

Смесь агентов (MOA): улучшение качества LLM за счет многоагентного сотрудничества
11 августа 2025 г.АСмесь агентов (MOA)Структура переопределяет то, как мы продвигаем большие языковые модели (LLMS) до более высоких уровней точности, глубины рассуждений и надежности, - без чрезмерной стоимости масштабирования одной массивной модели.
Вместо того, чтобы полагаться на один LLM «гнездо», MOA организует команду специализированных моделей, которые сотрудничают в структурированных слоях, уточняя выходы шаг за шагом. Этот подход показываетсовременный (SOTA)Результаты с использованием дажеМодели с открытым исходным кодом, превосходящие ведущие запатентованные LLM, такие как GPT-4 Omni на нескольких тестах.
Сотрудничество среди LLMS.Зачем вообще комбинировать модели? Команда MOA обнаружила, что многие готовые LLM улучшаются при консультации с ответами друг друга. В экспериментах по тесту Alpacaeval 2.0, такие модели, как Llama, Wizardlm и Qwen, выполнялись лучше («скорость победы» против ссылки GPT-4), когда дают ответы на одноранговый модель в дополнение к подсказке.
ВРисунок 1, скорость победы каждой модели прыгает (Red Bars против синего), когда видит ответы других - доказательства того, что LLMS«По сути, сотрудничать»и может уточнить или проверять ответы на основе друг друга. Важно отметить, что это удерживается, даже если ответы на сверстникихудшийчем то, что модель сделала бы в одиночку. Другими словами, многочисленные перспективы помогают LLM избежать слепых пятен. Это понимание вызвало дизайн MOA: основу дляиспользовать коллективный опытнескольких моделей.
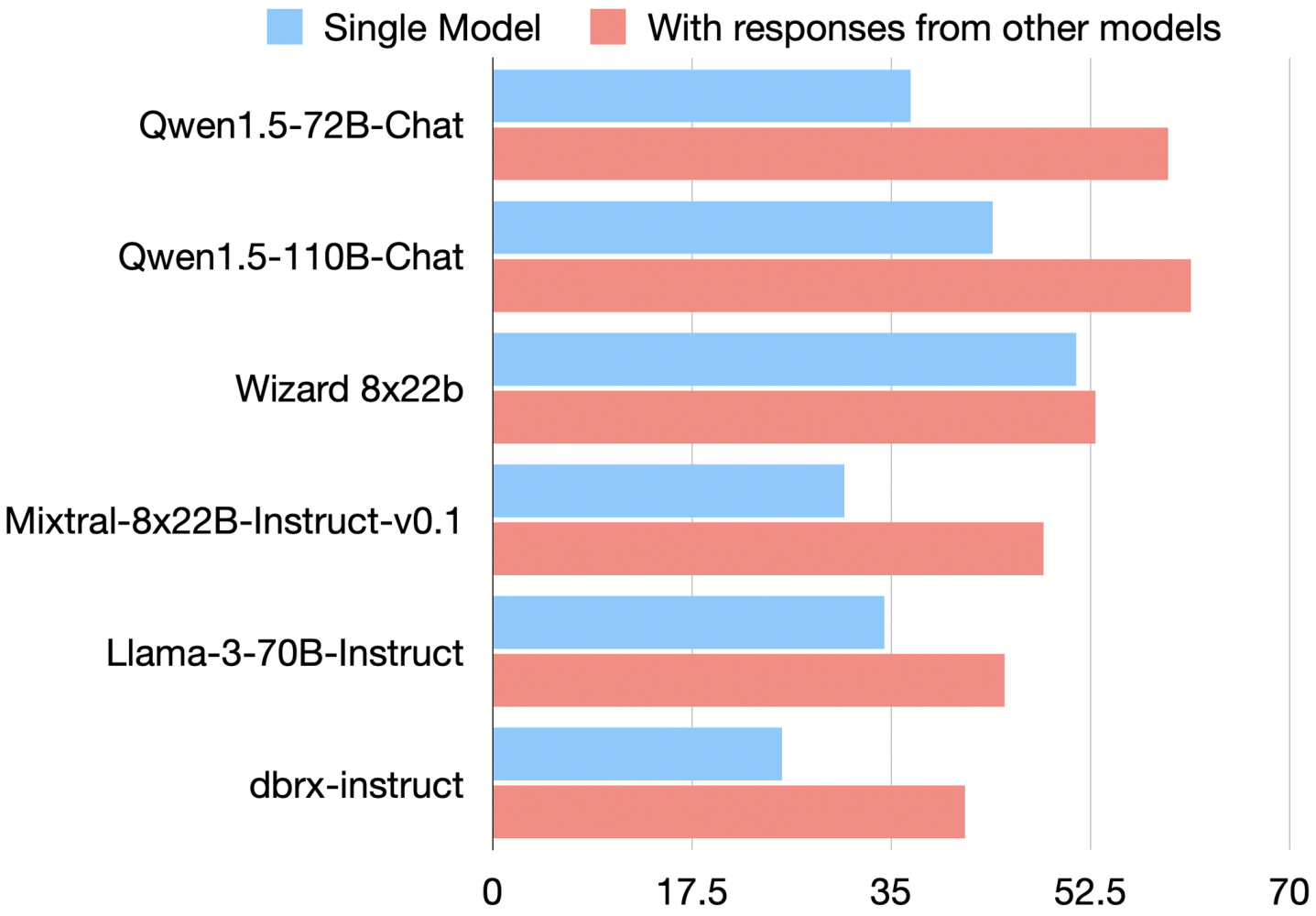
*Рисунок 1: Эффект «совместной работы» - LLMS оценка выше на Alpacaeval 2.0, когда предоставляется ответы других моделей (красный) по сравнению с одинокими (синий). Даже лучшие модели (например, QWEN 110B) выигрывают от сотрудничества со сверстниками, мотивируя MOA.*Архитектура смеси агентов.
Преимущество MOA
MOA решает эти проблемы со структурированным, многоагентным подходом:
