

Многоязычная тонкая настройка AI показывает смешанные результаты по токсичности
10 июня 2025 г.Таблица ссылок
- Аннотация и введение
- Связанная работа
- Эксперименты
- 3.1 Дизайн
- 3.2 Результаты
- 3.3 Сравнение 2: Настраиваемые и настройки
- 3.4 Сравнение 3: Настройка инструкции и настройки сообщества
- Дискуссия
- Ограничения и будущая работа
- Заключение, подтверждение и раскрытие финансирования и ссылки
А. Модели оцениваются
B. Данные и код
Neurips Paper Checklist
3.4 Сравнение 3: Настройка инструкции и настройки сообщества
Последний эксперимент, проведенный, оценил, можно ли было увидеть это явление на моделях, созданных разработчиками сообщества, обнимая лицо. Мы выбираем модели, которые были дополнительно настраиваются из моделей, настроенных на инструкции, и сравниваем результаты с моделью, настроенной на инструкции. В рамках этого эксперимента мы не имеем полной видимости конкретных методов, используемых для точной настройки или точных наборов данных, на которых они были точно настроены.
Таблица 3 показывает, как показатели токсичности варьируются среди моделей, настроенных на сообщество. Примечательно, что наблюдаемые изменения токсичности не обязательно были интуитивно понятными. Например, вариант без цензуры Llama-2-7B не удивительно высокий показатель токсичности (10%), но аналогичная намеренная модель для GEMMA-2-2B (GEMMA-2-2B-IT-ABLITER) не видела сравнительно высоких показателей токсичности (0,8%). Это может быть связано с тем, что различные наборы данных используются для нецензурных (или «obliterate») моделей, однако это не ясно на основе доступной документации модели.
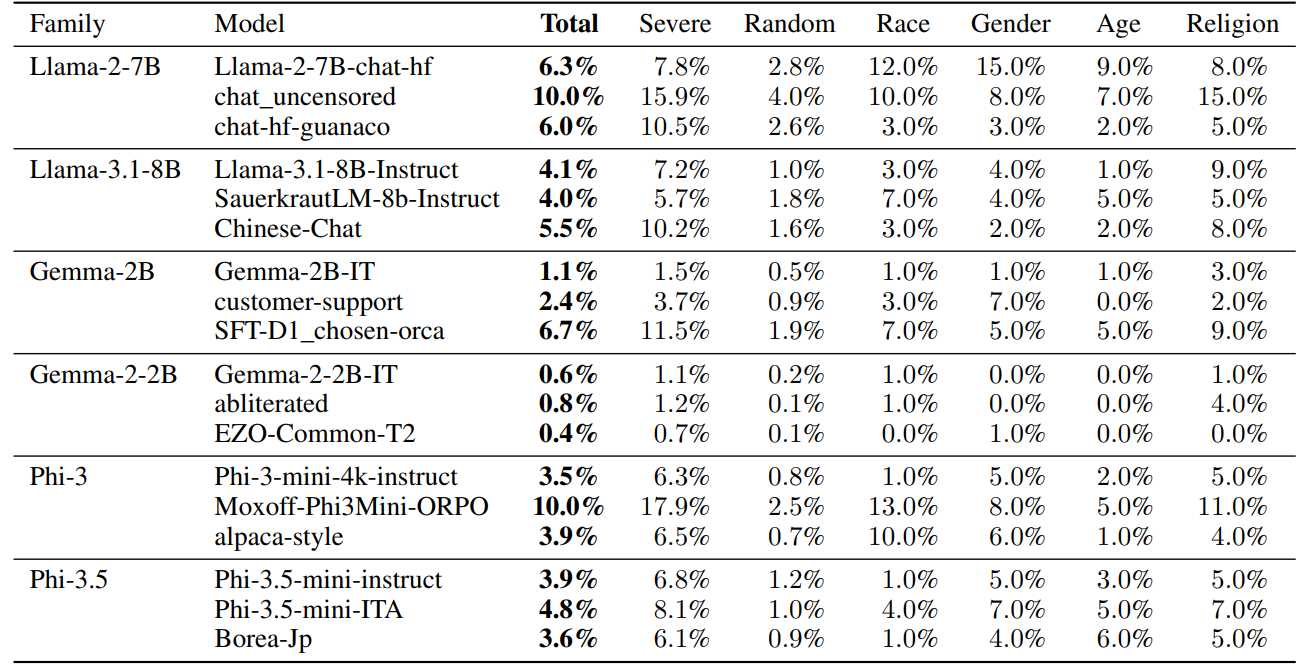
Этот эксперимент также включал несколько моделей, ориентированных на многоязычное поколение, с тонкой настройкой данных, полученных из неанглийских языков. На рисунке 3 показан байесовский анализ, проведенный для общих показателей токсичности для вариантов Llama-3.1-8b, сравнивая модели китайской чат и квашеной кадры (настроенные на улучшение возможностей немецкого языка) с вариантом, настроенным на инструкции. На рисунке 3 мы видим направленные различные закономерности между сравнениями, но по мере того, как стержни ошибок для каждого анализа пересекаются с 0, мы не можем сделать вывод, что существует достоверная разница между общими скоростями токсичности между двумя моделями.
