
«Пусть это виляет!» И границы машинного обучения на редких концепциях
9 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2 концепции в предварительных данных и количественная частота
3 Сравнение производительности предварительного подготовки и «нулевого выстрела» и 3.1 Экспериментальная установка
3.2
4 Тестирование стресса Концепция тенденции масштабирования частоты и 4.1.
4.2 Тестирование обобщения на чисто синтетическую концепцию и распределения данных
5 Дополнительные идеи от частот концепции предварительного подготовки
6 Проверка хвоста: пусть он виляет!
7 Связанная работа
8 Выводы и открытые проблемы, подтверждения и ссылки
Часть я
Приложение
A. Частота концепции является прогнозирующей производительности в разных стратегиях
B. Частота концепции является прогнозирующей производительности в результате получения метриков извлечения
C. Частота концепции является прогнозирующей производительности для моделей T2I
D. Концепция частота является прогнозирующей производительности в разных концепциях только из изображений и текстовых областей
E. Экспериментальные детали
F. Почему и как мы используем Ram ++?
G. Подробная информация о результатах степени смещения
H. T2I Модели: оценка
I. Результаты классификации: пусть это виляет!
6 Проверка хвоста:Пусть это виляет!
МотивацияПолем Из предыдущих разделов мы определили последовательное распределение концепции с длинным хвостом, подчеркивая нехватку определенных концепций в Интернете. Это наблюдение является основой нашей гипотезы о том, что модели, вероятно, находятся в состоянии протестирования при тестировании на распределения данных, которые сильно длинные. Чтобы проверить это, мы тщательно курируем концепции 290, которые были идентифицированы как наименее частые во всех наборах данных. Это включает в себя такие концепции, как самолет A310, червяхнак и тропический король. Затем мы используем эти концепции для создания классификационного набора тестов,«Пусть это виляет!».
Детали набора данных.А«Пусть это виляет!»Набор данных классификации включает в себя 130K -тестовые образцы, загруженные из Интернета с использованием метода Prabhu et al. [90]. Испытательные образцы равномерно распределены по 290 категориям, которые представляют длиннохвостые понятия. Из списка кураторских концепций мы загружаем изображения тестовых наборов, дедупликаем их, удаляем выбросы и, наконец, вручную очищаем и проверяем этикетки.
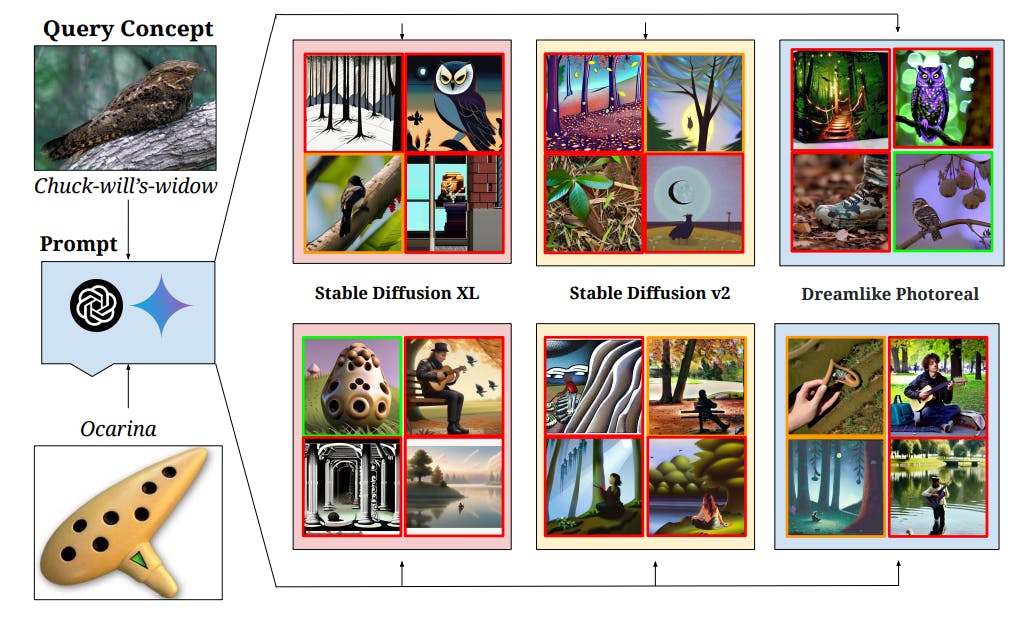
![Figure 7: Qualitative results on the “Let It Wag!” dataset categories demonstrate failure cases of state-of-the-art T2I models on long-tailed concepts. In our experiments, we create 4 text prompts for each category using Gemini [112] and GPT4 [12] which are fed to 3 Stable Diffusion [96] models. Generation with red border is incorrect, with green border is correct and with yellow border is ambiguous. We observe that despite advances in high-fidelity image generation, there is scope for improvement for such concepts.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-sh832c5.png)
Анализ детали.Мы проводили эксперименты как классификация, так и генерация«Пусть это виляет!».Для классификации мы оценили производительность 40 моделей текстового изображения (CLIP) на«Пусть это виляет!»Набор данных классификации, используя ансамбль из 80 подсказок от Radford et al. [91]. Для генеративной задачи мы использовали SD-XL [89], SD-V2 [96] и Dreamlie-Photoreal-V2.0 [3] для генерации изображений для длиннохвостовых концепций. Для каждой модели мы выполняли 50 шагов диффузии, поддерживая настройки по умолчанию для всех других параметров.
