

Модернизируйте свою платформу Spark с помощью оркестрации данных
11 марта 2022 г.Хоуп Ван и Шоуэй Чен
Alluxio — это платформа для оркестровки данных, позволяющая унифицировать хранилища данных в разнородных средах. Это последняя статья в серии, посвященной основам архитектуры и решения Alluxio. Также ознакомьтесь с этой серией здесь: обзор вариантов использования, Presto + Alluxio обзор, обучение машинному обучению с обзором Alluxio.
Apache Spark — это платформа вычислений с открытым исходным кодом, которая поддерживает широкий спектр аналитических функций — ETL, SQL-запросы, машинное обучение и потоковые вычисления. Модель данных Spark в памяти и быстрая обработка делают ее широко используемой организациями, работающими с данными.
Для глобальной платформы данных следующие факторы часто приводят к медленной окупаемости, высоким затратам и снижению гибкости:
- Сегодня данные хранятся в хранилищах, включая озера данных, хранилища данных и хранилища объектов, будь то локально, в облаке или в нескольких географических точках. Сложно найти решение, которое объединяет данные из многих источников и эффективно передает их в Spark.
- Сквозной конвейер данных требует использования Spark вместе с другими вычислительными платформами, такими как Presto, TensorFlow и т. д., что требует комплексного подхода к разработке архитектуры платформы данных. Кроме того, организации застряли на устаревших платформах данных, созданных в дооблачную эпоху, и им не хватает собственных облачных возможностей или требуется сложная миграция в облако.
Вы ищете архитектурные инновации для решения этих проблем? Alluxio здесь, чтобы помочь. Созданная в AMPLab Калифорнийского университета в Беркли — той же лаборатории, что и Spark, — Alluxio представляет собой платформу оркестрации данных с открытым исходным кодом, которая устраняет разрыв между вычислениями и хранилищем. Alluxio расширяет возможности Spark, объединяя хранилища данных, обеспечивая совместное использование данных между вычислительными платформами и беспрепятственный перенос данных из разных сред.
Объединив Alluxio со Spark, вы сможете модернизировать свою платформу данных масштабируемым, гибким и экономичным способом. В этом посте мы представляем обзор стека Spark + Alluxio. Мы объясняем архитектуру, обсуждаем реальные примеры, описываем модели развертывания и демонстрируем сравнение производительности и затрат.
Почему оркестрация данных
Alluxio — это платформа для оркестрации данных, которая находится между вычислениями (например, Spark, Presto, Tensorflow, MapReduce) и хранилищем (например, Amazon S3, HDFS, Ceph) как для архитектуры, так и для бизнеса.
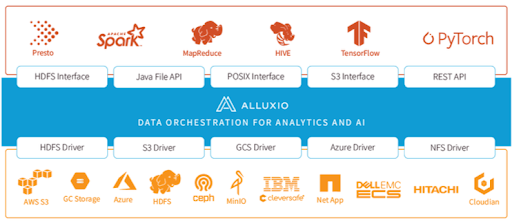
Архитектурные преимущества
Унифицированный доступ к данным — объединение хранилищ данных и доступ без перемещения данных
В идеале вам нужен единый источник достоверных данных для ваших данных, но с растущим числом аналитических приложений и бизнес-групп разрозненность неизбежна. Репликация данных из множества источников в центральный репозиторий больше невозможна, так как это требует ручного перемещения и дублирования данных между разрозненными хранилищами, что отнимает много времени и чревато ошибками.
Alluxio объединяет все источники данных, создавая уровень абстракции между вычислениями и хранилищем. [Единое пространство имен] (https://docs.alluxio.io/os/user/stable/en/core-services/Unified-Namespace.html) позволяет получить доступ к нескольким независимым системам хранения независимо от их физического местоположения. Реализованы следующие архитектурные преимущества:
- Единый источник достоверной информации для Spark и не только: Alluxio предоставляет единую точку доступа ко всем данным, независимо от того, где они находятся. Поскольку Alluxio абстрагирует уровень хранения, вы можете смонтировать любую систему хранения в Alluxio как папку. Spark нужно только подключиться к Alluxio, который сам справляется со сложностью подключения разных доменов.
- Устраните ручное копирование и ненужное перемещение данных: Поскольку Alluxio представляет единое представление всех данных, вам больше не нужно управлять копиями данных или перемещать данные вручную. Данные остаются там, где они хранятся — локально, в облаке или и там, и там — и данные в Alluxio автоматически синхронизируются с базовым хранилищем в случае обновлений или других изменений. Alluxio поддерживает самую последнюю копию данных или извлекает их из хранилища, чтобы обеспечить актуальность данных.
