

Больше, чем чувство: визуализация, почему атомы фильтрации перехитрите Lora в той настройке
1 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
- Предварительный
- Методы
- Эксперименты
- Связанные работы
- Заключение и ссылки
- Детали экспериментов
- Дополнительные экспериментальные результаты
7 деталей экспериментов
7.1 Детали наборов данных
Набор данных VTAB уникально сложный и хорошо подходит для оценки методов настройки, эффективных параметров, в контексте нескольких выстрелов. VTAB-1K охватывает разнообразные домены изображений, включая естественные, структурированные и специализированные категории, такие как медицинские или спутниковые образы. Задачи охватывают различные цели, включающие распознавание объектов и сцены, классификацию расстояний и подсчет. Следовательно, VTAB-1K появляется как очень ценный ресурс, удовлетворяющий потребности как дискриминационных, так и генеративных задач обучения переносам.
В таблице 5 мы предоставляем информацию о 19 задачах набора данных VTAB, включая количество классов и количество изображений в каждом разделении данных VTAB. Изображения в тесте VTAB охватывают три различных домена: (1) природные изображения, снятые с использованием стандартных камер, (2) специализированных изображений, снятых с использованием нестандартных камер, подобных изображениям в дистанционном зондировании и медицинских приложениях, и (3) структурированные изображения, созданные в средах моделирования.
VTAB-1K-это подмножество VTAB. Он содержит только 1000 образцов обучения и валидации, которые предназначены для обучения трансферу с несколькими выстрелами.
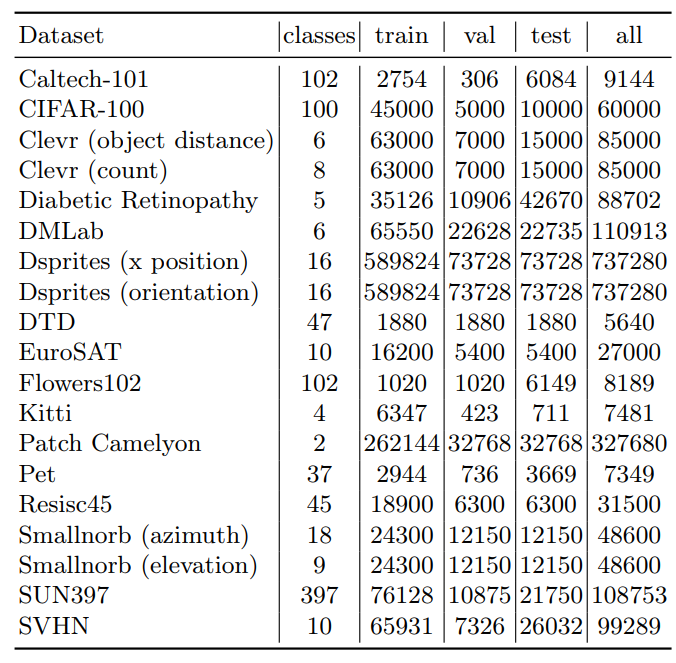
7.2 Экспериментальные настройки
Реализация ЛорыМы принимаем реализацию LORA от https: //github.com/microsoft/lora.
Реализация Loha и LokrМы принимаем реализацию Loha и Lokr с https://github.com/kohakublueleaf/lycoris.
Реализация Difffit и BitFitМы принимаем реализацию Difffit и BitFit от https://github.com/mkshing/difffit-pytorch.
Генеративные задачи
Стабильные диффузионные контрольно -пропускные пункты.Предварительно обученной контрольной точкой, которую мы выбираем для стабильной диффузии, является стабильная диффузия-V1-4, которую можно найти приhttps: // huggingface. co/compvis/stable-diffusion.
Текстовые подсказки для нескольких выстрелов генеративной задачи.Мы используем конкретные текстовые подсказки для обучения стабильной диффузии или генерации изображений. Мы перечисляем пример подсказки для каждого набора данных следующим образом:
- Фотография <Castle>.
-<замок> стоит на фоне снежных гор.
- А <замк> в окружении пышного, яркого леса.
- <замок> выходит на безмятежное озеро.
- <замок> в осенний сезон с красочной листвой.
- <Castle> на скалистом скале, с разбивающимися волнами внизу.
- <замок> охраняется мифическими эльфами.
- А <<Castle> в окружении поля пастбищных овец.
- павлин перед <замком>.
- <замок> выходит на безмятежное озеро, где плывут семья гусей.
- <Замок>, масляная живопись Гибли.
- <Castle> Живопись художника Клода Моне.
- <Castle> Цифровая живопись 3D Render Geometric Style.
- Джорджия О'Кифф Стиль <Касл> Живопись.
- Акварельная живопись <замка>.
- <замок> окружен потусторонним ландшафтом, со светящимися грибами и мистическими существами.
- <замок>, сделанный из кристалла, мерцания на солнечном свете.
- <Castle>, эстетика стимпанк, украшенная передачами и металлическими акцентами.
