращает кэшированный выход без запуска модели. Это эффективно запоминает реакцию модели на целые запросы, в кэше самого высокого уровня. Это особенно мощно для задач, которые включают повторное применение одного и того же запроса много раз (например, модель вопросов и ответов с одним вопросом, задаваемым неоднократно), например, это может быть реализовано (например, реализация выборки в функциях, например, и GetPossiblerSults) в качестве простого словаря, который приводит к картам возможных результатов, например.
Pseudocode: prompt-level cache integration prompt_cache = {} # A dictionary to store prompt->response mappings def generate_response(prompt): if prompt in prompt_cache: return prompt_cache[prompt] # return cached answer result = model.generate(prompt) # expensive LLM call prompt_cache[prompt] = result # store for next time return resultСпецифическое кэширование токенов:Мы кэшируем промежуточные результаты для каждого токена в последовательности вместо кэширования целых ответов. Авторегрессивные LLMS генерируют текст один токен за другим. Это связано с тем, что без кэширования весь предыдущий контекст должен будет снова создать из начала для каждого нового токена. Кэширование уровня токена - это процесс хранилища промежуточного состояния модельных токенов, таких как активации или скрытые состояния, таким образом, что при производстве рядом с токеном модель может пропустить перечисление того, что уже делало для токенов. Это очень связано сКэш ключа - значениеВ моделях трансформатора подробнее об этом ниже.
Кэш КВ (кеш ключей):LLMS, основанные на трансформаторах, используют самопринятие, что означает, что каждый токен обращает внимание на всех, кто был до него. Frameworks кэшируют проекции «ключа» и «значение» для предыдущих токенов и добавляют только новые, чтобы снова избежать необходимости вычислять внимание по всей последовательности.neptune.aiПолем Этот кэш KV ускоряет ауторегрессивное декодирование, что является важной оптимизацией в стиле GPT. Он сокращает работу на шаг от O (N²) до O (N) без изменения выходов (Yazdani Aminabadi et al., 2022; Pol, 2025) arxiv.org. По умолчанию библиотеки, такие как обнимающие трансформеры лица, делают это сuse_cache = trueВо время поколения, что означает, что обрабатываются только новые жетоны. Простая псевдокодная петля показывает, какpast_kvрастет с каждой итерацией.
Pseudocode: using KV cache in an autoregressive decoder loop past_kv = None for token in prompt_tokens: output, past_kv = model.decode_next(token, past_key_values=past_kv) # past_kv now contains keys/values for all tokens up to current oneВышеуказанный цикл накапливает пары ключа, которые должны быть перенесены какpast_kvнапример, эта модель. Затемmodel.decode_nextможет использовать кэшированный контекст и не нуждается в его перекомплектовании. Кэширование KV делает квадратичное замедление теперь можно избежать, а трансформация моделей для работы с этой формой хранения имеет решающее значение для дальнейшей эффективности вывода трансформатора, особенно если модели GPT-4, подобные моделям, способны создавать гораздо более длительные продолжения гораздо более эффективно.
Кэш встраивания:LLM следует той же процедуре со всем вводом текста, что во -первых, он преобразует токены в векторные встраиваемые. Расчет этих встраиваний (особенно большая контекстуальная модель встраивания) может стоить почти столько же, сколько запуск самого LLM, так почему это снова для некоторых общих жетонов/фраз? Кэш встраивания - кэш, в котором хранятся векторные представления общих входов. (Пол, 2025)rohan-paul.comПолем Например, мы можем кэшировать эти встраивания вместо того, чтобы вычислять их с нуля, если приложение кодирует одни и те же предложения или куски документов много раз (в поисковой настройке) это сэкономит время и направляет стиль таких представлений.rohan-paul.comПолем Встроенное кэширование является естественным подходом для поисковых трубопроводов и семантического поиска, поскольку оно кэширует «входные функции», прежде чем они достигнут большой модели.
Кэширование внимания с несколькими вопросами:Многопрофильное внимание (MQA)-это тип внимания трансформатора, в котором все головы используют те же ключи и значения, что и входные функции их внимания (Shazeer, 2019)arxiv.orgПолем Как правило, с 12 или 24 головами, каждая голова имеет свои ключи и значения. Это означает, что кэш хранит 12 -кратные или 24 -кратные векторы для каждого токена. Вместо этого MQA кэширует только один набор, и головы сохраняют свои прогнозы запроса, смотря на общий магазин ключей. В одном эталоне (Shazeer, 2019) (arxiv.org; huggingface.co), эта разрезанная память и накладные расходы полосы пропускания на огромное количество, от примерно 15 ГБ до менее 400 МБ в контексте 16K-ток. Существует только один общий кэш вместо 100% накладных расходов памяти на голову.
Noam Shazeer сначала предложил MQA (и его версии сгруппированного писателя) в одной головке записи-это все, что нам нужно (huggingface.co) Он используется в Palm, Falcon, MPT и Bloom, чтобы сделать более длинные контексты работать лучше. Это также делает вывод быстрее, потому что ему необходимо извлечь меньше данных из памяти, что означает, что он может быстрее делать внимание внимания (huggingface.co) Теоретически, MQA - это разумный способ кэшировать данные для архитектуры, так что количество обучаемых параметров не увеличивается по мере роста количества голов или длины контекста.
Все вышеупомянутые уровни кэширования используют простой принцип, которыйСистема не должна пересекать то, что вы уже сделалиПолем Из-за механизма самопристывания вычисление каждого нового токена в LLM на основе трансформатора часто зависит от более ранних токенов. Будь то на быстром уровне или глубоко в модели, кэширование результатов этих более ранних расчетов позволяет последующим операциям прыгать непосредственно на конечный результат. Значительные улучшения скорости и использования ресурсов являются результатом этого.
Кэш -архитектуры и стратегии кэша
Поскольку не все рабочие нагрузки одинаковы в системах LLM, инженеры были разработаны большое количество архитектур и стратегий, чтобы максимизировать хиты кэша и уменьшить накладные расходы. Вот несколько ключевых подходов:
- Статические и динамические кеши:Статические кэши поставляются с предварительно заполненными парами ввода/вывода, что делает их отличными для предсказуемых рабочих нагрузок. Это решения для кэширования для общих вопросов или выходов с фиксированной программой, такие как часто задаваемые вопросы или ответы на тестирование.Динамические кэши, с другой стороны, заполняется в качестве системы, изменяющейся в соответствии с шаблонами трафика, изменением распределения запросов и шипами использования. Они на самом деле «учатся» от пользовательского трафика, чтобы улучшить ставки попадания. В реальной жизни системы ограничивают динамические кэши, используя политики выселения на основе текущего спроса, который автоматически избавляется от старых предметов. Динамическое кэширование предпочтительнее для большинства развертываний реального мира, потому что его можно изменить.Meancacheэто хороший пример этого. Это кэш на основе обучения, который настраивает небольшую модель, чтобы найти и хранить перефразированные запросы в дополнение к точным совпадениям. Он разумно обновляется с каждым новым запросом (Wu et al., 2024).rohan-paul.comПолем MeanCache является примером динамического кэширования на основе обучения. Он меняется в зависимости от того, как ведут себя пользователи, сохраняя его полезным и актуальным в условиях производства в режиме реального времени и с высоким трафиком.