- Многослойный дизайн- Несколько агентов на слое, каждый из которых принимает все предыдущие выходы в качестве входных данных.
- Ролевая специализация- Предложения: генерируйте разнообразные ответы кандидатов. Агрегаторы: слияние и переработать в единый, более качественный выход.
- Итеративное улучшение- Каждый слой основан на предыдущем, постепенно повышает точность и согласованность.
- Модельное разнообразие- Сочетание различных архитектур уменьшает общие слабости.
- Не требуется точная настройка- работает полностью через быстрое инженер.
КаждыйагентLLM назначен одна из двух ролей:ПредложенияилиАгрегаторыПолем
Агенты -предложения
Создайте ответы кандидатов - они «преуспевают в создании полезных эталонных ответов», которые добавляют контекст и разнообразные перспективы. Предположение может не дать лучший окончательный ответ, но он вносит ценные кусочки головоломки.
Агрегаторские агенты
Напротив, специализироваться насинтезирующийи улучшение результатов других. Хороший агрегатор может взять набор грубых ответов и объединить их в единый качественный ответ,поддержание или повышение качестваДаже если некоторые входные данные слабы.
Многие модели могут действовать в любой роли - например, GPT-4, QWEN-1,5 и Llama показали сильную производительность, как предложенные, так и агрегирующие-в то время как некоторые (Wizardlm) были особенно лучше в качестве предложений, чем агрегаторы. MOA использует эти сильные стороны, назначая каждую модель для роли, в которой она превосходит.
Многослойное итеративное уточнение
MOA организует агенты в несколько слоев (подумайте об этом, как о небольшом трубопроводе моделей).
Рисунок 2иллюстрирует пример с 4 слоями и 3 агентами на слой. В слое 1,неАгенты -предложения независимо генерируют ответы на подсказку пользователя. Затем их выходы передаются на слой 2, где другой набор агентов (которые могут повторно использовать одни и те же модели или разные) видятвсеПредыдущие ответы в качестве дополнительного контекста. Таким образом, агенты каждого слоя имеют больше материала для работы - эффективно выполнятьитеративное уточнениеответа.
