
Улучшение бинарной классификации с помощью LLM-генеральных вопросов
11 июня 2025 г.Авторы:
(1) Горан Мурич, Inferlink Corporation, Лос -Анджелес, (Калифорния gmuric@inferlink.com);
(2) Бен Зал, Inferlink Corporation, Лос -Анджелес, Калифорния (bdelay@inferlink.com);
(3) Стивен Минтон, корпорация Inferlink, Лос -Анджелес, Калифорния (sminton@inferlink.com).
Таблица ссылок
Аннотация и 1 введение
1.1 Мотивация
2 Связанная работа и 2,1 методы подсказки
2.2 Внутреннее обучение
2.3 модели интерпретируемость
3 Метод
3.1 Создание вопросов
3.2 Подсказка LLM
3.3. Сорбализация ответов и 3.4 Обучение классификатора
4 данные и 4.1 клинические испытания
4.2 Корпус независимости Каталонии и 4.3 Корпус обнаружения климата
4.4 Данные по медицинскому здоровью и 4.5 Данные Европейского суда по правам человека (ECTHR)
4.6 Набор данных Necure-Tos
5 экспериментов
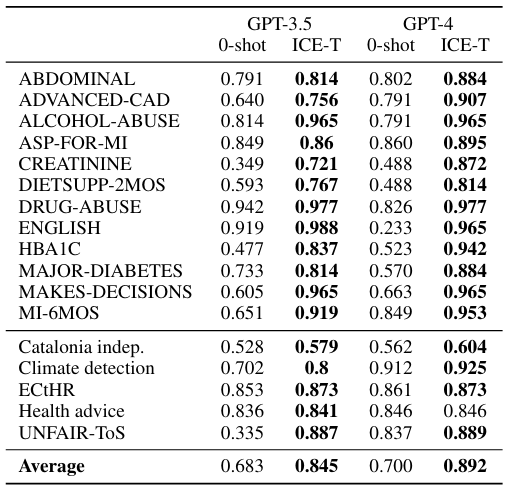
6 результатов
7 Обсуждение
7.1 Последствия для интерпретации модели
7.2 Ограничения и будущая работа
Воспроизводимость
Подтверждение и ссылки
Вопросы, используемые в методе ICE-T
5 экспериментов
Мы выполнили эксперименты по набору бинарных задач классификации на наборах данных из различных доменов, как описано в предыдущем разделе.
Чтобы создать вторичные вопросы, мы использовали большую языковую модель. Подсказывая его только один раз, мы получили набор N вторичных вопросов, которые мы приняли в соответствии с указаниями, без какого -либо выбора или модификации. Более конкретно, мы использовали следующую подсказку для создания всех второстепенных вопросов:
Вернуть {n} да/нет вопросов, которые были бы полезны, чтобы спросить, пытались ли вы определить ответ на следующий вопрос: "{primary_question}"
где n - это количество дополнительных вопросов, которые мы хотим сгенерировать, и Primary_question является основным вопросом, используемым для получения основной информации из документа. Обратите внимание, что во всех наших экспериментах n = 4. Это означает, что для каждого документа мы используем один первичный и четыре вторичного вопроса, которые обращаются одинаково при подъеме LLM. Таким образом, для каждого документа мы собираем пять ответов из LLM, которые затем вербализируются (присваивают числовое значение) на следующем шаге. Чтобы создать вторичные вопросы для всех наших экспериментов, мы используем модель OpenAI GPT-4-0125-Preview. Чтобы собрать ответы в наших экспериментах, мы используем два поколения моделей OpenAI: GPT-4-0125-Preview (Achiam et al., 2023) и GPT-3,5-Turbo-0125 (Brown et al., 2020).
Чтобы выбрать лучший классификатор, мы тренируем несколько различных алгоритмов классификации. К ним относятся K-ближайшие соседи, деревья решений, случайный лес, гауссовая наивная байеса, мультиномиальная наивная байеса, Adaboost и Xgboost. Мы используем 5-кратную перекрестную проверку на наших учебных данных, а также выполняем поиск сетки, чтобы точно настроить параметры для каждого классификатора. После обучения мы проверяем их на наборе тестовых испытаний и выбираем классификатор, который дает нам самый высокий показатель Micro F1 (µF1). Обратите внимание, что можно также настроить учебный процесс для оптимизации для определенной метрики производительности, если это необходимо для конкретного приложения. Чтобы провести эти эксперименты, мы использовали библиотеку Scikit-Learn в Python.