- <замок> на вершине мистического плавучего острова.
- Вид на верхнюю часть <Castle>.
Текстовые подсказки для полной генеративной задачи.Мы используем конкретные текстовые подсказки для обучения стабильной диффузии или генерации изображений. Мы перечисляем пример подсказки для каждого набора данных следующим образом:
-Caltech-101: Это картина аккордеона.
-CIFAR-100: Это изображение Apple.
- CLEVR: Это картина из набора данных CLEVR.
- Диабетическая ретинопатия: это изображение сетчатки без диабетической ретинопатии.
- DMLAB: Это изображение из набора данных DMLAB.
- DSPRITE: это картина из набора данных DSPRITES.
- DTD: Это изображение полосатой текстуры.
- Eurosat: Это спутниковая картина годовой урожай.
- Flowers102: Это картина розовой первоцветы.
- Китти: Это картина из набора данных Kitti.
- Патч Camelyon: Это гистопатологическое сканирование без опухоли.
- ПЭТ: Это картина абиссинской кошки.
- RESISC45: Это изображение самолета дистанционного зондирования.
- SmallNorb: Это картина из набора данных SmallNorb.
- Sun397: Это картина аббатства.
- SVHN: Это изображение уличного вида дома номер 0.
8 дополнительных экспериментальных результатов
8.1 Эксперименты по проверке
Мы предоставляем дополнительные эксперименты с M = 6, 12 на рисунке 6. По мере увеличения M до 6 до 12 точность улучшается с 66,86% до 68,68%.
8.2 Дополнительные эксперименты по дискриминационным задачам
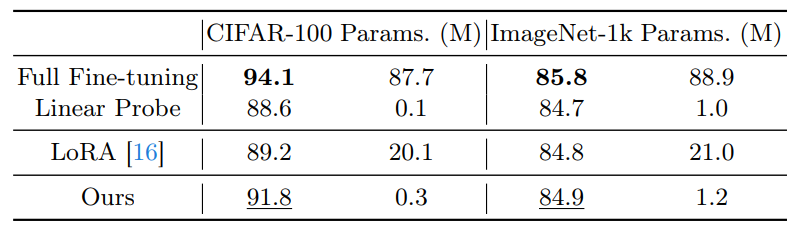
Сравнение производительности на полной настройке данных.
Детали реализации.Для CIFAR-100 и ImageNet-1K мы следуем за настройкой Convenext в [30]. Мы используем оптимизатор ADAMW [33] для моделей тонкой настройки для 100 эпох для CIFAR-100 и 30 эпох для ImageNet1k. Стратегия распада косинуса принята для графика обучения, а линейная разминка используется в первые 10 эпох для CIFAR-100 и 5 эпох для ImageNet-1K.
Мы сравниваем производительность нашего подхода с другими базовыми методами, и результаты по CIFAR-100 и ImageNet-1K показаны в таблице 6. С полной настройкой данных, полная точная настройка достигает самой высокой точности, превосходящих методы точной настройки параметров. Одна из возможных причин заключается в том, что оба набора данных имеют достаточные данные для предотвращения переваренной модели. Наш метод достигает более высокой точности, чем LORA, в то же время требуя лишь небольшого количества параметров (1,2 м В.С. 21M). Напротив, в эталоне VTAB-1K объем данных не очень велик (например, только 1000 обучающих изображений), что может вызвать чрезмерное приспособление модели для полной точной настройки.
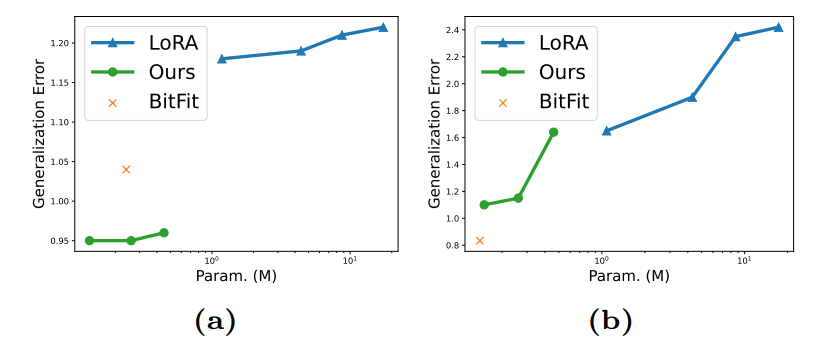
Визуализация ошибки обобщения.Чтобы углубиться в то, как различные методы тонкой настройки влияют на возможности обобщения предварительно обученных моделей, мы проиллюстрируем на рисунке 7 ошибку обобщения для дискриминационной задачи, обученной наборам данных CIFAR-100 и диабетической ретинопатии, в отношении количества тонких параметров.
8.3 Результаты нескольких выстрелов-генеративных задач
Мы предоставляем больше экспериментальных результатов нескольких выстрелов в таблице. 7 и 8. В этом эксперименте мы также включаем Lora, Loha и Lokr с различными конфигурациями.