- Включить отдельные вычисления и хранилище. Архитектура разделения вычислений и хранилища оптимизирует выделение и использование ресурсов хранения и вычислений. Но это также вызывает проблемы с задержкой, особенно когда данные удалены. Alluxio может развертываться совместно со Spark и управлять его носителями. Когда Spark обращается к удаленным данным, производительность такая же, как если бы он был локальным, поскольку Alluxio обеспечивает локальность горячих данных для приложений.
- Нет влияния на приложение. При внесении изменений на стороне хранилища существующие приложения для анализа данных, включая Spark, могут работать поверх Alluxio без каких-либо изменений кода. Предоставляя один и тот же API для существующих приложений, Alluxio создает удобный интерфейс для конечных пользователей, ускоряя внедрение новых технологических стеков.
Эффективный обмен данными — высокопроизводительный обмен данными во всех платформах вычислений
Типичный конвейер обработки данных представляет собой серию шагов, включая прием данных, подготовку данных, аналитику и машинное обучение. Вы можете использовать один вычислительный движок, а затем другой, например ETL со Spark, затем запрос SQL с использованием Spark или Presto, а затем обучение машинному обучению с использованием Spark MLib или PyTorch по результатам запроса.
Alluxio охватывает весь конвейер данных и позволяет совместно использовать данные в виде распределенного кеша для нескольких источников данных, совместно используемых на нескольких этапах. Прием данных, ETL, аналитика, машинное обучение могут совместно использовать промежуточные результаты, чтобы одна вычислительная машина могла использовать выходные данные другой. Реализуются следующие архитектурные преимущества:
- Повышенная производительность для всех вычислительных механизмов. Поскольку Alluxio охватывает весь конвейер данных, он позволяет любой вычислительной платформе использовать ранее кэшированные данные для улучшения рабочих нагрузок как чтения, так и записи. Alluxio управляет локальным хранилищем на вычислительных узлах (с помощью Spark и других вычислительных платформ). Когда задание Spark на этапе загрузки записывает данные в Alluxio, те же данные кэшируются в Alluxio и становятся доступными для будущих этапов. Помимо ускорения Spark, весь конвейер данных имеет более высокую сквозную производительность.
- Увеличьте пропускную способность для всего конвейера данных. С повышением вычислительной мощности некоторые рабочие нагрузки становятся привязанными к вводу-выводу, а не к вычислениям. Alluxio обеспечивает более высокую пропускную способность чтения/записи с локализацией данных. В рабочих нагрузках, требующих большого количества операций ввода-вывода, таких как обучение машинному обучению, снижение сетевого трафика и увеличение пропускной способности данных значительно улучшает использование дорогостоящих ресурсов графического процессора. Таким образом, платформы данных могут добиться лучшего использования ресурсов.
Бесшовная миграция данных — модернизируйте свою платформу данных и ускорьте миграцию в облако
Приложения, созданные на основе Spark, опираются на базовую платформу данных, которая должна постоянно масштабироваться и модернизироваться, чтобы соответствовать постоянно растущим требованиям как рабочих нагрузок, так и данных. Когда ваша платформа данных не может обрабатывать объемы или скорость данных, вы начинаете рассматривать возможность миграции. Возможно, вы захотите избавиться от устаревших платформ, но миграция данных никогда не бывает легкой, будь то из локальной среды в облако или просто из одного центра обработки данных в другой.
Здесь на сцену выходит Аллуксио. Alluxio представляет собой единое представление для различных разнородных источников. С помощью Alluxio вы можете постепенно переносить конвейер данных из локальной среды в облако с гибридной платформой данных. Alluxio может беспрепятственно перемещать данные из одной системы хранения в другую, пока вы выполняете задания Spark без перерыва.
- Расширение гибридного облака. Ваш путь миграции в облако может начаться с локального основного источника данных и использования Spark в общедоступном облаке. Гибридная пакетная передача в облако с нулевым копированием позволяет начать использовать вычисления в облаке, оставив данные локально. Ваша локальная платформа данных может сосуществовать с модернизированной облачной платформой данных, когда вы начнете миграцию.
