
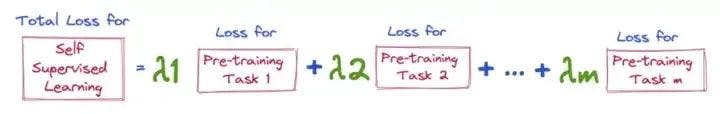
Моделирование языка — обзор наиболее распространенных задач перед обучением
14 января 2023 г.Самоконтролируемое обучение (SSL) является основой предварительно обученных языковых моделей на основе преобразователя, и эта парадигма включает в себя решение задач предварительного обучения (PT), которые помогают в моделировании естественного языка. В этой статье собраны вместе все популярные задания перед тренировкой, чтобы мы могли их оценить с первого взгляда.
Функция потери в SSL
Функция потерь здесь представляет собой просто взвешенную сумму потерь отдельных задач предварительной подготовки, на которых обучается модель.
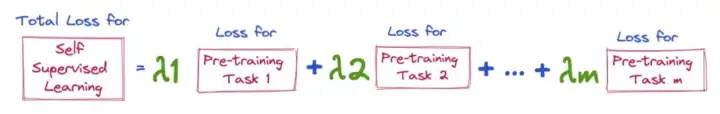
Взяв в качестве примера BERT, потеря будет равна взвешенной сумме MLM (моделирование маскированного языка) и NSP (прогнозирование следующего предложения)
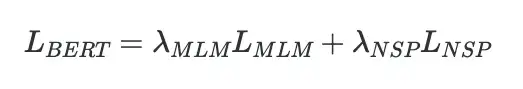
За прошедшие годы появилось много предтренировочных задач, которые придумали для решения конкретных задач. Мы рассмотрим 10 интересных и популярных из них вместе с соответствующими функциями потерь:
- Моделирование каузального языка (CLM)
- Моделирование маскированного языка (MLM)
- Заменено обнаружение токена (RTD)
- Обнаружение перемешанного токена (STD)
- Случайная замена токена (RTS)
- Моделирование с перестановкой языков (SLM)
- Моделирование языка перевода (TLM)
- Моделирование на альтернативном языке (ALM)
- Цель границы предложения (SBO)
- Предсказание следующего предложения (NSP)
(Функции потерь для каждой задачи и содержание в значительной степени заимствованы из AMMUS: обзор трансформеров на основе Предварительно обученные модели в обработке естественного языка)

* Это просто однонаправленная языковая модель, которая предсказывает следующее слово с учетом контекста. *Использовалось как предтренировочное задание в ОФТ-1 * Убыток для CLM определяется как:
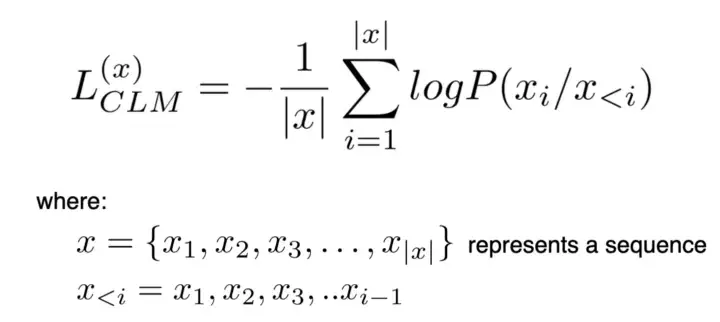

