
Лора учится меньше и забывает меньше - это ошибка или функция?
17 июня 2025 г.Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
4 Результаты
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
Абстрактный
Адаптация с низким уровнем ранга (LORA) является широко используемым параметром, эффективным для параметров для крупных языковых моделей. Лора сохраняет память, тренируя только возмущения низкого ранга к выбранным матрицам веса. В этой работе мы сравниваем производительность LORA и полного создания в двух целевых областях, программировании и математике. Мы рассматриваем как пары инструкций (≈100K, пары оперативного ответа), так и постоянные предварительные (≈10b неструктурированные токены) режимы данных. Наши результаты показывают, что в большинстве настройки Лора значительно снижает полное создание. Тем не менее, Лора демонстрирует желательную форму регуляризации: она лучше поддерживает производительность базовой модели по задачам за пределами целевой области. Мы показываем, что Лора обеспечивает более сильную регуляризацию по сравнению с общими методами, такими как распад веса и отсечение; Это также помогает поддерживать более разнообразные поколения. Мы показываем, что полная производительность изучает возмущения с рангом, который на 10-100x больше, чем типичные конфигурации LORA, возможно, объясняя некоторые из сообщенных пробелов. Мы заключаем, предлагая лучшие практики для создания с Лорой.
1 Введение
Создание больших языковых моделей (LLMS) с миллиардами весов требует нетривиального количества памяти графических процессоров. Параметр-эффективные методы создания сконструирования уменьшают присутствие памяти во время обучения, замораживая предварительно подготовленный LLM и только обучая небольшое количество дополнительных параметров, часто называемых адаптерами. Адаптация с низким уровнем ранга (Lora; Hu et al. (2021)) адаптеры поезда, которые представляют собой возмущения с низким уровнем ранга к выбранным матрицам веса.
С момента своего введения Лора рекламировалась как строгое повышение эффективности, которое не ставит под угрозу точность нового целевого домена (Hu et al., 2021; Dettmers et al., 2024; Raschka, 2023; Zhao et al., 2024b). Тем не менее, только горстка исследований сравнивает Лору против полного создания для LLMS с миллиардами параметров (Avison et al., 2023; Zhuo et al., 2024; Dettmers et al., 2024), сообщив о смешанных результатах. Некоторые из этих исследований полагаются на более старые модели (например, Роберта) или грубые оценки оценки (такие как клей или руга), которые менее актуальны для современных LLM. Напротив, более чувствительные доменные оценки, например, код, выявляют случаи, когда Lora уступает полным созданию (Ivison et al., 2023; Zhuo et al., 2024).Здесь мы спрашиваем: в каких условиях Лора приближает полную точность создания в сложных целевых областях, таких как код и математика?
Обучая меньше параметров, предполагается, что Лора обеспечивает форму регуляризации, которая ограничивает поведение созданной модели, оставаясь близкой к поведению базовой модели (Sun et al., 2023; Du et al., 2024).Мы также спрашиваем: действует ли Лора как регулятор, который смягчает «забывание» исходного домена?
В этом исследовании мы строго сравниваем LORA и полную технологию для моделей LLAMA-2 7B (а в некоторых случаях, 13B) в двух сложных целевых областях, коде и математике. В каждом домене мы исследуем два режима обучения. Первым является то, что обучение инструкции, общий сценарий для Лоры, включающий наборы данных с ответами на вопросы с десятками до сотен миллионов токенов. Здесь мы используем Magicoder-Evol-Instruct-110K (Wei et al., 2023) и Metamathqa (Yu et al., 2023). Второй режим продолжается предварительно подготовленным, менее распространенное применение для LORA, которое включает в себя обучение на миллиарды немелочных токенов; Здесь мы используем наборы данных StarCoder-Python (Li et al., 2023) и OpenWebmath (Paster et al., 2023) (Таблица 1).