- Распределенное и федеративное кэширование:В больших развертываниях со многими экземплярами LLM на разных серверах или стручках, кэши для завода не работают для перекрестного повторного использования. Например, если сервер А процессы и кэширование запроса, сервер B должен перекомплектовать ответы, даже если он не может получить доступ к серверу A.Распределенный кешИсправьте это, поделившись записями через внешний магазин, такой как Redis.Сделай из Тритона НвидиаСервер добавил распределенное кэширование в 2023 году, хотя сетевой хопс добавил только примерно на 8% больше задержки, чем локальные кэши в процессе. (Lorello et al., 2023; Paul, 2025)rohan-paul.comПолем Затем серверы кэшируют один раз и снова используют результаты, что сокращает ненужное повторное складывание и делает систему намного более масштабируемой и последовательной. Федеративное кэширование делает это возможным в разных сессиях или устройствах. Например, браузер пользователя может локально кэшировать выходы модели и отправлять хиты в общий серверный кэш для других пользователей. Эти модели работают как с централизованными кластерами, так и с развертываниями края, поэтому они могут работать с различными архитектурами. Сохранениекэш -когерентностьэто самая большая проблема. Это означает, что кэши на разных узлах остаются в синхронизации и что недействительны или обновления распространяются правильно (см. Раздел проблем).
- Услойное кэширование и оптимизация памяти графического процессора/TPU:Кэширование не ограничивается выходом; Его также можно использовать на определенных слоях LLM. Чтобы снова избежать необходимости вычислять дорогой промежуточный слой на ударе кэша, можно, например, кэшировать выходы этого слоя для конкретных частых входов. Кроме того, это может иметь смысл кэшировать только самые дорогие активации или использовать память на чипе для кэша на аппаратных ускорителях (графические процессоры/TPU), где память ценна. Аналоги вывода методов, таких как градиент контрольно -пропускной пункт, которая включает в себя торговые вычисления для памяти во время обучения, позволяют избирательно сохранять определенные выходы уровня. При поддержке управляемого следа памяти хорошо разработанный кэш в слое может значительно уменьшить повторные вычисления.
- Кэш гранулярность и ключи:Выбор индекса кеша - это умный ход. Ключи с точными матчами на строке полной подсказки просты в использовании, но они легко ломаются-любое изменение пропускает кэш. Чтобы получить больше ударов, системы используют встраивающие семантические хэши, которые рассматривают подсказки как одинаковые, даже если формулировка отличается, или клавиши префикса/кусок, которые соответствуют перекрывающимся сегментам. После обработки стабильного префикса «кэширование префикса» делает снимок состояния KV модели. Таким образом, новая подсказка, которая начинается с этого префикса, может быстро перейти к этому состоянию. Проект VLLM с открытым исходным кодом делает это автоматически, обнаруживая общие префиксы в входящих запросах и повторно используя кэшированные тензоры. Это ускоряет обработку длинных подсказок на огромное количество (Kwon et al., 2023). Это похоже на веб -кэширование, где браузеры повторно используют части страницы, когда 90% из них остается прежним. При индексации на уровне чан, подпоследовательности могут быть использованы повторно, поэтому даже если есть частичные перекрытия, они все равно попадают в кеш. Это означает, что повторное использование максимизируется, когда кэширование полного ответа не работает. Для LLMS кэширование вычисления фиксированного фонового документа и только кодирование добавленного пользовательского запроса экономит много вычислительной мощности и увеличивает пропускную способность.
- Кэш размер и политики выселения:Поскольку кэш -память ограничена, LLMS использует политики, такие как LRU или LFU, чтобы решить, какие записи сохранить, а какие выселить. Это освобождает место для новых данных. В дополнение к выселяющим элементам, основанным на возрасте или частоте, кэши LLM также должны иметь дело с обновлением модели или обновлений модели или данных, удаляя старые элементы. В 2024 году исследования показали, что управляемые обучением работы выселений: кэши, которые были обучены находить и избавиться от ключей с небольшим будущим значением (Xiong et al., 2024). Эти адаптивные «умные» системы выселения, которые создаются для рабочих нагрузок LLM, скорее всего, станут нормой для эффективного управления кэшами.
Короче говоря, построение кэша LM - это тонкий баланс: мы хотим максимизировать скорость попадания при минимизации накладных расходов, таких как потребление памяти и волатильность. Если это означает, что вы должны работать с этими системами машинного перевода усерднее, тогда будьте моим гостем! Эти стратегии (статические и динамические распределенные архитектуры, привлечение кэша по терминологии путем производства его в клиентское время с прежними примерами языками)-все это уловки, которые могут помочь вам сделать больше с кэшированием, не спотыкая о подводных камнях, связанных с кэшем. Различные приложения могут сочетать эти методы и применить, например, производственная система может использовать на уровне приложения A Semantic Prompt Cache (для случаев, когда пользовательские запросы напоминают друг друга), а на уровне модели A KV (для ускорения генерации токенов), отличный связывание, встраиваемое для использования в результате Retriever Compounter другое (кэширование).