* Улучшение по сравнению с каузально-языковым моделированием (CLM), поскольку CLM учитывает только однонаправленный контекст при прогнозировании текста, тогда как MLM использует двунаправленный контекст. * Впервые оно использовалось в качестве предтренировочного задания в BERT
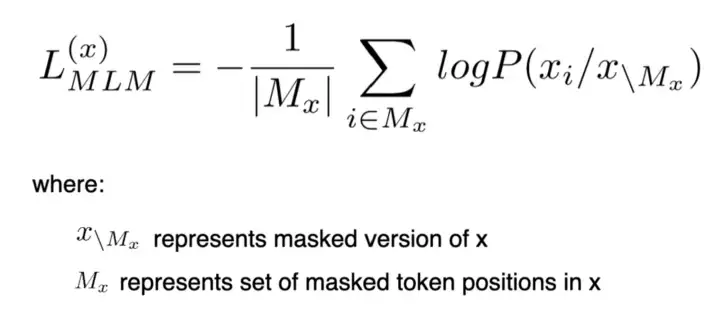

- Вместо того, чтобы маскировать токены с помощью [MASK], RTD заменяет токен другим токеном (используя модель генератора) и обучает модель классифицировать, являются ли данные токены фактическими или замененными токенами (используя модель дискриминатора)
- Устраняет два из следующих недостатков MLM:
Недостаток 1:
Токен [MASK] появляется во время предварительного обучения, но не во время тонкой настройки — это создает несоответствие между двумя сценариями. RTD преодолевает это, поскольку не использует маскировку
Недостаток 2:
В MLM обучающий сигнал дается только 15% токенов, поскольку потери вычисляются только с использованием этих замаскированных токенов, но в RTD сигнал дается всеми токенами, поскольку каждый из них классифицируется как « заменено» или «оригинал»
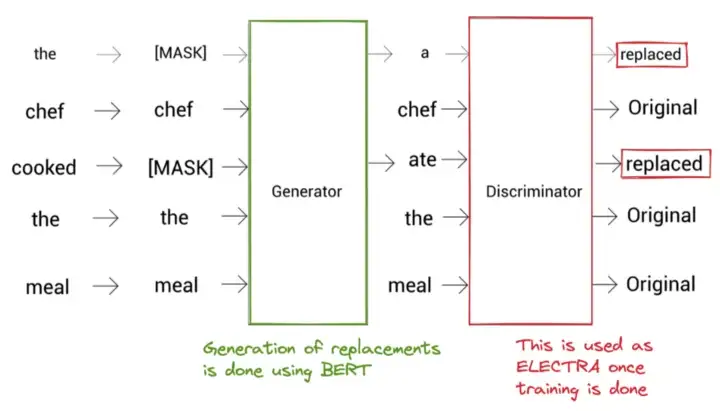
* RTD использовался в ELECTRA в качестве предтренировочного задания. Архитектура ELECTRA показана ниже:
Архитектура ЭЛЕКТРА


- Аналогично RTD, но токены здесь классифицируются как перемешанные или нет, а не замененные или нет (показано ниже)
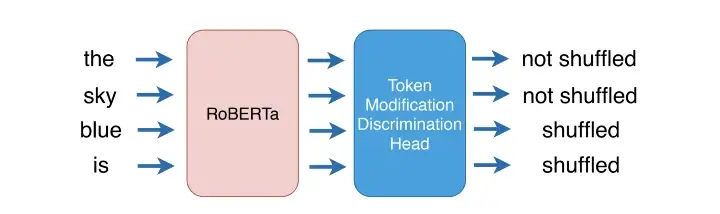
* Достигается такая же эффективность выборки, как и в RTD, по сравнению с MLM * Убыток определяется как:

 * RTD использует генератор для искажения предложения, что требует значительных вычислительных ресурсов.
* RTS обходит эту сложность, просто заменяя 15% токенов, используя токены из словаря, достигая такой же точности, как MLM, как показано здесь.
*
* RTD использует генератор для искажения предложения, что требует значительных вычислительных ресурсов.
* RTS обходит эту сложность, просто заменяя 15% токенов, используя токены из словаря, достигая такой же точности, как MLM, как показано здесь.
* 

- SLM искажает последовательность, заменяя 15% маркеров случайными маркерами.
- Это похоже на MLM с точки зрения попытки предсказать поврежденные токены, но вместо использования [MASK] для маскировки используются случайные токены
- Он похож на RTS с точки зрения использования случайных токенов для искажения, но, в отличие от RTS, неэффективен с точки зрения выборки, поскольку только 15 % токенов используются для предоставления обучающего сигнала.