Микро F1 Оценка особенно полезна в наборах данных, где некоторые классы значительно недопредставлены, и где традиционные метрики могут дать вводящую в заблуждение картину производительности модели. Он рассматривает каждый экземпляр как одинаково важный, тем самым давая более точную меру производительности модели по всем направлениям. Для расчета µF1 мы используем следующую формулу:

и T P, F P и F P представляют собой количество истинных положительных результатов, ложных срабатываний и ложных отрицательных соответственно
Кроме того, мы провели анализ чувствительности, чтобы улучшить наше понимание взаимосвязи между количеством особенностей и улучшением µF1. Этот анализ помогает определить необходимое количество вторичных вопросов для достижения желаемого µF1. Для каждого набора данных мы начали с создания n = 9 вторичных вопросов и используя модель GPT-3.5-Turbo-0125 для создания ответов для каждого образца. Выходы из модели большого языка были затем преобразованы в 10-мерные векторы признаков. Впоследствии мы построили серию простых случайных лесных классификаторов, начиная с одной функции и постепенно добавляя больше функций до десяти. Учитывая случайный выбор функций для классификации, мы повторили эксперимент 100 раз. Мы вычислили µF1 для каждой итерации и набора данных. Результаты подробно описаны в разделе 6 и показаны на рисунке 3.
Эта статья есть
Оригинал
Recent Post
-
Когда ИИ становится посредником в семейных спорах о наследстве
20 августа 2025 г. -
Конец общей аннотации в здравоохранении: визуализация сердца показывает, почему
20 августа 2025 г. -
5 Рабочие процессы агента AI для повторяемого успеха (включен код)
20 августа 2025 г. -
Почему OCR борется со страницами с несколькими колоннами
20 августа 2025 г. -
Все, что я узнал (трудный путь) как начинающий основатель AI SaaS
20 августа 2025 г.
Categories
- Python
- blockchain
- web
- hackernoon
- вычисления
- вычислительные компоненты
- цифровой дом
- игры
- аудио
- домашний кинотеатр
- Интернет
- Мобильные вычисления
- сеть
- фотосъемка видео
- портативные устройства
- программного обеспечения
- телефон и связь
- телевидение
- видео
- мир технологий
- умные гиды
- облако
- искусственный интеллект
- се
- Samsung
- умные города
- digitaltrends
- отели
- Startups
- Venture
- Crypto
- Apps
- безопасность
- техника и работа
- cxo
- мобильность
- разработчик
- 5г
- майкрософт
- инновации
- Права и свободы
- Законодательство и право
- Политика и общество
- Космическая промышленность
- Информационные технологии
- Технологии
- Образование
- Научные исследования
- Автомобильная промышленность
- Программная инженерия
- IT и технологии
- Веб-разработка
- Программирование
- Автоматизация
- Карьерный рост
- Программирование и анализ данных
- Трудоустройство
- Политика
- Искусственный интеллект
- ИТ-технологии
- Программное обеспечение
- Экологическая политика
- Образование и рынок труда
- Политика и право
- Microsoft Teams и SharePoint
- Информационная безопасность
- Кибербезопасность
- Налоги
- Образование и карьера
- Интернет и технологии
- Технологии, Государственные услуги
- Политика и технологии
- Разработка программного обеспечения
- Разработка ПО
- Машинное обучение
- Налогообложение, технологии, открытый исходный код
- Финансы и налоги
- Технологии, Интернет, Экология
- Интернет, безопасность
- Технологии и политика
- Операционные системы
- Профессиональная разработка
- Технологии, Безопасность
- Интернет и общество
- Финансовая индустрия
- Налоговый учёт
- Общественное здравоохранение
- Технологическая отрасль
- Юриспруденция
- Технологии и государство
- Здоровье и фитнес
- IT-инфраструктура
- Технологии и ИИ
- Здравоохранение
- IT
- Технологии, Экономика
- Музыка и технологии
- Здоровье и питание
- IT и безопасность
- Бизнес и предпринимательство
- Технологии, Программное обеспечение
- Технологии и инновации
- Технологии, данные, этика
- Технологии и Интернет
- Технологии и SaaS
- Медицина и здравоохранение
- Онлайн-видеосервисы
- Финансы и технологии
- Чтение и саморазвитие
- Экономика и бизнес
- Безопасность данных
- Удаленная работа
- Авиация и технологии
- Технологии, Игры
- Энергетика
- Социальные сети, безопасность, технологии
- Саморазвитие
- Безопасность информации
- Бизнес и карьера
- Технологии и отношения
- Игровая индустрия
- Компьютерная индустрия
- Математика, Искусственный интеллект
- Наука и технологии
- Технологии и безопасность
- Технологии, Удаленная работа, Бизнес
- Видеоигры
- Технологии, Искусственный интеллект, Этика
