
В разреженных облаках и неоднозначных текстах эта модель ИИ все еще находит свой путь
17 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
Связанная работа
Метод
3.1 Обзор нашего метода
3.2 грубое извлечение текстовых клеток
3.3 Оценка прекрасной позиции
3.4 Цели обучения
Эксперименты
4.1 Описание набора данных и 4.2 Подробная информация
4.3 Критерии оценки и 4.4 результаты
Анализ производительности
5.1 Исследование абляции
5.2 Качественный анализ
5.3 Анализ встраивания текста
Заключение и ссылки
Дополнительный материал
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
Анонимные авторы
- Подробная информация о наборе данных Kitti360
- Больше экспериментов по экстрактору запроса экземпляра
- Анализ космического пространства текстовых клеток
- Больше результатов визуализации
- Анализ устойчивости точек
7 Подробная информация о наборе данных Kitti360

Еще 8 экспериментов на экстракторе запроса экземпляра
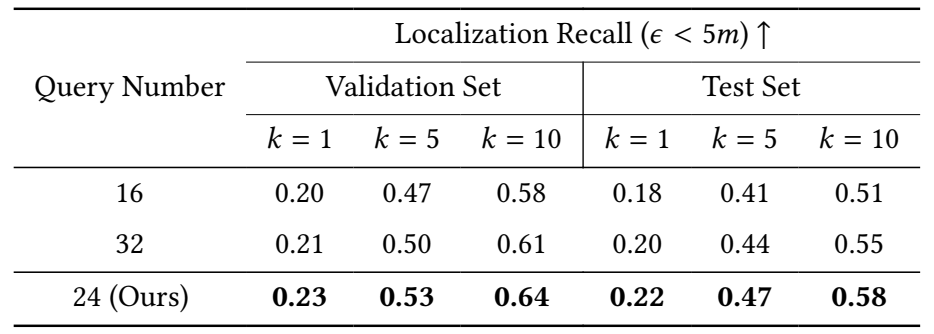
Мы проводим дополнительный эксперимент, чтобы оценить влияние количества запросов на производительность нашего экстрактора запроса экземпляра. Как подробно описано в Таблице 7, мы оцениваем частоту отзыва локализации с использованием 16, 24 и 32 запросов. Результат демонстрирует, что использование 24 запросов дает наивысшую частоту отзыва локализации, то есть 0,23/0,53/0,64 на наборе валидации и 0,22/0,47/0,58 в тестовом наборе. Этот вывод свидетельствует о том, что оптимальное количество запросов для максимизации эффективности нашей модели составляет 24.
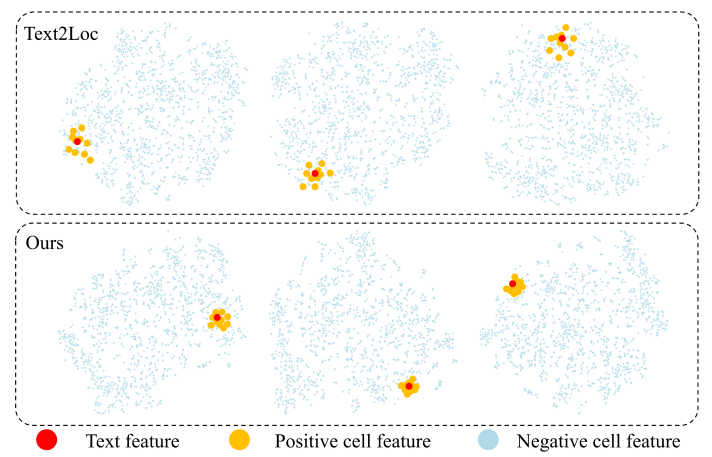
9 Анализ встроенного пространства текстовых клеток
На рис. 8 показано выровненное пространство встраивания текстовых клеток через T-SNE [37]. В сценарии без экземпляра мы сравниваем нашу модель с Text2Loc [42], используя предварительно обученную модель сегментации экземпляра, Mask3d [35], в качестве предыдущего шага. Можно наблюдать, что Text2loc приводит к менее дискриминационному пространству, где положительные клетки относительно далеки от функции текстового запроса. Напротив, наш IFRP-T2P эффективно снижает расстояние между положительными элементами клеток и функциями текстовых запросов в пространстве встраивания, тем самым создавая более информативное пространство встраивания. Это улучшение в пространстве встраивания имеет решающее значение для повышения точности поиска текстовых клеток.
10 результатов визуализации
На рис. 9 показано больше результатов визуализации, включая как результаты поиска, так и результаты оценки тонкого положения. Результаты показывают, что грубый поиск текстовых клеток служит основополагающим шагом в общем процессе локализации. Последующая оценка тонкой позиции обычно улучшает производительность локализации. Тем не менее, есть случаи, когда точность этой прекрасной оценки подвергается нарушению, особенно когда входные описания расплывчаты. Этот вредный эффект на точность иллюстрируется в 4-я ряд и 6-й строке, если рис. 9.

