

Навигация по базе данных векторов
1 марта 2022 г.Встраивание векторов — одна из самых полезных концепций машинного обучения, особенно когда речь идет о таких областях, как системы рекомендаций или алгоритмы поиска.
Векторное вложение — это плотное числовое представление реальных понятий, таких как текст, изображения или аудио, в виде векторов в [векторном пространстве] (https://en.wikipedia.org/wiki/Vector_space). Легко понять, насколько близки векторы друг к другу, если оборудовать векторное пространство [метрикой] (https://en.wikipedia.org/wiki/Metric_(mathematics)). Это также позволяет легко группировать похожие точки вместе.
В модели машинного обучения, которая имеет дело с векторными вложениями, вам необходимо не только эффективно хранить векторы, но также искать и выполнять над ними математические операции. Однако наиболее часто используемые реляционные базы данных не подходят для работы с векторными вложениями из-за фундаментальной разницы между реляционными данными и векторными данными. Векторные базы сделаны специально для работы с векторными вложениями.
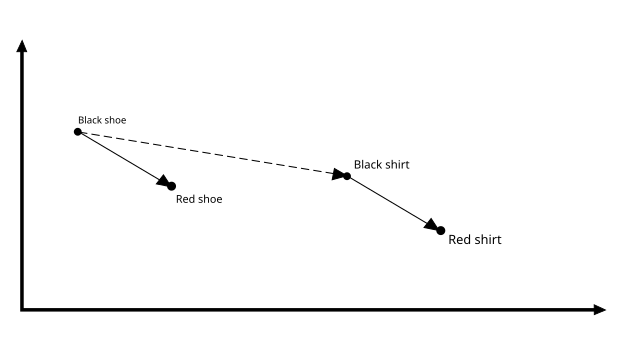
Представьте, что вы создаете систему рекомендаций для сайта электронной коммерции. В традиционной базе данных SQL вы можете хранить каждый товар и информацию о нем (например, цвет, модель, цену и т. д.). Если пользователь проявляет интерес к предмету, теперь вы можете искать предметы того же цвета или той же цены, что и этот предмет, и рекомендовать их пользователю. Однако похожий товар не обязательно может иметь такой же цвет или цену. Поскольку в базах данных SQL нет понятия подобия, ваш выбор может быть неточным.
Если вы представляете элементы в виде векторов, вы можете использовать векторную базу данных, такую как Embeddinghub, чтобы легко отфильтровать похожие элементы на те, к которым пользователь ранее проявлял интерес. Например, вы можете выполнить [ближайший сосед] (https://en. wikipedia.org/wiki/Nearest_neighbour_algorithm) поиск, чтобы найти наиболее релевантный элемент, или вы можете рассчитать среднюю векторную разницу между черным и красным элементом и использовать эту разницу, чтобы рекомендовать ближайший цвет для элементов, которые не имеют красного версия.
В этой статье вы узнаете о лучших вариантах векторной базы данных, их особенностях и их сравнении.
Инструменты для этого обзора
Существует несколько инструментов, которые могут эффективно позволить вашим командам по машинному обучению настроить векторную базу данных для своих проектов. Инструменты для этого конкретного обзора были выбраны на основе удобства использования, гибкости, масштабируемости, стоимости и организационных особенностей.
Юзабилити
Инструмент может быть высокопроизводительным, но оказаться убыточным, если требуется много времени и усилий, чтобы научить вашу команду его настройке и эффективному использованию. Сложные структуры и процессы сложны для нынешних сотрудников и представляют угрозу для проектов при добавлении новых участников.
Поскольку векторные базы данных имеют решающее значение для успеха проектов машинного обучения, они должны быть просты в настройке, изучении и использовании. Такие функции, как поддержка SDK для нескольких языков, управление кластером данных, возможности развертывания и административные надстройки, следует учитывать при рассмотрении вариантов векторной базы данных.
Гибкость
Способность сочетаться с потребностями и экосистемой организации должна быть одним из ваших главных критериев. Если это не так, проектам приходится обходить особенности инструмента, что может ограничивать инновации, функциональность и скорость производства.
База данных векторов должна не только эффективно хранить и извлекать векторы, но и поддерживать общие векторные операции, такие как аппроксимация ближайшего соседа, разбиение пространства, субиндексы и усреднение.
Другим важным аспектом является алгоритм, используемый для вычисления сходства и выполнения векторного поиска. База данных векторов должна не только использовать высокопроизводительный алгоритм, но и в идеале предлагать пользовательские алгоритмы, если возникнет такая необходимость.