Этот процесс продолжается для нескольких слоев, и, наконец, агент агрегатора дает единый консолидированный ответ. Интуитивно, более ранние слои вносят вклад в идеи и частичные решения, в то время как более поздние слои объединяют и отполируют их. По окончательному слою ответ гораздо большевсеобъемлющий и надежныйчем любая попытка первой прохождения.
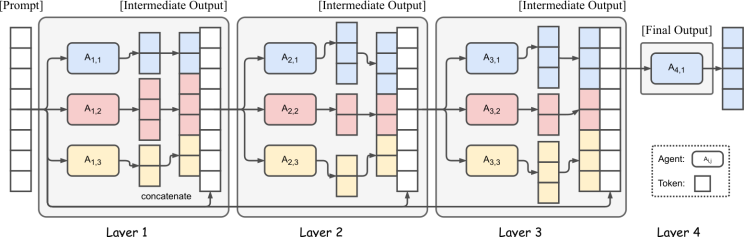
Рисунок 2: Архитектура смеси агентов (упрощена до 3 агентов × 4 слоя).
Предложения против агрегаторов на практике
Ключевым вопросом дизайна является то, как назначить модели на слои. Бумага MOA предлагает два критерия:
- (а) Производительность-Более сильные модели (более высокая одномодельная выигрыша) являются основными кандидатами для последующих слоев
- (б) разнообразие- Используйте сочетание типов моделей, чтобы каждый приносил что -то уникальное.
Фактически, они обнаружили, что неоднородные модели вносят свой вкладгораздо большечем клоны той же модели.
В реализации MOA последний слой часто имеет единственную лучшую модель, действующую в качестве агрегатора, тогда как более ранние слои могут быть заполнены разнообразным набором предложений. Интересно, что эксперименты показали, что многие лучшие модели могут хорошо выполнять обе роли, но некоторые из них гораздо сильнее в одной роли.
Например, Wizardlm (тонкий вариант Llama) преуспел как предложение, генерирующее творческие ответы, но боролся как агрегатор, чтобы объединить содержание других. GPT-4 (OPENAI) и QWEN-1,5 (Alibaba) были более универсальными, хорошо работали как агрегатор, так и заявитель.