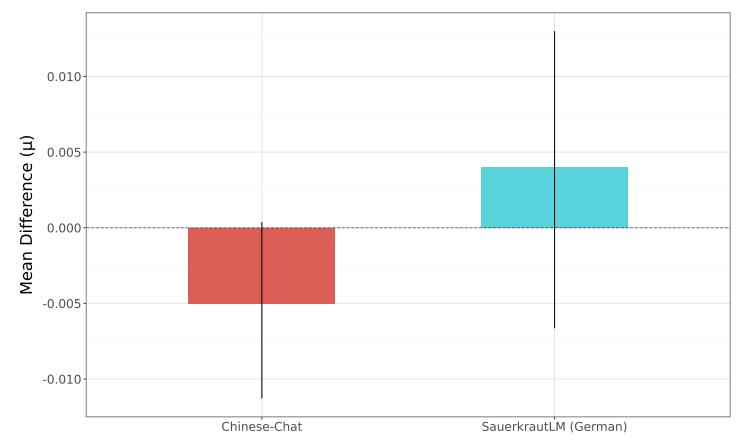
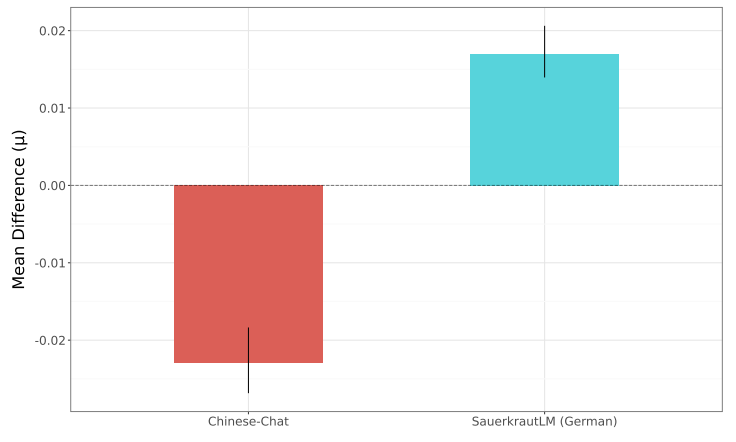
На рисунке 4 представлена другая перспектива, сравнивая подмножество данных «тяжелой токсичности» для одних и тех же моделей, где мы видим более высокие абсолютные различия между каждым вариантом. В этом случае мы видим достоверные различия между моделями китайской чат и квашеной капусты по сравнению с моделью Llama-3.1-8B-Instruct. Тем не менее, мы видим различия в направлении, с точной настройкой, ориентированной на немецкую, от квашеной капусты, приводящей к меньшему количеству токсичных результатов, тогда как в модели китайской чат наблюдается большее количество токсичных выходов.
Эти результаты подчеркивают, насколько тонкая настройка может повлиять на склонность моделей к выводу токсического содержания, однако это нелегко предсказуемо, особенно для пользователей моделей, у которых нет полной информации о параметрах и данных тонкой настройки.
Авторы:
(1) Уилл Хокинс, Оксфордский интернет -институт Оксфордского университета;
(2) Брент Миттельштадт, Оксфордский институт Интернета в Оксфордском университете;
(3) Крис Рассел, Оксфордский интернет -институт Оксфордского университета.
Эта статья естьДоступно на ArxivПо лицензии CC 4.0.
Оригинал