- Динамическая миграция данных в облачное хранилище без простоев. Традиционно миграция включает в себя сначала копирование данных из источника в место назначения, обновление всех существующих приложений новыми URI и удаление исходных копий данных. Используя политики переноса данных Alluxio, это можно сделать без проблем. Приложения и каталоги данных остаются непрерывными, когда данные перемещаются из локального хранилища в облако или из одного центра обработки данных в другой.
- Включить гибридную и многооблачную архитектуру. Гибридное облако часто является архитектурным выбором, а не промежуточным этапом. Устаревшие и современные системы могут существовать одновременно в гибридных или мультиоблачных средах, чтобы соответствовать требованиям соответствия, защищать существующие инвестиции и избегать привязки к поставщику облачных услуг. Alluxio позволяет использовать гибридную архитектуру с малой задержкой и производительностью, как если бы данные находились в кластере облачных вычислений. Данные могут управляться безопасным образом независимо от местоположения.
Ценность для бизнеса
В конечном счете, Spark обслуживает бизнес-аналитиков и специалистов по данным, которые извлекают пользу из данных для ваших организаций. Используя Alluxio со Spark, вы получите выгоду от оркестровки данных, которая позволит вашей организации быстрее получать ответы, повышать операционную эффективность, сокращать расходы, а также быть более гибкой и гибкой.
Более быстрое получение информации
Инженеры платформы данных часто перегружены запросами от бизнес-пользователей. Организации вынуждены долго ждать ответов на критические вопросы, что приводит к медленному окупаемости.
Благодаря Alluxio данные сразу же становятся доступными для более быстрого анализа данных, поскольку Alluxio предоставляет единый источник достоверных данных для разрозненных данных. Кроме того, высокая производительность, обеспечиваемая Alluxio, может значительно сократить время ожидания и позволить организациям быстрее осознать ценность и иметь возможность отвечать на больше вопросов, чем раньше. Более быстрое получение информации для вашей организации означает принятие более взвешенных решений, что обеспечивает решающее конкурентное преимущество.
Значительная экономия средств
Одним из основных мотивов перехода в облако является возможность экономичного масштабирования в сторону увеличения или уменьшения без необходимости приобретения нового оборудования для хранения данных. Alluxio помогает в полной мере использовать преимущества облака.
Когда вы используете облачные хранилища объектов, Alluxio помогает значительно снизить затраты на выход из сети за счет кэширования данных, что позволяет избежать многократного извлечения данных непосредственно из облачного хранилища. Кроме того, спотовые инстансы — это экономичный выбор, если вы можете гибко определять время запуска ваших приложений Spark и возможность их прерывания. Alluxio можно развернуть как автономный кластер для обеспечения высокой доступности и отказоустойчивости, что позволяет масштабировать кэш отдельно от Spark на спотовых инстансах. В части 3.2 мы предоставляем контрольную стоимость с использованием спотовых инстансов.
Организационная гибкость и гибкость
Alluxio позволяет организациям демократизировать доступ к своим данным, объединяя хранилища данных. Благодаря меньшему давлению на инженеров платформ данных легко внедрять новые варианты использования, поскольку нет необходимости перепроектировать конвейер данных. Это значительно сокращает время, необходимое для подготовки новой инфраструктуры, и снижает эксплуатационные расходы на ее обслуживание.
Alluxio также предоставляет свободу и удобство для подключения новых инновационных технологических стеков к вашей платформе данных. Среда данных сегодня не будет такой же через год или два в будущем. Важно иметь архитектуру, которая не зависит от вычислений, хранения и облака, чтобы адаптироваться к изменениям технологических стеков и потребностей бизнеса, и именно здесь появляется Alluxio. С Alluxio вы получите свободу на всех уровнях в технологический стек.
Общие примеры использования и практические примеры
Здесь мы представляем три наиболее распространенных варианта использования Spark с Alluxio, каждый с реальным примером.
Повышение эффективности обучения модели за счет обмена данными от предварительной обработки до обучения
Первый вариант использования — обмен данными между вычислительными платформами. В качестве примера мы используем рабочие нагрузки машинного обучения. Рабочие нагрузки машинного обучения часто делают более частые запросы ввода-вывода к большему количеству файлов меньшего размера, чем традиционные приложения для анализа данных. Alluxio обеспечивает обмен данными, охватывающий сквозной конвейер предварительной обработки, загрузки, обучения и вывода данных, и все это хорошо поддерживается. Повышая эффективность ввода-вывода, можно значительно увеличить скорость конвейера и использование графического процессора. Доказано, что Alluxio обеспечивает 9-кратное повышение эффективности ввода-вывода.