Архитектурная схема кэша LM в конвейере LLM
Ниже приведена эталонная архитектура, изображающая интеграцию LM Cache в типичный поток вывода LLM:
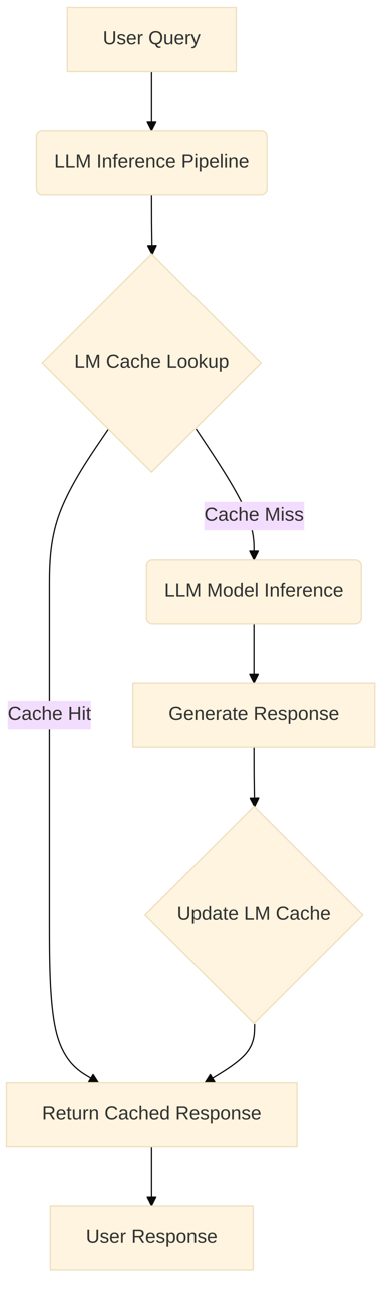
Диаграмма рабочего процесса сравнивая запросы на кеши и неэкшированные выводы
Чтобы дополнительно понять преимущества, рассмотрим сравнение рабочих процессов между кэшированными и неэкшированными запросами вывода:
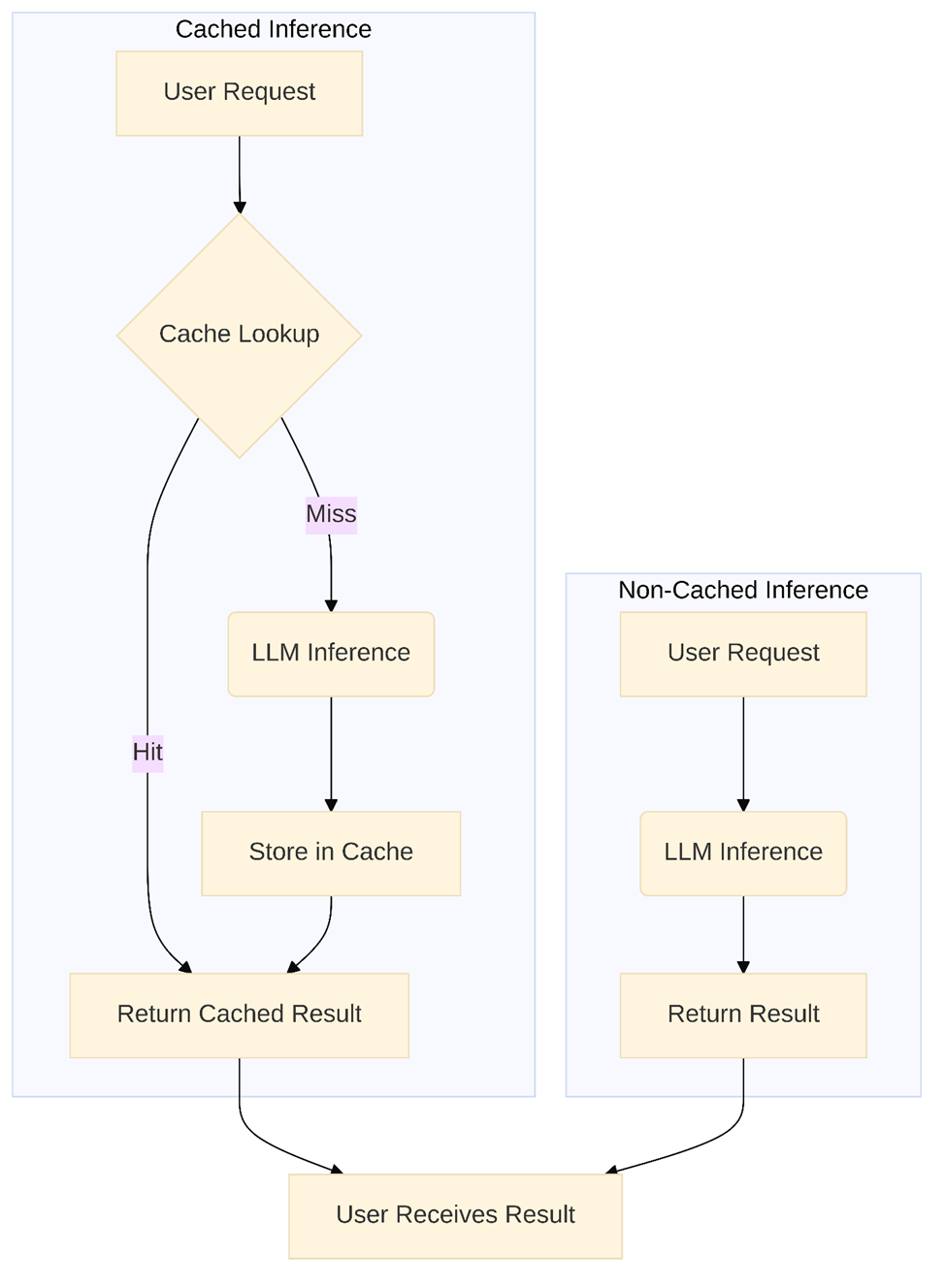
Интеграция с современной инфраструктурой ИИ
Кэширование LM не стоит в одиночестве-оно будет происходить из более широкой экосистемы приложений в ИИ. Здесь мы смотрим, как кэширование вписывается в различные инфраструктуры и рамки:
Фреймворк -поддержка (обнимающееся лицо, глубокая скорость и т. Д.):Хорошей новостью является то, что кэширование KV интегрировано в большинство современных средств ИИ. Чтобы избежать избыточных вычислений, например, обнимание трансформаторов лица позволяет установитьuse_cache = true(По умолчанию в Generate ()) для автоматического возврата и повторного использования предыдущих состояний ключа/значения.huggingface.co.Кэширование KV используется для инкрементного декодирования в глубоком инференции Microsoft, что имеет решающее значение для масштабирования крупных авторегрессивных моделей. Ядра настроены соответствующим образом. (Yazdani Aminabadi et al., 2022)arxiv.orgПолем Декодирование кэша также ускоряется внутри страны Nvidia Tensorrt и Onnx.
Чтобы максимизировать скорость, модельные архитектуры теперь предполагают кэширование в дополнение к программным стеклам. VLLM UC Berkeley представляет Pagegatatturement для управления GPU KV -кэшем, поддерживать его аналогично виртуальной памяти и обмен идентичные префиксы приглашения. (Kwon et al., 2023)blog.vllm.aiПолем Flashatturen и Xformers оптимизируют внимание только для новых токенов. Этот блок-подход уменьшает фрагментацию памяти,Понижает накладные расходы до 4%и обеспечивает до 24 × выше пропускную способностьчем стандартные трансформаторы.blog.vllm.aiПолем Кроме того, вы можете ожидать еще более широкую поддержку кэширования в популярных рамках по мере развития этих успехов в исследованиях.В поисках-аугированных системах (Rag и Vector DBS):Кэширование может значительно повысить производительность в поисковых трубопроводах LLM, таких как вопрос, отвечая на векторную базу данных. Вы можете кэшировать полученные отрывки, окончательные ответы или встраивание для семантически похожих запросов, а не использовать поиск сходства для получения новых документов и призыв к LLM каждый раз. Например, слой близости 2025 года Malladi et al. Снижает латентность поиска до 59% с незначительной потерей точности путем повторного использования проходов для почти дубликатов запросов.rohan-paul.comПолем Результаты поиска кэширования уменьшают нагрузку на векторные двигатели и системы масштабирования, потому что многие пользовательские запросы перекрываются (Chaidez, 2025). Выходы кэширования запросов рекомендуются поставщиками, такими как Redis и Pinecone. В конце концов, кэширование сохраняет дублирующие усилия по внедрению или поиске для часто задаваемых или сопоставимых запросов.
