
Логовая и искусство семантической анимации
16 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
2.1 Синтез программы
2.2 Инструменты поддержки творчества для анимации
2.3 Денежные инструменты для проектирования
3 Формирующие шаги
4 Система логовой и 4.1 вход
4.2 Предварительная визуальная информация
4.3 Визуально обоснованный синтез кода
5 Оценки
5.1 Оценка: ремонт программы
5.2 Методология
5.3 Выводы
6 Оценка с новичками
7 Обсуждение и 7.1. Отрываны от шаблонов
7.2 Создание кода вокруг визуальных эффектов
7.3 Ограничения
8 Заключение и ссылки
2.3 Денежные инструменты для проектирования
Генеративные технологии ИИ популяризировали естественный язык как новую форму взаимодействия для создания контента. LLMS [19] показали перспективу в поддержке мозгового штурма [44], сценарию и письменной помощи [29, 59, 61] и чувствительности [55]. Модели текста к изображению [14, 15, 50, 51] показали, что они эффективны в генерации визуальных активов для визуального смешивания [28], новостной иллюстрации [44], Расскармингах [59], дизайну продукта [45], World Building [24] и генерации видео [43]. Генеративные технологии также начали применяться к дизайну движения и анимации [31, 43].
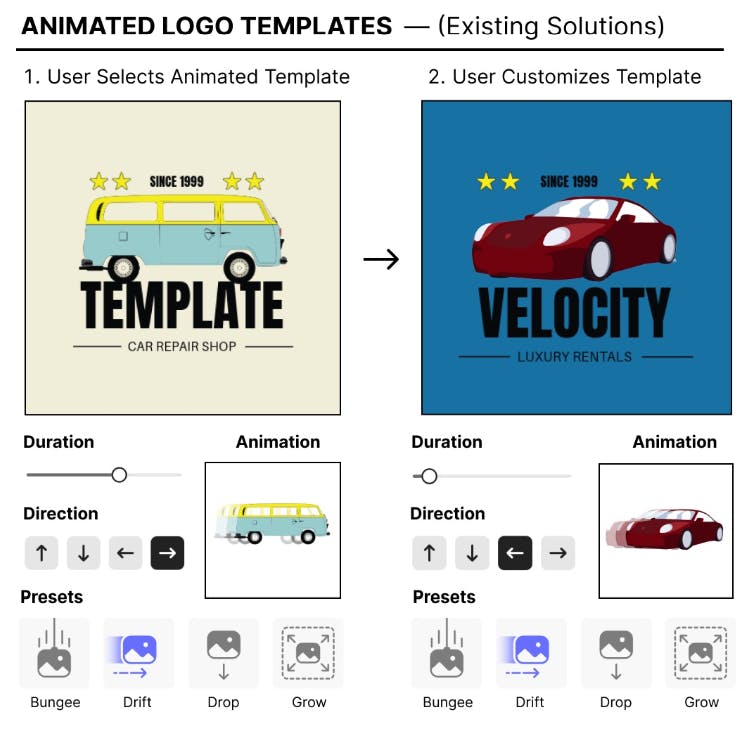
Ближайшая генеративная работа для нашего - это KeyFramer, исследование того, как начинающие и экспертные дизайнеры предпринимают GPT для анимации. Основным выводом является то, что 84% подсказок носили семантический характер - пользователи хотели описать направления высокого уровня, такие как «сделать облака покачиваться» чаще, чем подсказки низкого уровня, такие как изменение непрозрачности. Это ясно показывает, что люди хотят семантически значимых анимаций - движения, которые характеризуют, как этот элемент может двигаться в реальной жизни.
Логовая изучает аналогичную проблему (анимирование цифровых макетов, но в домене логотипа), и мы также используем LLMS для синтеза кода. Тем не менее, мы строим в этом направлении, внедряя трубопровод, который выполняет синтез кода и ремонт программы в визуально. Кейффрамер сгенерированный код анимации без использования визуального контекста из холста и не имел меньшей встроенной поддержки
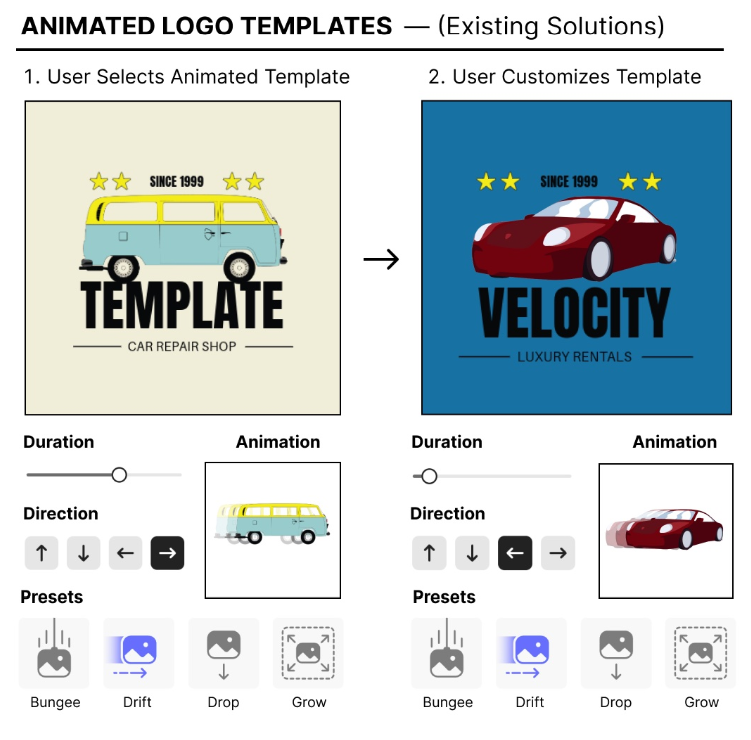
Для группировки и сроков дизайна элементов. Предварительная обработка и понимание изображений, реализованные в логовой, помогают ему придумать сложные концепции дизайна, которые указывают моменты героя для первичного элемента и обрабатывают секвенирование других элементов дизайна (например, синхронизированные вторичные элементы, текстовая анимация). Кроме того, мы сравниваем наш подход с современными базовыми показателями и демонстрируем значительное улучшение в сохранении.
Авторы:
(1) Вивиан Лю, Колумбийский университет (vivian@cs.columbia.edu);
(2) Rubaiat Habib Kazi, Adobe Research (rhabib@adobe.com);
(3) Li-Yi Wei, Adobe Research (lwei@adobe.com);
(4) Мэтью Фишер, Adobe Research (matfishe@adobe.com);
(5) Тимоти Ланглуа, Adobe Research (tlangloi@adobe.com);
(6) Сет Уокер, Adobe Research (swalker@adobe.com);
(7) Лидия Чилтон, Колумбийский университет (chilton@cs.columbia.edu).
Эта статья есть
Оригинал