

Расследование показало, что компании без разрешения обучают модели искусственного интеллекта с помощью контента YouTube
17 июля 2024 г.Для работы моделей искусственного интеллекта требуется как можно больше полезных данных, но некоторые из крупнейших разработчиков ИИ частично полагаются на расшифрованные видео YouTube без разрешения создателей, что нарушает собственные правила YouTube, как обнаружено в расследование от Proof News и Wired.
Оба издания сообщили, что Apple, Nvidia, Anthropic и другие крупные компании, занимающиеся искусственным интеллектом, обучили свои модели с помощью набора данных под названием «Субтитры YouTube», включающего расшифровки почти 175 000 видеороликов на 48 000 каналов, и все это без ведома создателей видео.
Набор данных субтитров YouTube содержит текст субтитров видео, часто с переводом на несколько языков. Набор данных был создан компанией EleutherAI, которая описала цель набора данных как снижение барьеров для разработки ИИ для тех, кто находится за пределами крупных технологических компаний. Это только один компонент гораздо более крупного набора данных EleutherAI, называемого Pile. Помимо стенограмм на YouTube, в Pile есть статьи из Википедии, речи Европейского парламента и, согласно отчету, даже электронные письма от Enron.
Однако у Pile много поклонников среди крупных технологических компаний. Например, Apple использовала Pile для обучения своей модели искусственного интеллекта OpenELM, а модель искусственного интеллекта Salesforce, выпущенная два года назад, обучалась с помощью Pile и с тех пор была загружена более 86 000 раз.
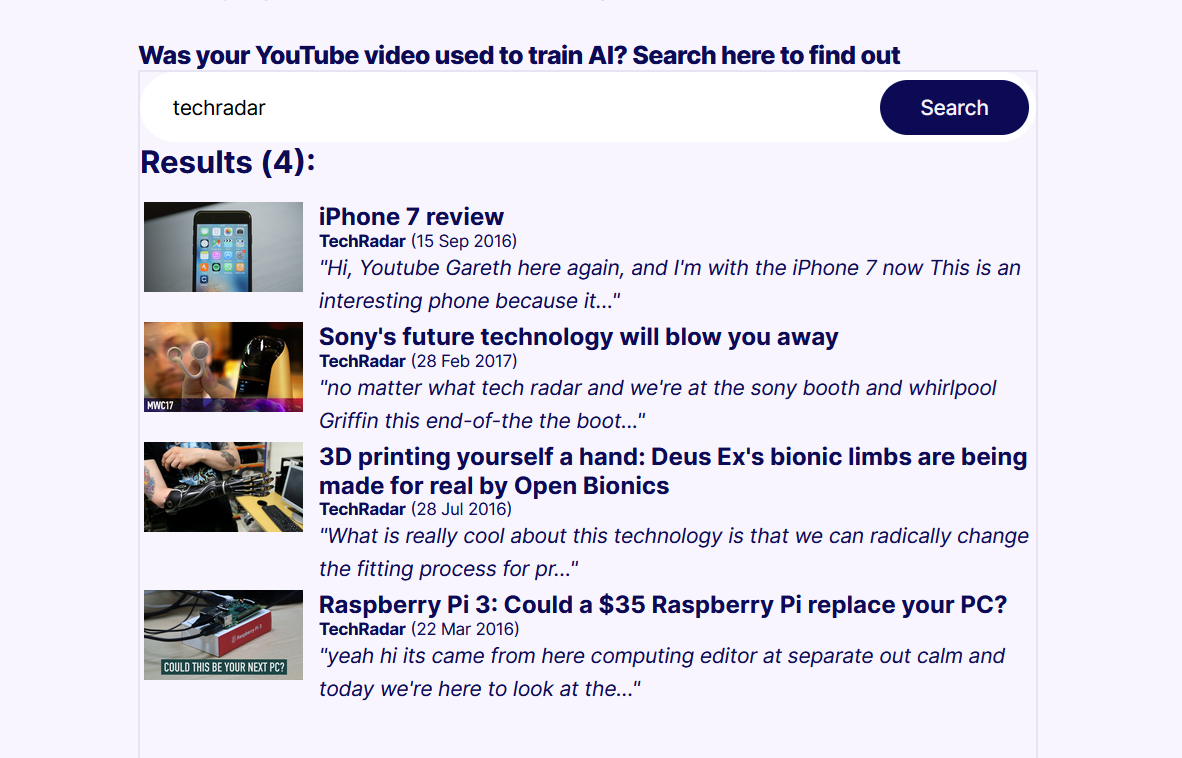
Набор данных YouTube Subtitles охватывает ряд популярных каналов новостей, образования и развлечений. Сюда входит контент от таких крупных звезд YouTube, как MrBeast и Маркес Браунли. Видео каждого из них использовались для обучения моделей ИИ. Proof News создала инструмент поиска, который будет осуществлять поиск по коллекцию, чтобы увидеть, есть ли в миксе какое-либо конкретное видео или канал. В коллекции есть даже несколько видеороликов TechRadar, как показано ниже.
Секретный обмен
Набор данных YouTube Subtitles, похоже, противоречит условиям обслуживания YouTube, которые прямо запрещают автоматическое удаление видео и связанных с ним данных. Однако это именно то, на что опирался набор данных: сценарий, загружающий субтитры через API YouTube. Расследование показало, что при автоматической загрузке были отобраны видео, содержащие около 500 поисковых запросов.
Это открытие вызвало немало удивления и гнева у опрошенных создателей YouTube Proof и Wired. Опасения по поводу несанкционированного использования контента обоснованы, и некоторые создатели были расстроены идеей, что их работа будет использоваться без оплаты или разрешения в моделях искусственного интеллекта. Это особенно актуально для тех, кто обнаружил, что набор данных включает расшифровки удаленных видео, и в одном случае данные получены от создателя, который с тех пор полностью удалил свое присутствие в Интернете.
В отчете не было комментариев от EleutherAI. Он отметил, что организация описывает свою миссию как демократизацию доступа к технологиям искусственного интеллекта путем выпуска обученных моделей. Если судить по этому набору данных, это может противоречить интересам создателей контента и платформ. Юридические и нормативные баталии по поводу ИИ уже были сложными. Подобные разоблачения, скорее всего, сделают этическую и юридическую среду разработки ИИ более коварной. Легко предложить баланс между инновациями и этической ответственностью за ИИ, но создать его будет намного сложнее.
Вам также может понравиться
- YouTube теперь будет удалять ваши дипфейки, созданные искусственным интеллектом, если вы попросите
- Хотите перейти к хорошему фрагменту видео? YouTube тестирует для этого умную функцию искусственного интеллекта
- YouTube будет использовать искусственный интеллект для вырезания музыки, защищенной авторским правом, а не для отключения звука всего видео
Оригинал