Эти идеи могут направлять разработчиков выбрать соответствующее микс - например, использоватьМодель с открытым исходным кодом GPT-4 в качестве агрегатораи имеют специализированные меньшие модели предлагают ответы (возможно, модель, специфичная для кода, модель, специфичную для мышления и т. Д., В зависимости от домена запроса).
Бессмыслы: MOA превосходит GPT-4 (с только открытыми моделями)
Архитектура MOA была оценена по нескольким жестким показателям, и результаты поразительны. Использование только моделей с открытым исходным кодом (вообще без GPT-4), MOAсовпадают или битмогущественный GPT-4 в общем качестве.
Alpacaeval 2.0 (уровень победы с контролем длины)
- MOA с GPT-4O: 65,7%
- MOA (только с открытым исходным кодом): 65,1%
- MOA-Lite (оптимизированная): 59,3%
- GPT-4 Omni: 57,5%
- GPT-4 Turbo: 55,0%
Mt-Bench (Avg. Оценка)
- MOA с GPT-4O: 9.40
- MOA (открытый источник): 9.25
- GPT-4 Turbo: 9.31
- GPT-4 Omni: 9.19
Колба (оценка на основе навыков)-MOA превосходит GPT-4 Omni в:
- Надежность
- Правильность
- Фактическая
- Проницательность
- Полнота
- Метазознание
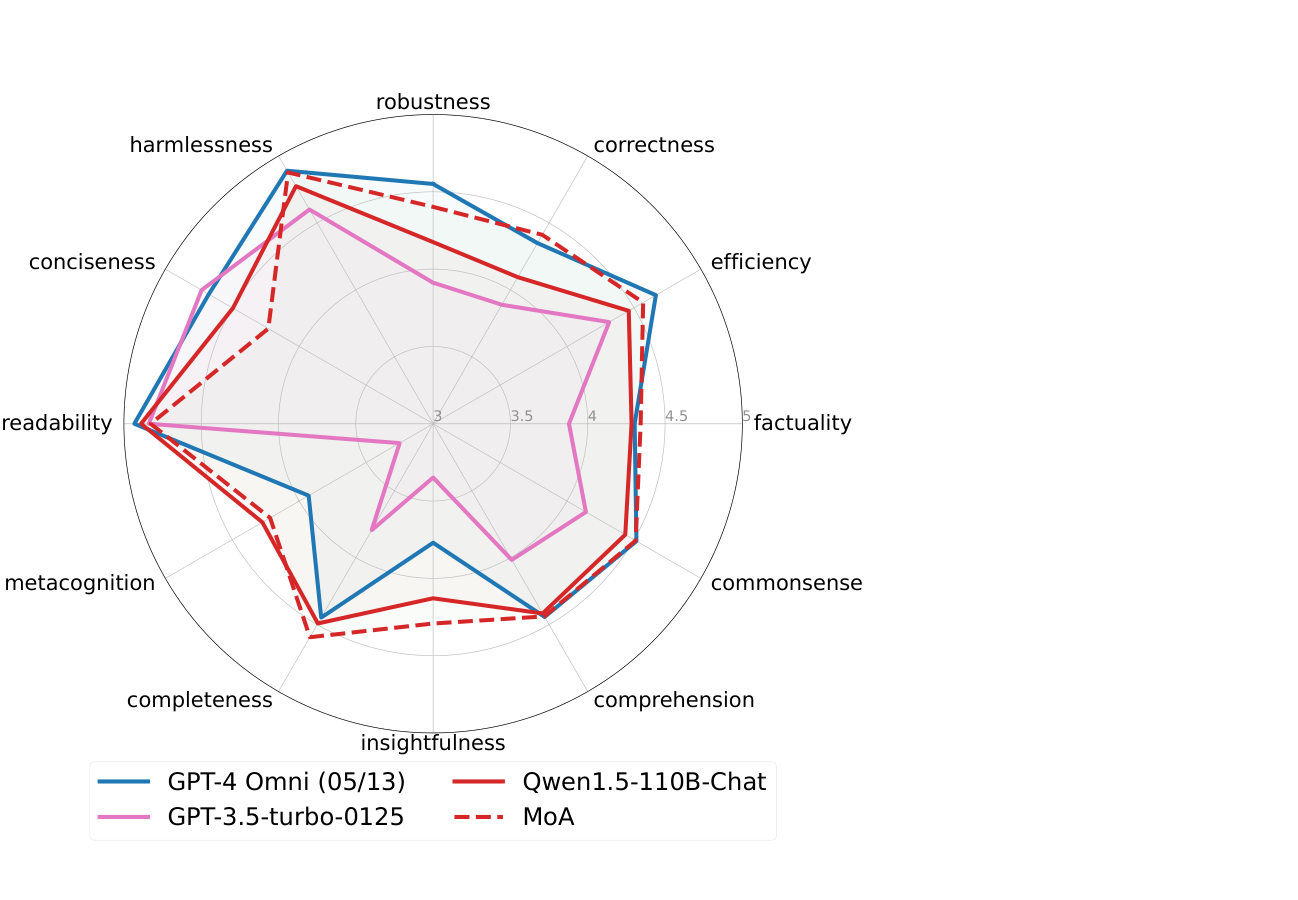
Рисунок 3: Рэд-карта мелкозернистого оценки (колба). MOA (красный пунктир) против GPT-4 (синий) по 12 размеров навыков. MOA превосходит GPT-4 по нескольким фронтам (например, фактической, проницательности), с легким штрафом на усмотрение (более низкая краткости). QWEN-110B (красное твердое вещество), когда только агрегатор MOA отслеживает несколько навыков, показывая многогранную синергию повышает общую производительность.
Важно подчеркнутьЭффективность MOA: Эти прибыли были достигнуты сОткрытые модели, которые коллективно намного дешевле, чем GPT-4Полем Например, одна конфигурация MOA использовала 6 открытых моделей (например, QWEN-110B, LLAMA-70B и т. Д.) На 3 уровнях, и все же стоила лишь доли использования API GPT-4.