Масштабируемость
Базы данных Vector часто интегрируются в существующую инфраструктуру компании с учетом масштаба. Данные, обрабатываемые векторными базами данных, имеют значительный объем и требуют эффективных методов, таких как хэширование и сегментирование, для расширения масштаба. Важно обратить внимание на механизмы хранения и транзакций инструмента, чтобы оценить потенциальную масштабируемость.
Расходы
При выборе векторной базы данных следует учитывать затраты, понесенные во время или планируемые на покупку, настройку и обслуживание. Если это управляемое предложение, структура ценообразования играет огромную роль в определении стоимости инструмента. Для автономной векторной базы данных наиболее важна стоимость инфраструктуры.
Если инфраструктура векторной базы данных надежна, но сложна, со временем она может повлечь за собой высокие затраты из-за обучения, связанного с переходом проекта из рук в руки. Интеграция также может занимать много времени, ее сложнее исправлять и обслуживать, а управление неисправностями может быть проблематичным, что приводит к увеличению времени простоя. В этом отношении такие функции, как автоматическое резервное копирование после аварии, могут стать огромным механизмом экономии средств.
Организационные особенности
Инструменты базы данных Vector имеют определенные основные функции, на которых специализируется каждый отдельный инструмент. Наряду с этими функциями полезно выбирать инструменты, которые могут предложить поддержку для управления периферийными требованиями, такими как административные задачи, безопасность или управление проектами.
Например, инструмент, обеспечивающий мгновенную доступность векторов, информации о кластерах, предупреждений в реальном времени или оркестровки инфраструктуры, упростит и ускорит цикл операций, что приведет к более быстрому производству с минимальным объемом ручного администрирования.
Эти дополнительные функции могут помочь вам сэкономить деньги и устранить необходимость в дополнительных сторонних инструментах в экосистеме. Это также повышает эффективность команды, устраняя такие препятствия, как доработка инструментов, настройка процессов и обслуживание.
Параметры векторной базы данных
В дополнение к упомянутым выше функциям, существуют основные сильные стороны, уникальные для каждого инструмента, которые следует принимать во внимание. Ниже приведены обзоры пяти опций инструментов, которые помогут вам начать работу с векторными базами данных.
EmbeddingHub
[Embeddinghub] (https://github.com/featureform/embeddinghub) — это решение с открытым исходным кодом, предназначенное для хранения вложений машинного обучения с высокой надежностью и легким доступом. Это позволяет выполнять интеллектуальный анализ, например операции приближения ближайших соседей, и регулярный анализ, например разбиение и усреднение. Он использует алгоритм HNSW для индексации вложений с использованием HNSWLib, предлагая высокопроизводительный приблизительный поиск ближайшего соседа.
Инструмент предлагает высокоскоростную обработку за счет локального кэширования во время обучения. Он идеально подходит для масштабирования и может индексировать миллиарды векторов на своем уровне хранения.
Embeddinghub не только эффективен для высокоскоростного анализа больших объемов данных, но и является отличным административным ресурсом. Благодаря таким возможностям, как управление доступом, управление версиями, откат и мониторинг производительности, [документация] (https://github.com/featureform/embeddinghub) этого инструмента чрезвычайно подробна и упрощает быстрый шестиэтапный процесс запуска.
Будучи платформой с открытым исходным кодом, Embeddinghub можно использовать бесплатно, и ее можно загрузить с помощью установки pip. Единственные затраты связаны с использованием смежных инструментов в экосистеме данных.

Милвус
[Milvus] (https://milvus.io) — это облачная база данных векторов, которая может управлять неструктурированными данными. Он поддерживает автоматическое горизонтальное масштабирование и использует методы ускорения для обеспечения высокоскоростного извлечения векторных данных. Milvus обладает дополнительными преимуществами: он удобен для пользователя и экономичен, а также может похвастаться внушительной клиентурой, среди которой такие клиенты, как Moj и Dailyhunt.
Milvus поддерживает несколько приблизительных индексов на основе алгоритма ближайшего соседа, таких как IVF_FLAT, Annoy, HNSW, RNSG и т. д.
С Milvus легко познакомиться с помощью его усовершенствованных и визуально привлекательных [руководств] (https://milvus.io/docs), которые постоянно совершенствуются благодаря большому сообществу пользователей с открытым исходным кодом.
Milvus можно использовать бесплатно, и единственные связанные с этим затраты ограничиваются периферийными ресурсами.
