

Обучение LLM Гиперпараметры: подробный обзор
11 июня 2025 г.Таблица ссылок
Аннотация и 1. Введение
2. Метод
3. Эксперименты по реальным данным
3.1. Шкала преимуществ с размером модели и 3,2. Более быстрый вывод
3.3. Изучение глобальных моделей с помощью мульти-байтового прогноза и 3.4. Поиск оптимальногоне
3.5. Обучение для нескольких эпох и 3.6. Создание нескольких предикторов
3.7 Многократный прогноз на естественном языке
4. Абляции на синтетических данных и 4.1. Индукционная способность
4.2. Алгоритмические рассуждения
5. Почему это работает? Некоторые спекуляции и 5.1. Lookahead Укрепляет очки выбора
5.2. Информация теоретичный аргумент
6. Связанная работа
7. Заключение, Заявление о воздействии, воздействие на окружающую среду, подтверждения и ссылки
A. Дополнительные результаты по самопрокативному декодированию
Б. Альтернативные архитектуры
C. Скорость тренировок
D. МАГАЗИН
E. Дополнительные результаты по поведению масштабирования модели
F. Подробности о CodeContests Manetuning
G. Дополнительные результаты по сравнению с естественным языком
H. Дополнительные результаты по абстрактному текстовому суммированию
I. Дополнительные результаты по математическим рассуждениям на естественном языке
J. Дополнительные результаты по индукционному обучению
K. Дополнительные результаты по алгоритмическим рассуждениям
L. Дополнительные интуиции по многоцелевым прогнозам
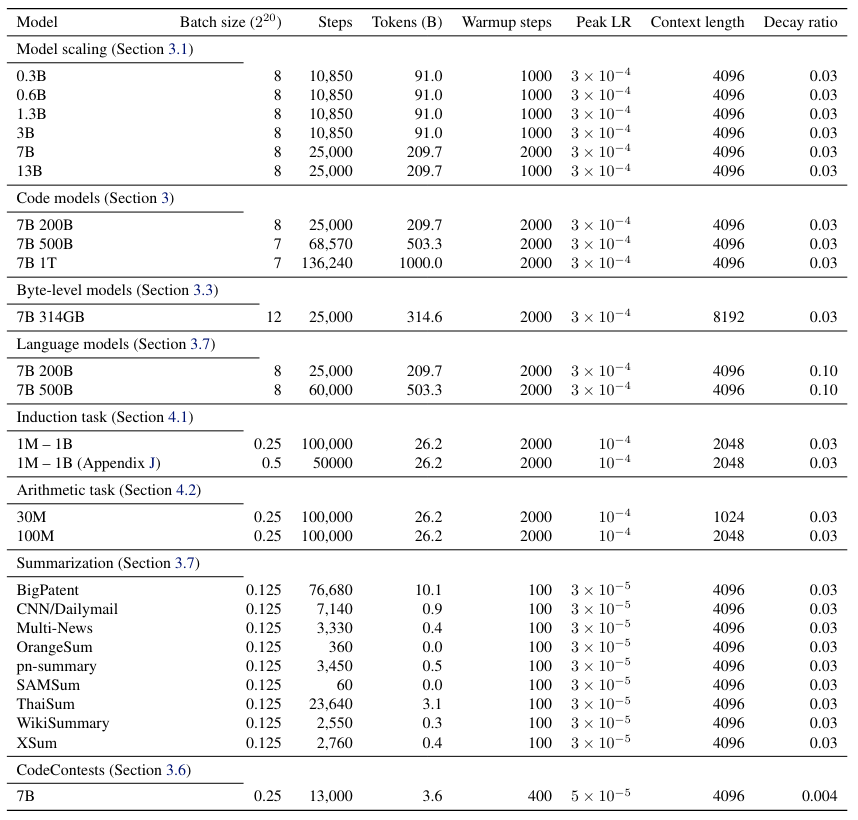
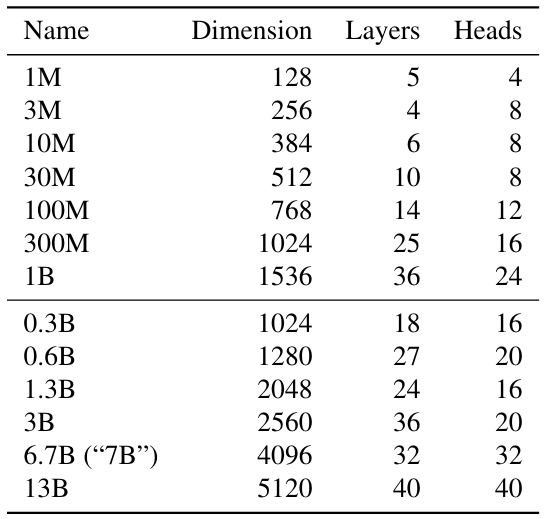
М. Обучение гиперпараметры
М. Обучение гиперпараметры
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Фабиан Глокл, ярмарка в Meta, Cermics Ecole des Ponts Paristech и внес свой вклад;
(2) Badr Youbi Idrissifair в Meta, Lisn Université Paris-Saclay и внес свой вклад;
(3) Baptiste Rozière, ярмарка в Meta;
(4) Дэвид Лопес-Паз, ярмарка в Мете и его последний автор;
(5) Габриэль Синнев, ярмарка в Meta и последний автор.
Оригинал