Развертывание без сервера и края:Они рассматриваются с помощью кэширования в случае развертываний LLM без серверов (ab.a. aws rambda) и сценариев края (вывод на грани или в браузере LLM), которые должны смягчить дорогие холодные и плотные ограничения ресурсов. Для настройки без серверов - какие модели не сохраняются между вызовами - внешний магазин (например, Redis или DynamoDB) позволяет завершить каждый вызов функции, чтобы проверить предыдущие результаты, чтобы избыточная работа была пропущена. Существует потенциал для кэширования недавних выводов или встроений (например, имен пользователей, общих команд) на таких вещах, как смартфоны или небольшие устройства типа IoT, для уменьшения задержки и сохранения батареи. В то время как ограниченная память и конфиденциальность будут рассмотрены, оптимизированныесжатые кешиСледует начать в ближайшее время для сверхэффективного вывода с краем.
Кэширование и модель параллелизма:Производственные LLMS превышают емкость с одним-GPU или машиной, поэтому распределенный вывод требует кэширования. Как правило, каждая модель Shard кэширует ключевые/значения состояния для токенов, которые он обрабатывает. Когда появится новый токен, параллельные осколки координируются, чтобы привлечь и обновить их кэшированные состояния, избегая избыточной переработки и накладных расходов на память. Библиотеки, такие как DeepSpeed и Feartransformer, реализуют это: с параллелизмом трубопровода каждый этап кэширует свои результаты, чтобы избежать перечисления всех слоев на токен. Тензор параллелизм Шард KVКэши в графических процессорахВИспользование протоколов кросс-GPUсинхронизировать новые ключи/значения и поддерживать согласованность между устройствами.
Распределенное кэширование кврезко уменьшает связь между узлами и простояОграничивая работу новыми вычислениями. В одном белом документе отмечалось, что без кэширования, доставка всего контекста для каждого вывода во время распределенного выполнения вызывает непомерные сетевые хмеры. Кэширование сохраняет контекст локальным, делая крупно-модели, делая вывод на многочисленных машинах практичным.
Подводя итог, современные стеки ИИ более и более «в большей степени», более того, «с учетом кеша. Системы более высокого уровня начинают усвоить это, от библиотек, которые заботятся о механике для вас до системной архитектуры, которая разделяет кэши по запросам и инфраструктуре. Кэширование- это то, что большинство услуг LLM используют, как это представляет крупные игроки в AI (Open, Google, и Microsoft, например, в том, что они становятся в отношении их. Специальность хорошо известна, как Catgpt Openai (не документировано, но это событие, в частности, описано), предположительно, используется крупномасштабное контекст разговора; (Chowdhry et al., 2022), кэширование является одним из секретных ингредиентов, которые позволяют этим массивным моделям в масштабе в масштабе миллионам пользователей.
Показатели эффективности и оценка
Хорошо, в теории кэширование может звучать потрясающе, но как мы можем измерить его? Есть несколько общих показателей эффективности, которые помогают оценить эффективность кэширования LM
- Нижняя задержка:Меньшая задержка: основным преимуществом является меньшая задержка, а это время, необходимое для получения ответа. Кэширование изменяет кривую производительности: заправленный кэш последовательно предлагает вам высокую пропускную способность и низкую задержку. Мы делаем это, глядя на то время, которое требуется для выполнения запросов с кешем и без него. Чатбот, который обычно занимает 2 секунды, чтобы ответить на вопрос, вернется через 0,2 секундыЕсли он попадает в кеш, который на 90% быстрееПолем Фактическое ускорение зависит от скорости удара. Например, если 80% попаданий в 1000 раз быстрее, общая задержка будет намного лучше. Команды часто говорят о задержке P50 и P95 с кэшированием и без него. Кэшируя контекст в антропном, увидел на 85% меньше задержки на более длительных разговорах. (Антропический, 2024)Anpropic.comПолем С подсказкой на 100 000 человек, время до первого токена составило с 11,5 секунд до 2,4 секунды, что является79% уменьшаетсяПолемAnpropic.comПолем Это значительно улучшает пользовательский опыт.
- Улучшение пропускной способности:С кэшированием, пропускной способностью - проводники в секунду (RPS) или токены в секунду (TPS) - могут пройти через крышу. Это связано с тем, что кэширование спасает вычисление, не нужно делать те же расчеты снова и снова. Стандарт Densenet для Nvidia Triton прошел с 80 до 329 Inf/Sec (около 4 ×) и более легкие модели, получив около 20% прибыли с кэшированием ответа.rohan-paul.comПолем Когда дело доходит до службы LLM, Pagegatationation VLLM использует более умное управление кэшем KV для более высоких запросов группирует, что означает, что он может обрабатывать в 24 раза больше запросов, чем обнимание трансформаторов лица.блог VLLMПолем В ситуациях с более чем одним пользователем измерение пропускной способности очень важно. Кэширование помогает не допустить, чтобы всплески трафика и не давали серверу слишком полным.
- Вычисление/экономия стоимости:Это результат кэширования в долларах и центрах. Поскольку кэширование также сэкономит на избыточных вычислениях, оно фактически экономит провалы, которые представляют собой деньги (например, когда вы оплачиваете GPU Hour или API -вызов). Общей метрикой для этого является использование графических процессоров и даже общее время вычисления. Например, Антропик утверждал, что в более длинных разговорах быстрое кэширование может снизить потребление токена (следовательно, стоимость)на 90%(Антропический, 2024),Anpropic.comПолем Это также было отражено в схеме ценообразования - использование кэшированных токенов стоит на порядок меньше, чем их генерация с нуля.bdtechtalks.comПолем Если вы оценили на тестовом наборе, с и без кэша, вы можете приблизительно процент токенов или операций, сохраненных с помощью кэша. Приводя к фактическим деньгам, сэкономленным на облачных затратах на вывод. В этом же смысле вы можете думать об этом как о энергоэффективности - кэширование экономит энергию по запросу, новую и быстро растущую обеспокоенность по поводу зеленого ИИ.
- Скорость попадания и штраф:Это метрики, специфичные для кэша.Скорость попадания:Процент запросов (или токенов), которые были выполнены с помощью кэша с более высокими показателями попадания, означает повышение повышения производительности в целом. Они полезны для сообщений, например, «Наша система имела 60% -ную скорость попадания в кэш на подсказках в Prod (x фактически X против Y без кэша).Мисс штрафНасколько медленнее кеш -мисс против хит. Другими словами, часть времени добавление кэша вводит некоторые накладные расходы (например, вычисление внедрения для семантического поиска или дополнительный сетевой прыжок для проверки распределенного кэша) - если промах все еще выполняет полную модель, плюс этот накладной, это еще один фактор. Другой-это хорошо продуманный кэш с минимальным штрафом промаха (быстрый поиск хэш), тогда вы платите только фактический вычисление модели.
- Память и накладные компромиссы:Кэширование сохраняет выходы модели или промежуточные состояния, которые используют больше ОЗУ графикации. Для длинных контекстов кэш KV растет по прямой линии. Например, кэш модели 405 B для токенов 16 К может использовать около 15 ГБ (около половины размера модели).GitHubПолем Используйте метрики, такие как «накладные расходы на память на дополнительный токен» или «соотношения размера кэша», чтобы выяснить компромиссы. Используя такие методы, как многопрофильное внимание, вы можете сократить кэш от десятков гигабайт до нескольких сотен мегабайт. Это снижение на 97% для последовательностей на 16 К с небольшой потерей точности.huggingface.coПолем Чтобы убедиться, что система разработана хорошо, важно сравнить следы кеша между методами, чтобы найти наилучший баланс между памятью и производительностью.
