
Ограничения Лоры в кодовых и математических задачах
17 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
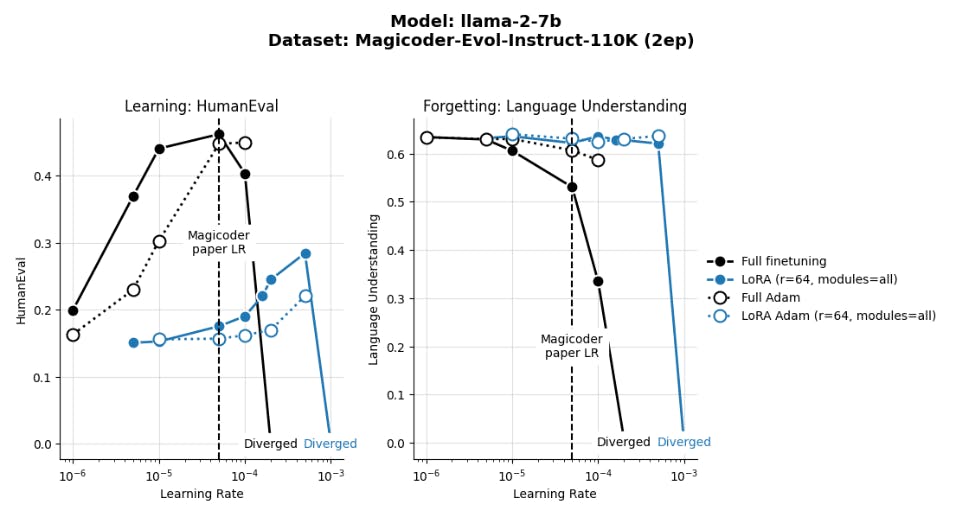
4 Результаты
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
5 Связанная работа
Расширения на ЛоруЛора вдохновила многие варианты и расширения, которые являются более эффективными или эффективными для памяти, такие как Qlora (Dettmers et al., 2024), Vera (Kopiczko et al., 2023), Dora (Liu et al., 2024), цепь Lora (Xia et al., 2024) и в горобийстве (Zhao et al., As Effective), а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также, а также. Техники, построенные на Лоре, такие как S-Lora (Sheng et al., 2023).
Брингеринг Lora vs. Full MenetuningОригинальное исследование LORA от Hu et al. (2021) сообщили, что Лора совпала с полной производительностью для Роберты (Liu et al., 2019) о Glue (Wang et al., 2018) и GPT-2 на e2e nlg Challenge (Novikova et al., 2017) и GPT-3 на Wikisql (Zhong et al., 2017), Mnli (Williams at al., 2017), и 2017), и 2017), и 2017), и 2017), и 2017), и 2017), и др. et al., 2019). Многие последующие исследования следуют этому шаблону и сообщают о производительности модели Encoder по задачам в клеях, таких как SST-2 (Socher et al., 2013) и MNLI (Williams et al., 2017). Однако такие модели, как Роберта, составляют менее 340 млн. Параметров, а такие задачи классификации, как MNLI, довольно тривиальны для современных миллиардов LLM, таких как Llama-2-7B. Несмотря на популярность Лоры, лишь несколько исследований строго сравнивали LORA с полным созданием в этой ситуации и с сложными областями, такими как код и математика. Dettmers et al. (2024), например, обнаружил, что Qlora совпадает с полной компанией MMLU (Hendrycks et al., 2020) при создании Llama-1 7b, 13b, 33b и 65b на Alpaca (Taori et al., 2023) и Flan (Chung et al., 2024). Ivison et al. (2023), с другой стороны, обнаружили, что Qlora работала не так же хорошо, как в моделях Llama-2-7B, 13B и 70B, обученных набору данных Tülü-2, когда оценивается по всему набору задач, включая MMLU, GSM8K, Alpacaeval (который использует LLM-as-a-Judge; Одним из недавних заметных исследований является Astraios, которое обнаружило, что LORA работала хуже, чем полное создание на 8 наборах данных и в 4 размерах модели (до 16 миллиардов параметров), на 5 репрезентативных задачах кода (Zhuo et al., 2024). Наше исследование подтверждает эти результаты.
Выводы также были смешаны в отношении практических деталей, связанных с целевыми модулями LORA и ранга: Рашка (2023) и Dettmers et al. (2024) показывают, что оптимизированные конфигурации LORA работают так же, как и полное создание, и эта производительность регулируется выбором целевых модулей, но не ранга. Напротив, Liu et al. (2024) показывает, что Лора чувствительна к ряду. Вполне вероятно, что некоторые из этих расхождений обусловлены различиями в наборах данных и оценках создания и оценок.
Учебные компромиссыНепрерывное обучение на новой целевой области часто происходит за счет производительности в исходной области (Lesort et al., 2020; Wang et al., 2024). Соответствующим примером является то, что LLM-кодовые финеты теряют некоторые из своих возможностей в понимании языка и здравом рассуждении (Li et al., 2023; Roziere et al., 2023; Wei et al., 2023). Общий подход к смягчению забывания включает в себя «воспроизведение» данных исходной области во время непрерывного обучения, которые можно выполнить путем хранения данных в буфере памяти или генерации их на лету (Lesort et al., 2022; Scialom et al., 2022; Sun et al., 2019).
Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Эта статья есть
Оригинал