Сгенерированные изображения различных методов точной настройки показаны на рисунке 8 и 9.


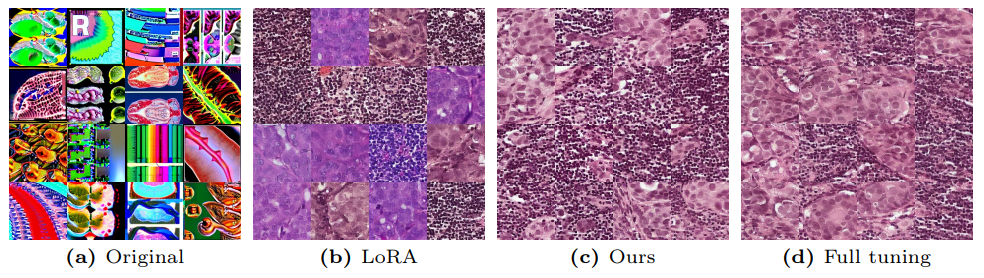
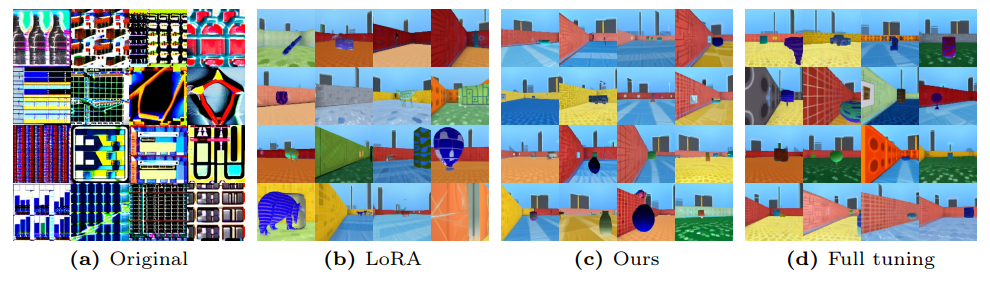
8.4 Визуализация сгенерированных изображений
Мы визуализируем изображения, сгенерированные моделями, подготовленными по каждой из задач VTAB с рисунка 10 до рисунка 25.
8.5
Чтобы понять основную причину эффективности нашего подхода к моделям, основанным на свертывании, мы используем Grad-Cam [9] в первом блоке Resnet50, который настраивается в наборе данных Cub [67], используя ту же экспериментальную обстановку, что и выше. Для нашего метода мы сравниваем настройку эксперимента с M = 9, что означает 9 атомов фильтра ∆D и настройки с (M, M1) = (9, 4), что означает 36 ∆D1.
Основываясь на визуализации выпускной камеры на рисунке 26, наш метод демонстрирует большие активные области по сравнению с LORA. Это наблюдение указывает на то, что наш подход выигрывает от сохранения пространственной структуры сверточных слоев. При использовании ∆D1, который расширяет количество атомов фильтров, мы наблюдаем более активные области в тепловой карте выпускника. Это говорит о том, что введение дополнительных атомов фильтра потенциально отражает более широкий спектр карт признаков.
Мы обеспечиваем больше визуализации тепловой карты Grad-Cam от первого блока Resnet50 на рисунке 27.
![Fig. 8: Images sampled from Stable Diffusion [49] checkpoints fine-tuned with different approaches. The text prompts used to generate images from top to bottom are: “The <castle> stands against a backdrop of snow-capped mountains”, “A <castle> surrounded by a lush, vibrant forest”, “A peacock in front of the <castle>”, and ‘The <castle> overlooks a serene lake, where a family of geese swims”.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-ni433x4.png)
![Fig. 9: Images sampled from Stable Diffusion [49] checkpoints fine-tuned with different approaches. The text prompts used to generate images from top to bottom are: “The <castle> stands against a backdrop of snow-capped mountains”, “A <castle> surrounded by a lush, vibrant forest”, “A peacock in front of the <castle>”, and ‘The <castle> overlooks a serene lake, where a family of geese swims”.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-7553391.png)














![Fig. 26: The Grad-CAM heatmap comparisons between our method and LoRA reveal that our approach exhibits larger active regions. The heatmap is generated from the first block of ResNet50 [13] utilizing the CUB dataset [67]. Fine-tuning the model with ∆D1 involves additional filter atoms, which leads to larger active regions in the heatmap compared to fine-tuning ∆D only. (a) The Grad-CAM from the first block of ResNet50. (b-d) The Grad-CAM from the 2-4 blocks of ResNet50.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-tfm33xy.png)

Авторы:
(1) Вэй Чен, Университет Пердью, Индиана, США (chen2732@purdue.edu);
(2) Zichen Miao, Университет Пердью, Индиана, США (miaoz@purdue.edu);
(3) Qiang Qiu, Университет Пердью, Индиана, США (qqiu@purdue.edu).
Эта статья есть
Оригинал