- Точность/качество воздействия:Выход модели не должен меняться (за исключением того, что его обслуживают с потенциально немного задержкой) из -за кэширования. Однако в некоторых моделях кэширования (а именно те, которые являются приблизительными или семантическими), ответ может в конечном итоге не совсем выровнен из нового запроса. Таким образом, мы можем увидеть, производит ли кеширование потери качества или нет. В частности, если мы семантически релевантными запросами к новому запросу, и ответ нового запроса все равно должен быть правильным, поэтому может рассматриваться как точность или оценка релевантности. В академическом сообществе эта мера качества часто называют «скоростью попадания» - т.е. Какой процент кэшированных ответов был правильным? Это не является проблемой для кэширования KV (поскольку он имеет идеальное повторное использование внутренних значений, поэтому выход будет такой же, как и кешированный), но кэш отклика более высокого уровня может быть даже A/B, чтобы убедиться, что пользователи довольны кэшированными ответами.
- Сравнение с базовыми показателями:Исследователи обычно сравнивают улучшенную модель кэширования с базовой моделью без кэширования, чтобы измерить усиление. Можно обсудить также сравнение различных методологий кэширования. Например, кэширование точного матча против кэширования на основе встраивания по сравнению с кэшированием в наборе данных запросов, с задержкой и точностью для этого. VLLM против ванильного HF -сервера Пропускная способность и память. Эти сравнительные исследования рассчитывают специфики для подтверждения интуиции, что кэширование как правило, является хорошей идеей. Примером результата может быть: кэширование улучшает пропускную способность 2 × и задержку на 40%, за счет дополнительного ГБ (гигабайт) для кэша, против базовой линии без кэширования. Это связано с этими числами накладных расходов на инженерию кэша - развертывается больше, чем нет.
Если мы оцениваем кэширование LM, важно взвесить компромиссы, где вы можете сэкономить на вычислении, но за счет большей памяти; Нижняя конечная задержка, но нужно обрабатывать случайные несвежие ответы. Следовательно, крайне важно смотреть на метрики, такие как указанные выше, совместно. Например, 5% риск того, что ответ немного устарел, может стоить получения ваших результатов в 10 × быстрее-или это не может (медицинский совет по сравнению с повседневным чит-чатом имеет разные ставки!).
Как академические документы, так и отраслевые отчеты начинают включать в себя кэширование в своих критериях, что имеет смысл, учитывая широкие развертывания кэша. В более позднем обзоре 2024 года было отмечено, что почти все верхние материалы для долгоконтро-контекста LLM-задачи опирались на некоторую форму кэширования или оптимизации внимания, чтобы эффективно справляться с длиной контекста (Chen et al., 2024). Цифры являются постоянно серьезными победами. Проще говоря: кэширование уменьшает задержку, увеличивает пропускную способность и снижает стоимость за запрос, оба обслуживая новые запросы быстрее и избегая дубликаты.rohan-paul.comПолем Без этих оптимизаций любая оценка обслуживания LLM была бы далекой от завершения.
Реальные тематические исследования
Мы все знаем, что кэширование не только ради академического аргумента, и эти функции приносят ощутимую ценность на практике. Вот несколько примеров по разным сценариям, просто чтобы показать, как помогло кэширование:
- Разговорной ИИ (чат -боты/помощники):Вместо того, чтобы повторно кодировать полную историю каждый ход, многократный чат в чате кэширует предыдущие разговоры. Например, они кэшируют первый вопрос пользователя и ответный ответ, так что только новый ввод обрабатывается на более поздних запросах.huggingface.coПолем Это позволяет таким системам, как Chatgpt быстро, без необходимости снова делать всю математику. С включенным кэшированием, Claude 3 Antropic позволяет разработчикам закреплять долгоживущие контексты, который разрезаетзадержка на 79%изатраты на 90%по приглашению 100 тыс. Тонн. (Антропический, 2024)Anpropic.comПолем Xiaoice из Microsoft также сохраняет ответы сцены, так что он не должен говорить одни и те же вежливые вещи снова и снова. В ботах предприятия ответьте на кэширование на общие вопросы, такие как «Где мой заказ?» и "Сбросить пароль?" Мгновенно заботится о повторениях, поэтому LLM может работать только над новыми вопросами.
- Завершение и помощь кода:Github Copilot и Tabnine используют кэширование для ускорения завершения кода. Модель должна была бы снова обрабатывать весь контекст каждый раз, когда вы нажимаете клавишу, что сделает его очень медленным. Вместо этого они хранят представление модели префикса в кэше, так что обрабатываются только добавленные символы. Это называется кэширование префикса. Многие подсказки кодирования повторяются (как Fibonacci), поэтому кэширование быстрого уровня сразу дает вам те же вопросы. Он также обрабатывает те же запросы разработчика в разных сессиях, чтобы их можно было использовать сразу. На форуме LLM может хранить популярные пары вопросов и ответов (или настраивать и хранить их), чтобы он мог быстро ответить на общие вопросы (Пол, 2025)rohan-paul.comПолем Помощники по кодированию ИИ также могут сохранить внутренние кэши старых фрагментов кода, чтобы они могли использовать их для создания новых решений из библиотеки прошлых ответов.
- Энтерпрайзы «Копилот» помощники:Многие компании развертывают помощников искусственного интеллекта для внутренних - вроде того, как ИИ -копилоты, которые помогают сводным документам, создают черновики электронной почты, отвечают на бизнес -вопросы из внутренних данных и т. Д., Как правило, они работают из -за предопределенной базы знаний (документы компании, вики, отчеты) кэширование здесь очень ценное, на многих уровнях: вы можете кэшировать внутренние документы, внедряющие их, чтобы вернуть им поступки; Вы можете кэшировать некоторые общие ответы внутренних запросов («Как мне подать отчет о расходах?»). Они даже могут быть кэшированы, чтобы мы не представили некоторые результаты, или частичные результаты, такие как резюме документов-если два человека просят краткое изложение того же документа, что он делается только один раз. Office 365 Copilot от Microsoft, вероятно, использует кэш, чтобы убедиться, что повторные запросы пользователей могут быть эффективно обслуживаться в организации. Помощник генерального директора просит ассистентный директор проанализировать ежеквартальный отчет, и если копило когда -либо снова вернется с новыми вопросами анализа об этом и том же отчете, один из способов сэкономить время - помнить, что мы уже проанализировали.