- TLM также известен как межъязыковой MLM, в котором входные данные представляют собой пару параллельных предложений (предложений из двух разных языков) с токенами, замаскированными, как в MLM.
- Он использовался в качестве предварительного задания в XLM, межъязыковой модели для изучения межъязыкового сопоставления.
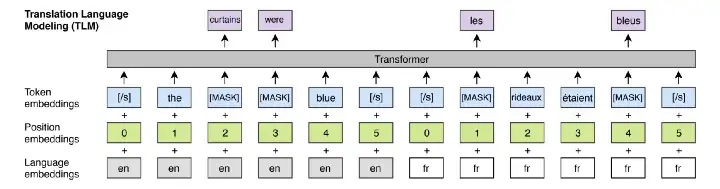
* Потеря TLM аналогична потере MLM:


- Изучить межъязыковую языковую модель, аналогичную TLM, где параллельные предложения переключаются кодом, – это задача, как показано ниже:
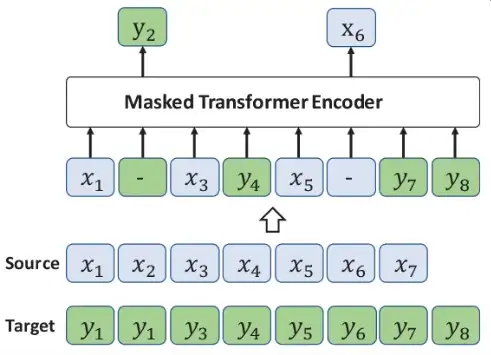
При переключении кода некоторые фразы x заменяются на y, и полученная таким образом выборка используется для обучения модели.
- Стратегия маскировки аналогична MLM.


* Включает маскирование непрерывного диапазона токенов в предложении, а затем использование модели для прогнозирования замаскированных токенов на основе выходных представлений граничных токенов
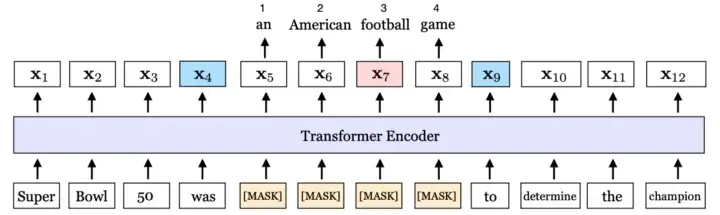
* Использовался в качестве предтренировочного задания в SpanBERT * Убыток определяется как:


- Это задание на уровне предложения, которое помогает модели изучить взаимосвязь между предложениями.
- Это задача бинарной классификации, которая включает в себя определение того, являются ли два предложения последовательными, используя выходное представление токена [CLS].
- Обучение проводится с использованием 50 % положительных и 50 % отрицательных образцов, где второе предложение не следует за первым предложением.
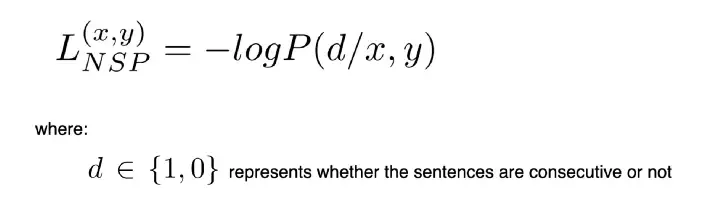
Есть много других интересных задач, которые обобщены в AMMUS <эм>!! Спасибо авторам, и, пожалуйста, прочтите, если найдете это интересным)
Также опубликовано здесь< /a>
Следуйте за мной на Medium, чтобы получать больше сообщений об ML/DL/NLP
Оригинал