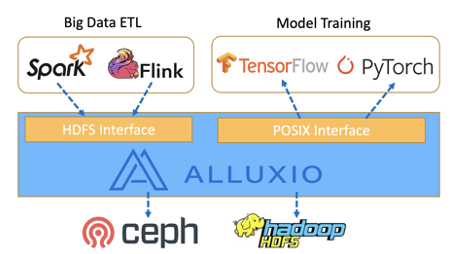
Boss Zhipin (NASDAQ: BZ) — крупнейшая онлайн-платформа для подбора персонала в Китае. В Boss Zhipin Alluxio используется в качестве уровня обмена данными для ETL и обучения моделей. Spark и Flink считывают данные из Alluxio, предварительно обрабатывают данные, а затем записывают обратно в кэш Alluxio. В серверной части Alluxio сохраняет предварительно обработанные данные обратно в Ceph и HDFS. Затем TensorFlow, PyTorch и другие приложения Python могут считывать предварительно обработанные данные из Alluxio для обучения, не дожидаясь завершения записи в Ceph или HDFS. Чтобы узнать больше, посмотрите выступление (на китайском языке) здесь.
Аналитика гибридного облака с вычислениями в облаке и локальными данными
Второй вариант использования — перенос рабочих нагрузок Spark в облако с локальными данными в HDFS или хранилище объектов, как показано ниже. Alluxio подключает локальные хранилища данных и интеллектуально приближает данные к Spark по запросу. Это позволяет достичь высокой производительности в гибридной облачной среде без ручного перемещения данных.
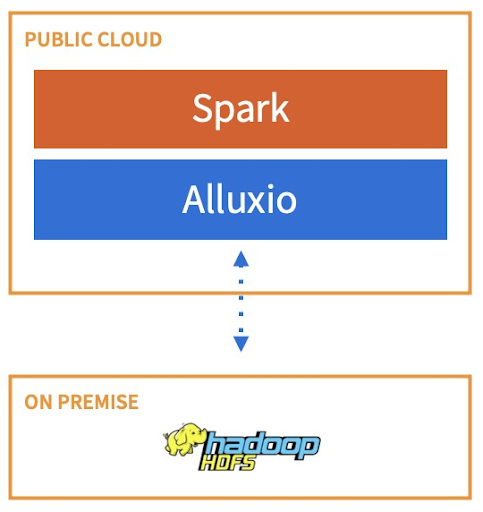
Ведущий хедж-фонд с более чем 50 миллиардами долларов под управлением использовал Alluxio для этого варианта использования. Их основными требованиями являются производительность (ежедневно создается больше моделей машинного обучения), безопасность и гибкость. При развертывании Alluxio рабочие нагрузки Spark находятся в облаке Google, а данные остаются локально в HDFS. Используя Alluxio, они повысили производительность, добились 4-кратного увеличения количества запусков моделей в день и сокращения затрат на вычисления на 95 %. Внедрение Alluxio в свою платформу данных не требует внесения изменений в существующие приложения или инфраструктуру хранения. Данные в Alluxio зашифрованы, а постоянное хранилище в облаке отсутствует, что обеспечивает требования безопасности. Узнайте больше о прецеденте в [этом примере] (https://www.alluxio.io/resources/case-studies/hedge-fund-improves-machine-learning-model-performance-4x-with-alluxio/). .
Бесшовный доступ к данным отовсюду
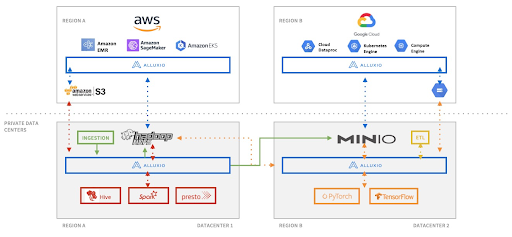
В этом варианте использования существует несколько вычислительных платформ и систем хранения, охватывающих разные регионы, как локально, так и в общедоступном облаке. Такое сочетание создает беспрецедентные проблемы для доступа к данным. Alluxio объединяет и синхронизирует данные между различными частями инфраструктуры в конвейере данных без изменения приложений.
В этом случае возможности Alluxio используются полностью. Alluxio устраняет сложность управления данными между различными хранилищами данных и полностью разделяет вычислительные платформы и системы хранения. Пока приложения взаимодействуют с Alluxio, им не нужно беспокоиться о том, где хранятся данные или как их перемещать, поскольку все это обрабатывается Alluxio.