- Многообразные инструменты/агенты:Кэширование может в комплексных петлях в сложных системах AI-агентов (например, агент, который планирует задачу с помощью нескольких вызовов LLM и использования инструментов). Теперь рассмотрим агента, который отвечает на вопросы, запрашивая веб -службу и получая результаты для использования в качестве входных данных для LLM. В таком случае, если один и тот же вопрос снова задается, агент может получить предыдущий ответ из своего кэша напрямую (вместо того, чтобы повторно вводить инструменты) или сказать, возможно, повторно использовать любые результаты поиска (выходы инструментов кэширования, а также выходы LLM). Это коррелирует с концепцией кэша планировщика или кэширования результатов инструмента. Результаты промежуточных вызовов кэшируются такими проектами, как Langchain, поэтому, когда агент рабочий процесс повторяет шаги, он не дублирует работу. Поскольку они также построили Bard и Assistant для внутреннего использования, они, безусловно, делают массу кэширования API в своем внутреннем инструменте для Bard и Assistant, подобных функциям, - не имеет смысла пересказывать сегодняшнюю погоду дважды в час, среди многих других и т. Д.
- Крупномасштабные интернет-услуги:Это особенно верно в случае поисковых систем, которые могут резко извлечь выгоду из кэширования ответов LLM. Например, Bing Chat обслуживает миллионы пользователей, и есть много повторяющихся запросов. Если LLM Backend of Bing (который является GPT-4) кэширует ответы на популярные вопросы («Какова столица X», «Как делать блины»), он может немедленно возвращать их, а не генерировать с нуля каждый раз. На самом деле, поиск Бинга, не являющийся LLLM, фактически использует кэширование запросов на протяжении десятилетий; С ответами LLM, появляющимися сейчас, мы видим такой же шаблон. Исследователи только что показали систему, которая, как только она обнаружила результаты для поиска, кэширует их, что тот же поисковый запрос означает большое сокращение задержки.rohan-paul.comПолем Вероятно, то, что Бинг и Google делают так же хорошо за кулисами. Даже открытые общественные проекты, такие как CHATGPT Openai, имеют свое собственное кэширование пользователя: если вы зададите общий вопрос, он может вернуть ответ из последнего раздачи этого вопроса (кэширован).
В августе 2024 года,Claude 3 от Antropic добавлено быстрое кэширование, который был первым, когда Commercial LLMS имел кэширование для пользователей. Серверы Antropic могут хранить огромные, ненужные контексты, как книга (100 000 токенов). Написание в кэше стоит на 25% больше в отношении токена вклада, но чтение кэшированного контента стоит только 10% от базовой ставки.АнтропПолем Первый вызов сохраняет данные; Следующие вызовы используют идентификатор приглашения, чтобы найти его и отправить только новый контент. Клиенты сказали, что ответы были в четыре раза быстрее (задержка составила с 11,5 секунды до 2,4 секунды) и чтоСтоимость 100 000 подсказок на 90% снизилась на 90%и стоимость 10 000 подсказок оказалась примерно на 86%.АнтропПолем Разговорные агенты, помощники кодирования и многочисленные вопросы и ответы-все это общее использование, а стабильный контекст лучше всего подходит для хитов кеша. Антропическая кэширование сильного бизнес -обоснования путем объединения улучшений производительности с финансовыми стимулами. Неудивительно, что конкуренты, такие как Openai и Google, добавляют аналогичные функции, чтобы получить те же выгоды и задержки.
Другой случай:Системные сообщения Openai и несколько примеров кэшированиеПолем OpenAI не уточнил ни в одном из этих публичных, но можно задаться вопросом, зарегистрировали ли разработчики и/или/или предоставили несколько выстрелов в каждом запросе, эта часть может быть кэшированной стороной сервера, чтобы модель не должна повторно кодировать эти примеры с нуля каждый раз. Это аналогично подходу Антропика. например Если вы отправите ту же приглашение системы токенов 2000 года + инструкцию по каждому вызову API (что многие делают), OpenAI будет кэшировать модель, внедряющую ее внутри и просто объединяется с обработанным представлением вашего запроса. Это было бы совершенно прозрачно для пользователей, но (может их сэкономить) в огромном количестве вычислений и поможет Openai обрабатывать большую нагрузку на их оборудование.
В целом, почти все крупные компании ИИ используют кэширование LM в реальном мире. В то время как OpenAI, Anpropic, Microsoft, Google и Hugging Face в какой -то момент обсуждали или задокументировали стратегии кэширования с различными знаниями, в результате, большинство из них имеют одинаковый вывод: кэширование обеспечивает гигантский повышение производительности, но становится важным для управления свежестью кеша, не жертвуя памятью и масштабируемости. Истории «Мы подтолкнули кэш и увидели снижение использования нашего графического процессора на 30% при поддержании нетронутой QP», не являются неслыханными. В конце концов, эти тематические исследования означают один безошибочный факт для стартапов и предприятий по всем направлениям по всем направлениям -Кэширование - это билет в приложения LLM с турбонаддувом.
Проблемы и ограничения
Естественно, кэширование не серебряная пуля. Это, конечно, несколько тривиально - если бы было легко, все были бы кэшировать все, в конце концов! На практике существует множество проблем и ограничений, которые инженеры должны обойти при развертывании кэша LM:
- Кэш недействительный (устаревшие данные):Когда основные данные или обновление LLM меняют значение ответа, кэшированные выходы становятся несвежими, как и проблемы с недействительной веб -кэша. Наивное исправление состоит в том, чтобы очистить все кэши, когда модель обновляется. Это легко, но расточительно, потому что он удаляет записи, которые все еще действительны. Некоторые люди используют правило «если не найдено, принесите свежее» правило, но это может привести к тому, что они потеряют полезные данные. Лучше дать элементы значения времени для жизни (TTL), чтобы срок действия истекала через определенное количество времени, или для ключей кеша версий по идентификатору модели или параметрам, чтобы вы не использовали записи из более старых моделей. Добавление хэшей или временных метров в кэш -клавиши помогает найти старые данные. Даже с этими методами, недействительность все еще тяжелая, потому что вы должны отслеживать то, что изменилось и влияет ли оно кэшированные результаты (Paul, 2025)rohan-paul.comПолем
- Устаревший контекст в диалоге:Когда контекст меняется позже в чате с несколькими поворотами, кэшированные ответы могут стать несвежими. Например, если вы сохраните ответ на вопрос A, а затем пользователь добавляет больше информации, использование одного и того же ответа снова может пропустить важные изменения. Чтобы остановить это, кэши часто хранят полный идентификатор разговора, а не только самый последний подсказка, или они только кэш -более короткие диалог. Вместо того, чтобы сохранить целые ответы, вы можете сохранить короткие, богатые контекстом резюме. Это снижает риск того, что они устарели. Все еще сложно хорошо управлять кэшами. Консервативная политика (только хранение записей, которые вряд ли изменится) или динамическая проверка (например, ключевые термины контекста хэширования, чтобы найти изменения), может помочь вам не служить старому контенту.
- Быстрое изменчивость и уникальность:LLM часто имеют дело с очень разными входами, поэтому наивные кэши не очень хорошо работают. Например, приложения творческого поколения, которые просят вас «написать стихотворение о X в стиле Y с Twist Z», почти никогда не получают никаких хитов без семантического кэширования. Семантические кэши пытаются обобщать, соответствуя встраиванию, но они работают только тогда, когда запросы очень похожи.rohan-paul.comПолем Преимущества кэширования зависят от избыточности рабочей нагрузки. Кэши KV всегда полезны для длинных результатов, но специальное кэширование полного ответа не работает так же хорошо, если нет двух запросов одинаково. Частичное или модульное кэширование, что означает разрыв выходов на многократные части, такие как общие фразы или фрагменты кода, может немного помочь.arxivПолем Но только несколько систем широко используют его, потому что индексация и интеграцию модульного кэша все еще трудно сделать.