Команда также разработала более легкий вариант под названиемMOA-Lite-Использование всего 2 слоя и меньшего агрегатора (QWEN-72B)-которыйвсе ещеслегка ударил gpt-4 Omni на альпакаэвале (59,3% против 57,5%), находясьболее рентабельныйПолем Другими словами, даже ослабленный MOA может превзойти качество GPT-4 по более низкой стоимости.
Как это возможно?
По сути, MOA проникает вМудрость толпысреди моделей. Каждый агент вносит уникальные сильные стороны - один может добавить знания, другой проверяет последовательность, другой улучшает формулировку. Окончательный результат выигрывает от всего их опыта.
Было проведено иллюстративное сравнение между MOA и наивнымLLM Ранка АнсамбльПолем Ранкер просто генерирует несколько ответов и будет иметь LLM (например, GPT-4 или QWEN) выбирать лучшее, не синтезируя их. Моазначительно превзошелтакой подход. Это подтверждает, что агрегатор MOA не просто выбирает один из входов; Это действительноОбъединениеИдеи (статья даже обнаружила, что ответ агрегатора имеет самое высокое совпадение с лучшими частями предложений, посредством корреляции бал -бал -бал). Сотрудничество, а не только выбор, является ключом.
Стоимость, гибкость и практические идеи
Для разработчиков основная привлекательность MOA - этоэкономическая эффективностьПолем Органируя меньшие открытые модели, вы можете достичь вывода на уровне GPT-4 без оплаты сборов API или запустив модель 175B-параметра для каждого запроса. Авторы MOA предоставляют подробный анализ затрат (см.Рисунок 5)
Конфигурации MOA лежат наПарето границакачества против стоимости-обеспечение высоких выигрышных ставокпри гораздо более низкой ценечем GPT-4. Например, один пробег MOA выпустил на 4% выше, чем GPT-4 Turbo, когда он был2 × дешевлеС точки зрения стоимости вывода.
Даже MOA-Lite (2 слоя) достиг такой же выигрышной ставки, что и gpt-4 Omni по эквивалентной стоимости, по существу сопоставлению GPT-4 качества на доллар, и фактически превзошел качество GPT-4 Turbo в половине стоимости. Это открывает дверь для бюджетных приложений: вы можете развернуть набор тонких настроенных открытых моделей 7B-70B, которые в совокупности соперничают или превзойдут закрытую модель 175B.
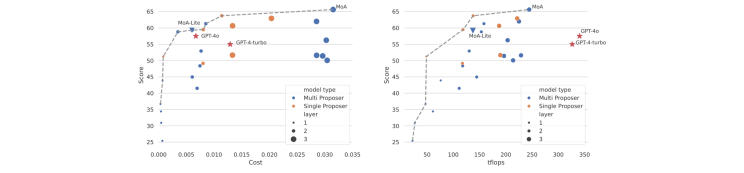
Рисунок 4: Производительность против стоимости и задержки.Левый:LC Win-Rate (качество) против API стоимость за запрос. MOA (синий/оранжевый точки вдоль пунктирной серой границы) достигает ~ 60–65% выигрыша по цене, намного ниже GPT-4 (Red Stars).Верно:Пропускная пропускная способность вывода против вывода (в TFLOPS, прокси для задержки). MOA снова находится на границе Pareto - комбинации более мелких моделей эффективно достигают высокого качества. «Одиночный предложение» использует одну модель для генерации нескольких ответов; «Multi Proposer» (MOA) использует разные модели на слое, что более эффективно вычислительно от параллельных агентов.
Еще одно преимущество - этоГибкостьПолем Поскольку MOA работает посредством подсказки, вы можете динамически масштабировать количество агентов или слоев на основе сложности запроса или доступных вычислений. Нужен быстрый, дешевый ответ? Запустите MOA-Lite с меньшим количеством агентов. Нужно максимально качество? Добавьте слой очень большого агрегатора (даже сам GPT-4 может быть использован в MOA в качестве конечного агрегатора для дальнейшего продвижения качества).