Ведущая телекоммуникационная компания стремилась со временем модернизировать платформу данных, использовать новые возможности и найти прагматичный способ, не влияющий на работу конечных пользователей. Сначала они использовали Alluxio для миграции в облако с данными в облаке и вычислениями, размещенными локально. Затем Alluxio предоставила единое представление для нескольких центров обработки данных и возможность перемещать данные из одного центра обработки данных в другой.
Инфраструктура платформы Alluxio позволяет им анализировать глобально распределенные данные без необходимости подверженного ошибкам, трудоемкого и ручного перемещения данных. Alluxio предлагает более гибкий подход к модернизации своей платформы данных без ущерба для работы конечных пользователей.
Эталонные показатели производительности и экономия средств
Эталон производительности
При сравнении общего времени выполнения всех 100 запросов, включенных в эталонный тест TPC-DS, Alluxio показывает увеличение производительности на 57 % по сравнению с S3 со стандартной конфигурацией Amazon EMR. Подробнее см. в этом [белом документе] (https://www.alluxio.io/resources/whitepapers/evaluating-apache-spark-and-alluxio-for-data-analytics/).
Сократите расходы с помощью спотовых инстансов
Для гибридной облачной среды с вычислениями в облаке и локальным хранилищем использование спотовых инстансов может значительно снизить затраты. Alluxio можно развернуть как автономные экземпляры по запросу для хранения кэшированных данных, в то время как Spark использует спотовые экземпляры. Кэширование с использованием инстансов по запросу обеспечивает высокую доступность данных, на которую не влияют сбои, поскольку вычислительные инстансы могут быть восстановлены. Спотовые инстансы намного дешевле, а количество инстансов по запросу, необходимых для Alluxio, составляет лишь часть от общей стоимости.
Чтобы имитировать реальный сценарий со спотовыми инстансами, мы «вытесняем» инстансы, вручную завершая инстансы из консоли AWS, чтобы имитировать реальный сценарий как спотовые инстансы. Мы заставляем драйвер Spark перепланировать задачи на существующих узлах, вручную убивая экземпляры. Мы запускаем две непрерывные итерации в качестве основы, а затем два прерванных задания Terasort, чтобы проверить этот подход.
Непрерывное время работы Terasort (100 ГБ)
| Искра на S3 | Искра на Аллюксио |
| 4 минуты 12 секунд | 4 минуты 24 секунды |
Прерванное время выполнения Terasort (100 ГБ)
| Искра на Аллюксио (10 рабочих Аллюксио) | Искра на Аллюксио (20 рабочих Аллюксио) |
| 8 минут 56 секунд | 7 минут 14 секунд |
Затем мы запустили DFSIO для измерения пропускной способности записи и обнаружили, что 1 кластер Alluxio может обслуживать 14 кластеров Spark без снижения производительности или задержки. Кроме того, использование Alluxio в качестве автономного кластера в облаке сохраняет аналогичную производительность.
Исходя из этого базового уровня, мы рассчитываем экономию затрат на облако с помощью автономного кластера Alluxio для Spark на месте.
| |
АВС | опорная точка |
| Топология для поддержки 1 пользователя | 59% | 56% |
| Топология для поддержки 50 пользователей | 74% | 75% |
Таким образом, мы видим, что на кластер Alluxio приходится лишь небольшая часть общей стоимости решения, и эта архитектура может обеспечить экономию затрат на 56–75% по сравнению с отказом от использования спотовых инстансов.
Начать
Если вы использовали Spark для приложений бизнес-аналитики, науки о данных и машинного обучения, пришло время начать использовать Alluxio. С помощью Alluxio вы можете унифицировать хранилища данных, обмениваться данными между вычислительными платформами и легко переносить данные между средами.
Чтобы начать работу с Spark + Alluxio, просмотрите это 5-минутное руководство и документация для получения дополнительной информации. Вы можете загрузить бесплатную версию Alluxio Community Edition или пробную версию Alluxio Enterprise Edition здесь, чтобы узнать о преимуществах Spark + Alluxio для собственных сценариев использования. Мы работаем с сообществом открытого исходного кода, чтобы продолжать улучшать и оптимизировать экосистему данных. Присоединяйтесь к сообществу slack channel сегодня и общайтесь с нашими пользователями или разработчиками.
Ссылки
- Советы по настройке производительности: 10 лучших советов, как сделать стек Spark + Alluxio невероятно быстрым
- Документация: Запуск Spark на Alluxio
Оригинал