Результаты классификации текстового изображения.Мы демонстрируем результаты нашей задачи классификации с длинной хвостами на рис. 6-мы планируем результаты всех моделей на обеих«Пусть это виляет!»(ось Y) и ImageNet (ось X). Мы отмечаем, что все модели находятся под отставкой на больших полях на длиннохвостых«Пусть это виляет!»Набор данных (до 20% более низкой абсолютной точности по сравнению с ImageNet). Этот снижение производительности обобщается во всех масштабах моделей и 10 различных распределений данных предварительного подготовки, усиливая представление о том, что все наборы данных предварительных данных в Интернете по своей природе ограничены длиннохвостыми. С учетом сказанного обратите внимание, что модели более высокой емкости (установленная линия с наклоном = 1,58 на рис. 6), по-видимому, закрывают разрыв к производительности ImageNet, что указывает на улучшенную производительность на длиннохвостых концепциях.
Результаты генерации T2I.Мы предоставляем качественный анализ генерации изображений для оценки моделей T2I на редких концепциях на рис. 7. Для разнообразия мы генерируем подсказки с использованием Gemini [112] (верхний ряд сгенерированных изображений) и GPT4 [12] (нижний ряд сгенерированных изображений). Зеленые границы представляют правильные поколения, красные границы представляют собой неправильные поколения, а желтые границы представляют собой неоднозначную генерацию. Хотя описательное подсказка, как правило, помогает улучшить качество генерируемых изображений [52], мы все еще наблюдаем, как модели T2I не понимают, и точно представляют много концепций в наших«Пусть это виляет!»набор данных. Некоторые случаи сбоев включают в себя искажение действий (например, бросок пиццы или боулинг по крикету, как показано на рис. 24), создавая неправильную концепцию (Чак-Уиллс-Видоу, как показано на рис. 7 Вверху), а также вообще не понимая концепцию (Ocarina на рис. 7). Мы видим, что стабильные диффузионные модели качественно подвержены длинному хвосту - мы также даем количественные результаты в APPX. H.1.
ЗаключениеПолем Как в экспериментах как классификации, так и в генерации мы продемонстрировали, что современные мультимодальные модели, как и ожидалось, не соответствуют, независимо от их масштаба моделей или предварительных наборов данных. Это предполагает необходимость лучших стратегий для эффективного обучения на выборке на длинном хвосте.
Авторы:
(1) Вишаал Удандарао, Центр ИИ Тубингена, Университет Табингингена, Кембриджский университет и равный вклад;
(2) Ameya Prabhu, Центр AI Tubingen, Университет Табингинга, Оксфордский университет и равный вклад;
(3) Адхирадж Гош, Центр ИИ Тубинген, Университет Тубингена;
(4) Яш Шарма, Центр ИИ Тубинген, Университет Тубингена;
(5) Филипп Х.С. Торр, Оксфордский университет;
(6) Адель Биби, Оксфордский университет;
(7) Сэмюэль Албани, Кембриджский университет и равные консультирование, приказ, определенный с помощью монеты;
(8) Матиас Бетге, Центр ИИ Тубинген, Университет Тубингена и равные консультирование, Орден определяется с помощью переворачивания монеты.
Эта статья есть
Оригинал