Сосновая шишка
Будучи полностью управляемой векторной базой данных, Pinecone специализируется на предоставлении возможностей семантического поиска для производственных приложений. Он предлагает такие функции, как фильтрация, библиотеки векторного поиска и распределенная инфраструктура, которые обеспечивают надежность и скорость работы. Другие функции включают дедупликацию, сопоставление записей, рекомендации, ранжирование, обнаружение и классификацию.
Pinecone поддерживает точную KNN с [FAISS] (https://github.com/facebookresearch/faiss). Его возможности ANN основаны на собственном алгоритме.
У Pinecone быстрый процесс настройки, для которого требуется всего несколько строк кода, и утверждается, что вы можете добавить его в рабочие приложения за меньшее время, чем другие модели. Наряду с эффективностью векторных данных, Pinecone заботится о таких побочных вещах, как безопасность в средах AWS и GCP, изолированных контейнерах и шифровании. [Руководство] Pinecone (https://www.pinecone.io/docs/) предлагает четкий план процесса установки.
Благодаря [трем уровням ценообразования] (https://www.pinecone.io/pricing/) у Pinecone есть что предложить каждому. Бесплатная версия может помочь вам начать работу, но если вам нужна дополнительная поддержка, масштабирование и оптимизация, вы можете перейти на стандартную версию за семь центов в час. Самый дорогой уровень, называемый корпоративной версией, имеет индивидуальную цену и дополнительные функции, которые можно добавить, такие как поддержка выделенной среды и несколько зон доступности.
Плетение
[Weaviate] (https://www.semi.technology) от SeMI Technologies использует модели машинного обучения для создания и хранения векторов. Он может поддерживать различные типы данных и предлагает помощь в некоторых важных случаях использования, таких как комбинированный векторный и скалярный поиск, извлечение вопросов и ответов, классификация и настройка модели. Инструмент также может выполнять структурированную фильтрацию векторов и доступен через множество языковых клиентов.
Weaviate использует собственный алгоритм HNSW, который поддерживает полный CRUD. Он также может [поддерживать несколько алгоритмов ANN] (https://www.semi.technology/developers/weaviate/current/vector-index-plugins/#can-weaviate-support-multiple-vector-index-ann-plugins) пока они поддерживают полный CRUD.
Weaviate имеет оптимизированное хранилище, которое экономит место для обработки запросов, что приводит к высокой скорости поиска. Другие преимущества включают высокую масштабируемость, экономичность и подробные [руководства] (https://www.semi.technology/developers/weaviate/current/getting-started/) для быстрой настройки.
Инструмент поддерживает индивидуальные цены, основанные на конкретных требованиях пользователя, и предложение можно создать, [связавшись с их командой напрямую] (https://www.semi.technology/products/weaviate/).
Чтобы лучше понять соответствие требованиям, изучите [варианты использования Weaviate] (https://www.semi.technology/industry-solutions/index.html).
Вальд
[Vald] (https://vald.vdaas.org/) — хорошо масштабируемая распределенная векторная поисковая система. Вальд использует граф распределенного индекса для поддержки асинхронного индексирования. Он хранит каждый индекс в нескольких агентах, что позволяет использовать реплики индекса и обеспечивает высокую доступность.
Vald предлагает SDK для нескольких языков, включая Golang, java, NodeJS и Python. Он использует векторный поисковик [NGT] (https://github.com/yahoojapan/NGT), который работает очень быстро и гарантирует высокую производительность.
Vald также имеет открытый исходный код и может использоваться бесплатно. Его можно развернуть в кластере Kubernetes, и единственные затраты — это затраты на инфраструктуру.

Заключение
Векторные базы данных становятся все более распространенными для проектов машинного обучения, вызывая интерес у гигантов мира технологий. Это удобный вариант для групп, управляющих высокоскоростным векторным внедрением в масштабе, и определенная возможность, которую должны изучить малые и средние предприятия.
По сравнению с традиционными базами данных SQL векторные базы данных гораздо лучше подходят для обработки векторных вложений. Они могут использовать векторное представление данных для поиска по сходству и могут использоваться в системах рекомендаций, поисковых системах, НЛП и проектах компьютерного зрения.
Обладая большей гибкостью, чем базы данных SQL, векторные базы данных могут гарантировать, что вы предлагаете релевантные продукты своим пользователям, не перегружая команду обработки данных. Надеюсь, инструменты, описанные в этом обзоре, дали вам хорошее представление о том, что на рынке может помочь вам достичь этих целей.
Оригинал