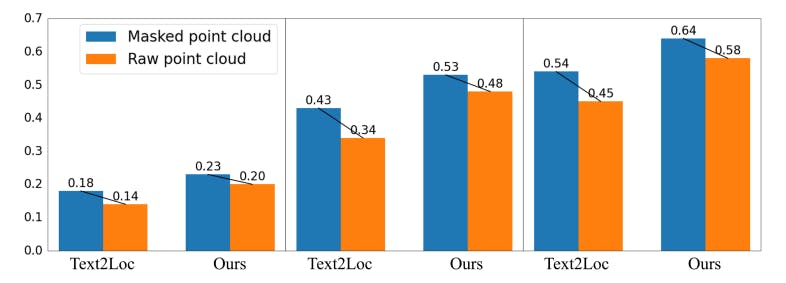
Анализ устойчивости к облаку 11 очков
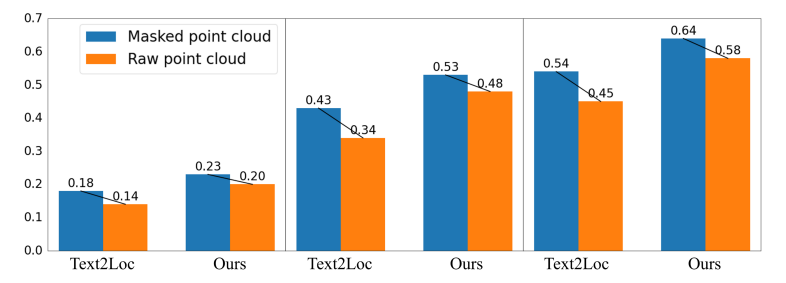
Предыдущие работы [21, 39, 42] были сосредоточены исключительно на изучении влияния текстовых модификаций на точность локализации, игнорируя влияние модификации облака точек. В этом исследовании мы также рассмотрим влияние деградации облака точек, что имеет решающее значение для полного анализа нашей модели IFRP-T2P. В отличие от накопленных точечных облаков, представленных в наборе данных Kitti360, датчики LIDAR обычно отражают только редкие облака точек в реальных настройках. Чтобы оценить надежность нашей модели в условиях редкости в облаке точечных, мы проводим эксперименты, случайно маскируя одну треть точек и сравниваем эти результаты с результатами с результатами, полученными с использованием необработанных облаков точек. Как показано на рис. 10, при приеме облако точек маскированных точек в качестве входного ввода наша модель IFRP-T2P достигает отзывов локализации 0,20 в TOP-1 с границей ошибки 𝜖 <5𝑚 в наборе валидации. По сравнению с Text2loc, который показывает деградацию 22,2%, наша модель демонстрирует более низкий уровень деградации в 15%. Этот результат указывает на то, что наша модель более устойчива к вариации облака точек.
Авторы:
(1) Lichao Wang, FNII, Cuhksz (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNII и SSE, Cuhksz (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNII и SSE, Cuhksz (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE и FNII, Cuhksz (shuguangcui@cuhk.edu.cn);
(5) Чжэнь Ли, автор -соответствующий автор из SSE и FNII, Cuhksz (lizhen@cuhk.edu.cn).
Эта статья есть
Оригинал
Recent Post
-
Bitpanda запускает Defi Wallet для Power Europe в будущее Onchain
20 августа 2025 г. -
Как Toyota Blockchain Lab хочет сделать автомобили готовыми к финансированию: Внутри предложения Toyota's Mon предложение
20 августа 2025 г. -
Получение звонков клиентов по бюджету в размере 0 долларов США: уроки от стартапа репетиторства
20 августа 2025 г. -
За кулисами эксперимента парного программирования
19 августа 2025 г. -
Простое руководство по измерению времени и труда в программировании
19 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Астрофизика
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика
- Развлечения
- ИТ и автоматизация
- Криптовалюты и блокчейн
- История и идеология
- Медицина и политика
- Личная жизнь миллиардеров
- Образование и Политика
- Туризм и отдых
- Психология и искусственный интеллект
- Удаленная работа и производительность
- Выживание
- Управление командами
- Разработка
- Международная торговля
- Корпоративная ответственность
- Социальные сети и общество
- Управление серверами
- Индустрия компьютерных игр
- Политика и климат
- Онлайн-игры
- Медицинская отрасль
- Искусственный интеллект и технологии
- Религия и мораль
- Путешествия
- Социальные сети и информация
- Технологии и медиа
- Технологии и свобода
- Электронная коммерция
- Бизнес и управление
- Психическое здоровье и технологии
- Технологии и устойчивое развитие
- Технологии и социальные сети
- Профессии
- Экономика и промышленность
- Технологии и трудоустройство
- Иммиграционная политика
- Продуктивность и фокус
- Технологии и робототехника
- Свобода слова
- Психология и власть
- Социальные сети и онлайн-платформы
- Технологии и Права Человека
- СМИ и журналистика
- Окружающая среда и здоровье
- Технологии и сервисы
- Индустрия игр
- Программирование и ИИ
- Медиа и пропаганда
- Социальная сфера
- Социальные сети и общественное мнение
- Поп-культура
- Сервисы потокового вещания
- Рынок развлечений
- Социальные медиа и политика
- Технологии и информация
- Медиа и развлечения
- Квантовая криптография
- Искусственный интеллект в индустрии развлечений
- Технологии и коммуникация
- Индустрия программирования
- Финансовая безопасность
- Международные отношения
- Бизнес и лидерство
- Технологические новости и аналитика
- Программное обеспечение и технологии
- Предпринимательство и малый бизнес
- Политика и общественный контроль
- Здравоохранение и политика
- Управление персоналом и эффективность разработки
- Технологии и ИТ‑управление
- Свобода слова и дезинформация
- Веб-дизайн и разработка
- Веб‑разработка и карьера
- Культура и общество
- Цифровые права и свобода слова
- Безопасность и искусственный интеллект
- Технологии и искусство
- Мобильные приложения
- Продуктивность
- Космические технологии и безопасность
- Технологические тренды и экономика
- Безопасность и конфиденциальность
- Продуктивность и личная эффективность
- Веб‑скрейпинг и автоматизация
- Политика и социальные сети
- Политика и безопасность
- Медиа и информационное пространство
- Медицина и Психология
- Интернет‑культура и медиа
- Технологии и разработка
- Сociety
- Развитие интеллекта и профессиональные навыки
- Linux, программирование