Структура позволяет вамMix и Match Open ModelsПока вы можете попросить их. Это также означает, что вы можете специализировать агенты: например, Добавьте LLM, специфичный для кода, в слое 1, чтобы предложить решение для кодирования, LLM, специфичный для математики, для проверки вычислений и т. Д., А агрегатор объединяет свои выходы. В абляциях статьи использование разнообразных типов моделей дало значительно лучшие ответы, чем однородные агенты - так разнообразие стоит использовать.
Советы по реализации
Авторы выпустили свой код MOA (приглашенные сценарии и конфигурации модели) на GitHub, что облегчает воспроизведение и адаптацию.https://github.com/togethercomputer/moa
Чтобы реализовать MOA, вы запускаете агенты каждого слоя параллельно (чтобы минимизировать задержку), собирать их результаты и кормить их (с помощью «агрегатной» системы) в агентах следующего слоя. Никакой точной настройки не требуется-просто тщательно быстрое инженерное проектирование.
Разумно использоватьКонтролируемая длина поколениеДля агентов (обеспечивая не слишком долго), чтобы придать агрегатору сбалансированные входные данные.
Кроме того, при выборе моделей для каждого уровня рассмотрите возможность использования самой сильной модели в качестве окончательного агрегатора (поскольку он должен вывести окончательный ответ) и более мелкие/более разнообразные модели в качестве предложений в более ранних слоях. В качестве агрегатора в качестве агрегатора в качестве агрегатора в качестве агрегатора использовалось 6 агентов на слое: QWEN-110B, а также смесь QWEN-72B, Wizardlm 22B, LlaMa-3 70B, Mixtral 22B и MPT (DBRX). Эта смесь была выбрана для сильной базовой производительности и неоднородности.
Заключение
Глядя в будущее,Смесь агентовуказывает на новый способ создания систем ИИ. Вместо того, чтобы полагаться на одну огромную универсальную модель, мы можем создатьКоманда специализированных моделейЭто работает вместе на естественном языке. Это похоже на то, как работают человеческие команды. Например, в медицинской обстановке:
- Один агент может предложить возможные диагнозы.
- Другой мог проверить результаты в отношении медицинских баз данных.
- Третий (агрегатор) объединит все в окончательную рекомендацию.
Этиагентские экосистемычасто большекрепкийипрозрачныйПолем Вы можете отслеживать вклад каждого агента, облегчая понимание и доверять окончательному выводу.
Исследования показывают, что даже сегодняшние модели, без дополнительного обучения, могутэффективно сотрудничатьПолем Когда они это делают, они могут превышать производительность любой модели, работающей в одиночку.
Для производства AI, MOA предлагаетПрактический, экономичный путьк качеству уровня GPT-4 путем объединения открытых моделей вместо того, чтобы платить за одну крупную, проприетарную модель.
Поскольку LLM с открытым исходным кодом продолжают улучшаться, архитектуры в стиле MOA, вероятно, станут нормой-качество масштабирования за счет сотрудничества, а не размераПолем Эпоха«LLMS как командные игроки»только начинается.
Ключевые выводы
- MOA повышает качество за счет сотрудничества- Несколько LLMS обмениваются и уточняют выходы друг друга, даже когда некоторые входные данные слабее, используя эффект «совместной работы».
- Многослойная утонченность-Каждый слой агентов видит предыдущие выходы и исходную подсказку, обеспечивая пошаговое улучшение.
- Проверенный эталонный прирост- превосходить более дорогостоящие модели
- Рентабельный-Сопоставления или бит качества GPT-4 с использованием более дешевых открытых моделей; MOA-Lite предлагает сильные результаты с более низким вычислением.
- Гибкость- Легко обмениваться специализированными моделями для доменных задач или настраивать слои для скорости и качества.
- Готово к будущему-представляет собой сдвиг в сторону многоагентных систем ИИ, которые напоминают команды экспертов, потенциально становятся стандартным подходом для развертывания LLM производственного уровня.
Ссылки:Архитектура смеси агентов была введена вWang et al., 2024(Arxiv: 2406.04692).https://arxiv.org/pdf/2406.04692
Оригинал