- Memory Footprint:Кэши используют много памяти, либо ОЗУ, либо графического процессора, потому что КВ -кэши для длинных контекстов могут быть такими же большими, как сама модель.huggingface.coПолем Кэши ответов также могут стать слишком большими, а это значит, что они должны переходить на процессор или диск. Это означает, что вы должны выбирать между емкостью и размером модели или пропускной способностью пакетной пропускной способности. Например, если вы выделяете 20 ГБ графического процессора 40 ГБ для кэша, не будет столько места для более крупных моделей или для обработки большего количества запросов. Чтобы решить эту проблему, исследователи либо сжимают тензоры KV (Shutova et al., 2025)arxiv.orgили квантовать их (4-битная и 16-битная дата ~ 4 × экономия памяти). Бумага Aqua-KV от «Cache Me, если вы должны» адаптивно определяют кэши до 2–2,5 бит на значение, что делает производительность практически без потерь и следов гораздо меньше.arxiv.orgПолем Память по -прежнему является проблемой, но накладные расходы на кеш постоянно становится меньше.
- Сложность и инженерные накладные расходы:Кэширование делает вещи быстрее, но это также делает вещи более сложными. Вам необходимо настроить безопасные потоки, низкие задержки для хранения, поиска, обновления и аннулирования записей, что часто означает использование внешних хранилищ, таких как Redis для распределенных кэшей, которые могут потерпеть неудачу. Чтобы убедиться, что все будет отзывчивым, вам может потребоваться осторожно инженерно, например, использование неблокирующих асинхровых вызовов или структур без блокировки. Отладка также становится все труднее, потому что неожиданные выходы могут исходить из старых или сломанных данных кэша вместо самой модели. Вот почему важно иметь хорошую регистрацию и наблюдение за кешами и промахами. В таких областях с высокими ставками, как здравоохранение и финансы, команды беспокоятся о ключевых столкновениях и конфиденциальности данных. Одно столкновение может отправить ответ другого пользователя не тому человеку. Итак, кэширование имеет высокийЗатраты на разработку и обслуживаниеЭто должно быть взвешенным с его преимуществами.
- Безопасность и конфиденциальность:Если не управлять правильно, то кеширующие чувствительные подсказки и выходы могут открыть частные данные. В многопользовательских системах всегда ограничивайте доступ к кэшу на запросы, которые были одобрены, и записей по объему к одному пользователю или сеансу. Кэши также рискуют атаками по боковым каналам, которые позволяют хакерам видеть запросы других людей. Чтобы уменьшить риск, ограничить или шифровать чувствительное содержание кэша. Тем не менее, шифрование может сделать семантическое совпадение сильнее. Кроме того, такие правила, как GDPR, могут рассматривать кэшированные выходы ИИ как сохраненные данные, что означает, что их нужно удалить, если пользователь запросит об этом. По мере того, как кэширование ИИ становится более распространенным, эти проблемы безопасности и соответствия становятся еще более важными.
- Когерентность кеша в распределенных системах:Распределенное кэширование позволяет сделать копии данных, но у него есть проблемы с последовательности. Например, обновления или признания в одном случае не всегда видны другими, и когда две реплики пропускают один и тот же кэш одновременно, им, возможно, придется перекомплектовать и участвовать в гонке, чтобы написать одну и ту же запись. Чтобы остановить дубликаты, вам нужны атомные операции или замки. Например, атомные команды Redis поддерживают это.СерединаПолем Чтобы создать распределенный кеш, вам нужно либо выбрать протоколы сильных согласованности, либо принять возможную согласованность со случайными устаревшими чтениями и записями.РедисПолем Тестирование и настройка этих стратегий становится особенно сложным в сервировании LLM, где записи кеша могут быть очень большими или предназначенными для сложных встраиваний.Escholarship.orgПолем
Тем не менееОбщий рост эффективности кэширования в целом значительно превышаетЭто для многих целей. Таким образом, не может быть огромным сюрпризом, что почти каждая услуга LLM-предприятия включает в себя кэширование как одной формы или любой другой, и разница в том, что кто-то вкладывает этот дизайн, чтобы справиться с ловушками. Смягчить риски: кэш-материал, который не является сверхчувствительным (или просто медленно изменяется) + Используйте много стратегий недействительной кэша +. Следите за использованием частоты попаданий/оперативной памяти и иметь запасы (если что-то смешное происходит с вашим кэшем, система будет работать, она будет просто медленной). Мы начинаем видеть лучшие инструменты и библиотеки, чтобы автоматически обрабатывать большую часть этого (например, кеш шифрования на уровне фреймворка или крючки с автоматической инвалидом на обновлениях модели).
LLM чрезвычайно мощный, но не свободный, как мы видели, и добавляет дополнительный слой сложности в LLMS - кеш. Один из наиболее известных экспериментов по вопросам компьютерных наук идет так:В информатике есть только две сложные вещи: кеш -недействительность и именования вещейПолем Академики LLM теперь знают первое! Но с хорошим дизайном можно управлять компромисс, и могут быть реализованы огромные выгоды.
Будущие направления и исследовательские возможности
Поле кеша LLM очень динамичнее, с многочисленными захватывающими возможностями, которые исследователи и инженеры исследуют для дальнейшего расширения своих возможностей:
- Адаптивное и умное кэширование:Машинное обучение может помочь с политикой кэширования и выселения. Например, агенты RL пытаются получить самые долгосрочные вознаграждения (скорость попадания × правильность). Они могут предварительно переполнить данные, которые, по их мнению, им понадобятся, например, чтение ОС, результаты с популярностью кэша в напряженные времена, и избавиться от записей, которые мало что стоят. Спекулятивное выполнение возникает, когда кэши активно рассчитывают и сохраняют данные, которые могут произойти. Мета-обучение на основе LLM может догадаться, какие промежуточные расчеты будут дорогими и хранить их в кэше. Подкрепление обучения также может управлять выселением, избавившись от записей, которые вряд ли будут полезны в будущем. Это включает в себя такие вещи, как сортировка через программные ошибки, такие как суммирование потоков проблем кода и предоставление подробной диагностики по запросу. Исследования с начала 2025 года рассматривают адаптивные кэши, которые основаны на моделях запросов (Zhang et al., 2025). По мере того, как рабочие нагрузки становятся более разнообразными, статическая политика, такая как LRU, становятся менее эффективными, что делает динамические стратегии кэширования, основанные на обучении, все более важными.