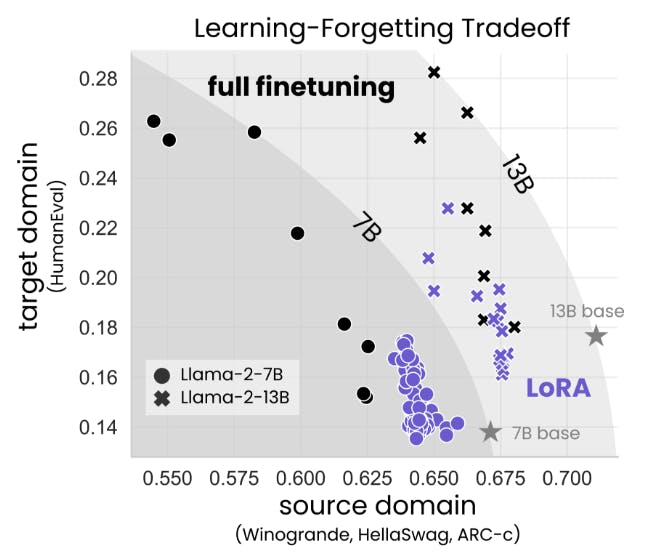
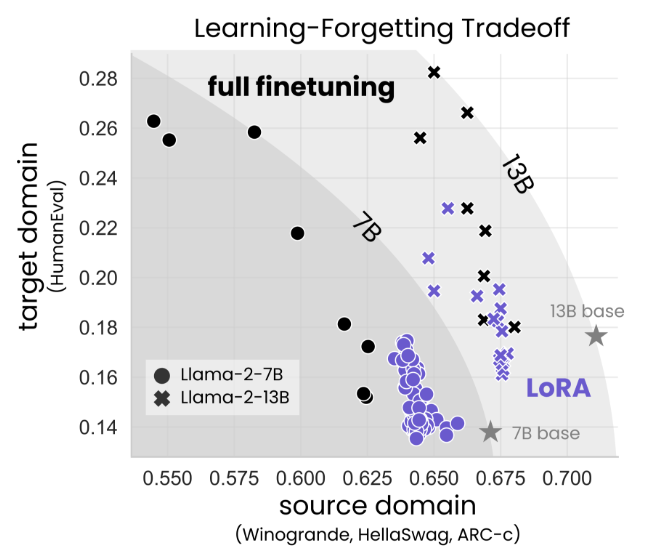
Мы оцениваем производительность целевой домены (отныне, обучение) посредством сложного кодирования и математических показателей (Humaneval; Chen et al. (2021) и GSM8K; Cobbe et al. (2021)). Мы оцениваем источник-домен, забывая о результатах понимания языка, мировых знаний и разумных задач здравого смысла (Zellers et al., 2019; Sakaguchi et al., 2019; Clark et al., 2018).
Мы обнаруживаем, что для кода Лора существенно снижает полную производительность, тогда как для математики Лора закрывает больше разрыва (г. 4.1), в то же время требуя более длительного обучения. Несмотря на этот разрыв в производительности, мы показываем, что Lora лучше поддерживает производительность исходного домена по сравнению с полным искусством (раздел 4.2). Кроме того, мы характеризуем компромисс между производительностью в целевой и исходной области (обучение в зависимости от забывания). Для данного размера модели и набора данных мы обнаруживаем, что Lora и Full Menetuning образуют аналогичную кривую компромисса, создающую обучение: Lora, которые учатся в целом, забывают столько же, сколько и полное создание, хотя мы находим случаи (для кода), где Лора может учиться сравнительно, но меньше забывает (Sec. 4.3).
Затем мы показываем, что Лора - даже с менее ограничительным рангом - обеспечивает более сильную регуляризацию по сравнению с классическими методами регуляризации, такими как отсечение (Srivastava et al., 2014) и распад веса (Goodfellow et al., 2016). Мы также показываем, что LORA обеспечивает регуляризацию на уровне вывода: мы анализируем сгенерированные решения проблем гуманевирования и обнаруживаем, что, хотя полная конфигурация падает с ограниченным набором решений, Лора сохраняет разнообразие решений, более похожих на базовую модель (Sun et al., 2023; Du et al., 2024).
Почему Лора ухудшается полное создание? Первоначально Лора была частично мотивирована гипотезой о том, что создание приводит к низководному возмущениям к матрице веса базовой модели (Li et al., 2018; Aghajanyan et al., 2020; Hu et al., 2021). Тем не менее, задачи, изученные этими работами, относительно просты для современных LLM и, безусловно, проще, чем изучаемые здесь домены кодирования и математики. Таким образом, мы выполняем единичное разложение значений, чтобы показать, что полное создание, едва изменяя спектр матриц веса базовой модели, и все же разница между двумя (то есть возмущение) является высоким рангом. Ранг возмущения растет по мере продвижения тренировок, с рядами на 10-100 × выше, чем типичные конфигурации LORA (рис. 7).
Мы заключаем, предлагая лучшие практики для тренировочных моделей с Лорой. Мы находим, что Лора особенно чувствительна к ставкам обучения, и что на производительность влияет в основном выбор целевых модулей и в меньшей степени по рангу.
Подводя итог, мы внесем следующие результаты:
• Полное создание, более точное и эффективное, чем Лора, в коде и математике (Sec.4.1).
• Лора забывает меньше исходного домена, обеспечивая форму регуляризации (г. 4.2 и 4.3).
• Ретализация Лоры сильнее по сравнению с обычными методами регуляризации; Это также помогает поддерживать разнообразие поколений (г. 4.4).
• Полное создание находит возмущения высокого веса (раздел 4.5).

• По сравнению с полным созданием, Лора более чувствительна к гиперпараметрам, а именно: скорость обучения, целевые модули и ранжирование (в порядке уменьшения; раздела 4.6).
2 фон

Эта статья есть
Оригинал