

Производительность прогнозирования с несколькими ток
7 июня 2025 г.Таблица ссылок
Аннотация и 1. Введение
2. Метод
3. Эксперименты по реальным данным
3.1. Шкала преимуществ с размером модели и 3,2. Более быстрый вывод
3.3. Изучение глобальных моделей с помощью мульти-байтового прогноза и 3.4. Поиск оптимальногоне
3.5. Обучение для нескольких эпох и 3.6. Создание нескольких предикторов
3.7 Многократный прогноз на естественном языке
4. Абляции на синтетических данных и 4.1. Индукционная способность
4.2. Алгоритмические рассуждения
5. Почему это работает? Некоторые спекуляции и 5.1. Lookahead Укрепляет очки выбора
5.2. Информация теоретичный аргумент
6. Связанная работа
7. Заключение, Заявление о воздействии, воздействие на окружающую среду, подтверждения и ссылки
A. Дополнительные результаты по самопрокативному декодированию
Б. Альтернативные архитектуры
C. Скорость тренировок
D. МАГАЗИН
E. Дополнительные результаты по поведению масштабирования модели
F. Подробности о CodeContests Manetuning
G. Дополнительные результаты по сравнению с естественным языком
H. Дополнительные результаты по абстрактному текстовому суммированию
I. Дополнительные результаты по математическим рассуждениям на естественном языке
J. Дополнительные результаты по индукционному обучению
K. Дополнительные результаты по алгоритмическим рассуждениям
L. Дополнительные интуиции по многоцелевым прогнозам
М. Обучение гиперпараметры
3.7 Многократный прогноз на естественном языке
Чтобы оценить многократное обучение прогнозирования по естественному языку, мы обучаем модели параметров размера 7B на 200B токенах естественного языка с 4-то-токеном, 2-то-ток-потерей и следующей потерей прогнозирования, соответственно. На рисунке 5 мы оцениваем полученные контрольные точки на 6 стандартных контрольных показателях NLP. На этих критериях модель прогнозирования токенов с двумя итогами работает наравне с базовой линейкой предсказания следующего ток.
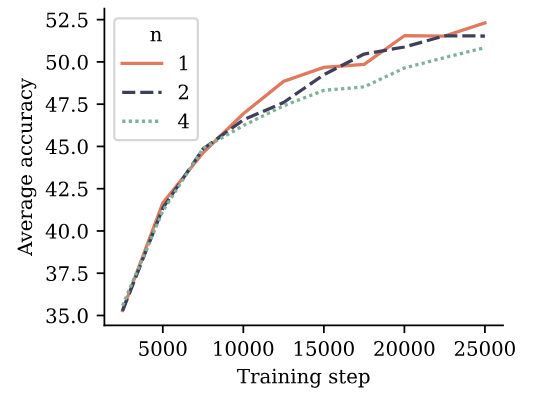
на протяжении всего обучения. Модель прогнозирования токенов с 4 итогами страдает деградацией производительности. Подробные цифры сообщаются в Приложении G.
Тем не менее, мы не считаем, что контрольные показатели на основе множественного выбора и вероятности подходят для эффективного различения генеративных возможностей языковых моделей. Чтобы избежать потребности в человеческих аннотациях качества генерации или языковых судей, которые поставляются с собственными ловушками, как указано Koo et al. (2023)-Мы проводим оценки по сравнению с суммированием и математическими показателями естественного языка и сравниваем предварительные модели с размерами учебных наборов 200b и 500b токенов и с потери прогноза следующего и мульти-token, соответственно
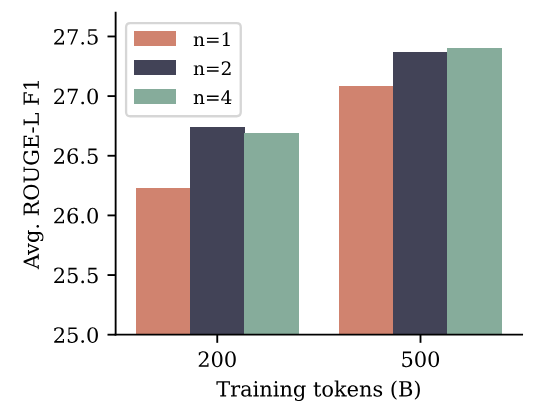
Для суммирования мы используем восемь тестов, где метрики Rouge (Lin, 2004) в отношении резюме грунта позволяют автоматической оценке сгенерированных текстов. Мы определяем каждую предварительную модель на наборе учебного данных каждого теста для трех эпох и выбираем контрольную точку с самой высокой оценкой Rouge-L F1 в наборе данных проверки. На рисунке 6 показано, что модели с несколькими токными прогнозирования как с n = 2, так и N = 4 улучшаются по сравнению с базовой линией следующего ток в Rouge-L F1-баллах для обоих размеров наборов обучения, а разрыв в производительности сокращается с большим размером набора данных. Все метрики можно найти в Приложении H.
Для математики естественного языка мы оцениваем предварительную модели в режиме 8 выстрелов на эталон GSM8K (Cobbe et al., 2021) и измеряем точность окончательного ответа, полученного после цепочки мыслей, вызванной примерами Marting Shot. Мы оцениваем метрики Pass@K, чтобы количественно оценить разнообразие и правильность ответов, как в оценках кода
и использовать температуру отбора проб от 0,2 до 1,4. Результаты изображены на рисунке S13 в Приложении I. Для 200B тренировочных токенов модель n = 2 явно превосходит базовую линию следующего ток-прогноза, в то время как шаблон меняется после 500B токенов, а n = 4 хуже во всем.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Фабиан Глокл, ярмарка в Meta, Cermics Ecole des Ponts Paristech и внес свой вклад;
(2) Badr Youbi Idrissifair в Meta, Lisn Université Paris-Saclay и внес свой вклад;
(3) Baptiste Rozière, ярмарка в Meta;
(4) Дэвид Лопес-Паз, ярмарка в Мете и его последний автор;
(5) Габриэль Синнев, ярмарка в Meta и последний автор.
Оригинал