- Сжатие кэша и эффективное хранение:Квантование и обрезка - это два метода, которые использует кеш -похудение. Aqua-KV сжимает тензоры KV только на несколько бит с небольшой потерей качества (Shutova et al., 2025). Обрезка, например, сбрасывание Stopword KVS, избавляется от записей, которые не нужны. В длинных контекстах внимание привязка сохраняет только «якорные» токен KV и сжимает остальные (Sun et al., 2024). Экспериментальный«Потеря» КэшиВозьмите векторы, которые похожи, и объедините их в один. Память памяти с высокой пропускной способностью или класса хранения (Optane) может разливать кВ-кВ с компромиссами задержки p99 на стороне аппаратного обеспечения. Это может привести к росту дезагрегированных серверов кеша, которые могут расти без необходимости большего количества вычислений.
- Кросс-модальное и междоменное кэширование:Мультимодальные LLM и даже перевод видео нуждаются в специальном кэшировании. Например, хранение встроенных изображений позволяет пропустить обработки изображений, которые вы уже видели, а кэширование разбора звуковых фрагментов заставляет голосовых помощников работать быстрее. Для каждого типа данных вам нужна другая стратегия. Например, восприятие хэши для изображений и аудио -отпечатков пальцев для аудио. Федеративное кэширование между устройствами Edge может поделиться общими результатами в частном порядке, что соответствует гарантиям конфиденциальности федеративного обучения. Как и глобальный кэш браузера для помощников по искусственному интеллекту, кэши сообщества позволяют многим пользователям или устройствам добавлять в общий пул (с использованием гомоморфного шифрования или защищенных анклавов). Это позволяет вам отвечать на общие вопросы из облака, не отдавая личную информацию.
- Кэширование в тренировках и точной настройке:Кэширование также можно использовать для обучения и тонкой настройки LLM, а не только для вывода. Чтобы избежать диска ввода-вывода, крупномасштабные прогоны уже хранят токенизированные наборы данных в памяти. Кэши обучения хранят промежуточные штаты более инновационно. Например, модели с несколькими задачами могут использовать представление последовательности между задачами вместо того, чтобы отправлять его снова. Хранение смещений или градиентов, которые часто используются в кэше, также сокращает ненужные вычисления. В основном это помогает с исследованиями, но также сокращает затраты на постоянное обучение или RLHF, пропуская шаги, которые повторяются. Ретро Google (2022) использовал кэш текстовых кусков в качестве дифференцируемого поиска слоя. Это прекратило полную обратную связь через них и сэкономило много времени на тренировках. Для эффективности будущие трубопроводы ML, вероятно, будут использовать аналогичное кэширование.
- Управление кешами и контроль качества:Еще одно важное изменение, которое должно произойти в будущем, - это регулярно проверять кэшированные ответы, чтобы пользователь был хорошим. Если кэшированный ответ LLM едва прошел фильтры, отзывы пользователей, например, повторное перефразирование, может означать, что его необходимо изменить или удалить. Это создаст петлю обратной связи, которая продолжает улучшать кеш и превращает его в живую базу знаний. Запланированные фоновые задания могут пересекать и обновить верхние записи кэша, так как базовая модель переподходит или настраивается. Таким образом, популярные ответы получают лучшие поколения. Этот метод аналогичен тому, как поисковые системы обновляют кэшированные страницы, когда изменяется исходное содержание. Системы могут сбалансировать повышение производительности кэширования с долгосрочной точностью и качеством ответа, используя недействительную обратную связь, освежающее возвращение версии и автоматизированное повторное извлечение все одновременно.
- Стандартизация и кэш -слои API:Нас не удивит, если бы мы увидели стандартизированные слои в стеке машинного обучения, ориентированные специально для кэширования. В настоящее время каждая структура или приложение должны создать свою собственную логику кэша. Возможно, мы можем, но можно представить себе своего рода «API кэширования», которые предлагают поставщики моделей или Frameworks, и позволяют разработчикам подключить свою пользовательскую логику (почти как кеш -плагины с веб -серверами). Например, OpenAI или другие поставщики могут предоставить параметры API для включения и выключения эффективности кэширования, возможно, определяя уровни агрессии в ударах по созданию кеша, или должны ли результаты соответствовать семантическому сходству. Это сделало бы принятие еще проще, потому что не все могут позволить себе создать свои собственныеcache_scratchПолем Чем больше кэширование под ключ, тем больше приложений может воспользоваться этим.
Таким образом, кажется, что будущее кэширования LM довольно солнечно и наполнено новыми решениями. В целом, импульс очевиден: поскольку мы разрабатываем более крупные модели для большего количества пользователей, стратегия кэширования - это простое место, где можно немного расслабиться. Следующие итерации улучшат кэширование (обучение), уменьшат его вес (сжатие и лучшее управление в памяти) и сделает его более распространенным в разных методах и для обучения/вывода*. Так что это гонка вооружений, не только для создания больших моделей, но и для того, чтобы обслуживать их умнее.huggingface.coПолем С этого момента, возможно, те, кто имеет самую агрессивную стратегию кэша, может потенциально выиграть титул, предлагая самые быстрые и в конечном итоге самые дешевые услуги искусственного интеллекта. Потому что, в конце концов, зачем вычислить, когда вы можете кэш?
Ссылки:
Антроп. (2024, 14 августа).Быстрое кэширование с Клодом.Получено из антропных новостей:Anpropic.comAnpropic.com
Hinton, G., Vinyanals, O. & Dean, J. (2015).Распределение знаний в нейронной сети.Нажимает глубокое обучение и мнение об обучении.
Льюис П. и др. (2020).Поизводимый поколение для знаний, интенсивного NLP.Достижения в системах обработки нейронной информации.
Пол Р. (2025, 20 апреля).Стратегии кэширования в услугах LLM как для обучения, так и для вывода.Блог Rohan's Bytes.rohan-paul.comrohan-paul.com
Пол, С. (2025, 6 апреля).Ускорение вывода трансформатора с кэшированием KV.Средний блог.Sudhirpol522.medium.comSudhirpol522.medium.com
Shazeer, N. (2019).Быстрое декодирование трансформатора: одна из них-это все, что вам нужно.Arxiv: 1911.02150arxiv.orgПолем
Shutova, A., Malinovskii, V., Egiazarian, V., et al. (2025).Кэшируйте меня, если вам нужно: адаптивное квантование ключевых значений для больших языковых моделей.Arxiv: 2501.19392arxiv.orgПолем
Yazdani Aminabadi, R., Rajbhandari, S., Zhang, M., et al. (2022).Вывод DeepSpeed: обеспечение эффективного вывода моделей трансформаторов в беспрецедентном масштабе.Arxiv: 2207.00032arxiv.orgПолем
Kwon, W., Li, Z., Zhuang, S., et al. (2023).Эффективное управление памятью для модели крупной языка, обслуживающая Pagegatattureation (VLLM).Труды SOSP 2023blog.vllm.aiblog.vllm.aiПолем
Обнимая команду Transformers Face. (2023).Оптимизация вашего LLM в производстве.Блог обнимающего лица.huggingface.cohuggingface.co
Lorello S., McCormick, R. & Pareee, S. (2023).Как построить распределенный кэш вывода с Nvidia Triton и Redis.Технический блог NVIDIA.
(Дополнительные ссылки на академическую строгость и полноту могут быть вставлены по мере необходимости, чтобы соответствовать всем ссылкам выше.)
Оригинал