- Технологии, социальные сети, 6G
- Технологии, Программирование, AI, Разработка ПО
- Программирование, Разработка ПО, Технологии
- Животные
- Технологии, Искусственный интеллект
- Программирование, карьера, технологии, обучение
- Бизнес и технологии
- Технологии, Безопасность данных
- Астрономия и физика
- Продуктивность, личное развитие
- Медиа и Технологии
- Программирование и Искусственный Интеллект
- Социальные сети
- Политика и экономика
- Технологии, Медицина, Искусственный интеллект
- Технологии и управление
- Космос и астрономия
- Общество и политика
- Космические исследования
- Веб-дизайн
- Искусственный интеллект и безопасность данных
- Технологии, Безопасность, Конфиденциальность
- Экологическая проблема
- Технологии, Погода
- Авиация
- Транспортная сфера
- Технологии и бизнес
- Игровая промышленность
- Телевидение и реклама
- Аналитика данных
- Технологии и кибербезопасность
- Маркетинг
- Технологии и гаджеты
- Технологии, Авиация, Инновации
- Финансы и инвестиции
- Технологии и общество
- Рыночный анализ
- Космология
- Данные и бизнес
- IT и программирование
- Технологии и право
- Программирование и разработка
- Астрофизика
- Медицинские технологии
- Авиационная промышленность
- Технологии и искусственный интеллект
- Генетическая инженерия
- Бизнес и инвестиции
- Компьютерная промышленность
- Психология и социология
- Образование и технологии
- Рынок труда
- Технологии, Стартапы
- Технологии, Приватность, Чтение
- Маркетинг и продажи
- Виртуальная реальность
- Технологии, Смартфоны, Маркетинг
- Технологии, Бизнес, Личностный рост
- Экологические проблемы
- Экономика и технологии
- IT и карьера
- Интернет и безопасность
- Разработка и технологии
- Биотехнологии
- Интернет-магазины, кибербезопасность
- Финансы
- Безопасность и технологии
- Экономика
- Защита данных
- Data Science
- Карьера и работа
- Финансовый успех, мошенничество, маркетинг
- Безопасность
- Экология
- Космическая индустрия
- Программирование, Python, Обучение
- Технологии искусственного интеллекта
- Технологии, Дизайн, iOS
- Программирование, DevOps, Kubernetes
- Социальные сети и пропаганда
- Корпоративная этика
- Управление IT-инфраструктурой
- Здоровье и медицина
- Медицина
- Медицинская промышленность
- Разработка и дизайн
- Искусственный интеллект, Диагностика систем
- Образование и психология
- Технологии, Автомобильная промышленность
- Автомобили и путешествия
- Астрономия и космология
- Программирование и технологии
- IT, работа в офисе, эмоциональный интеллект
- Компьютерная техника
- Здоровье и благополучие
- Управление персоналом
- Политика и управление
- Бизнес и экономика
- Социальные сети, Пропаганда, Информационная безопасность
- Технологии и автоматизация
- Геймдизайн
- Экология и технологии
- CRM-системы, IT-инфраструктура
- Права человека
- Цифровая цензура, свобода слова, технологии
- Технологии, Искусственный интеллект, Работа
- Наука о данных
- Астрономия, Наука
- Интернет и цифровые технологии
- Технологии, управление
- Интернет и связь
- Технологии и конфиденциальность
- Интернет и свобода слова
- Психология и социальные науки
- Книги и литература
- Работа и карьера
- Финансовые технологии
- Психология и саморазвитие
- IT, программирование, сети
- Технологии, Видеоигры
- Экология и энергетика
- Космонавтика
- Медицина и технологии
- Игры и развлечения
- Музыкальная индустрия
- Логистика и складирование
- Бизнес и финансы
- Экология и окружающая среда
- Правозащита
- Социальные сети и дезинформация
- Технологии и рынок труда
- Технологии, Искусственный интеллект, Рынок труда
- Технологии и будущее
- Медицина и здоровье
- Социальные медиа
- Экология, политика, общество
- Экономика и Финансы
- Разработка игр
- Пропаганда и дезинформация
- Медицинские исследования
- Онлайн-знакомства
- Политика и СМИ
- Энергетика и электромобили
- Климатические изменения
- Технологии, Рынок труда
- IT и управление данными
- Безопасность и кибербезопасность
- Интернет-технологии
- Психология и личностное развитие
- Технологии, Мессенджеры
- Цифровые технологии
- Здоровье и самосовершенствование
- Технологии и AI
- Технологии и спорт
- IT, Разработка программного обеспечения
- Экология и климат
- Космос и технологии
- Юридическая сфера
- Безопасность в интернете
- Программирование, Искусственный Интеллект, Качество ПО
- Технологии и мессенджеры
- Социальная справедливость
- Технологическая индустрия
- Личностное развитие, Time-менеджмент, Психология
- Бизнес и менеджмент
- Технологии, Микросхемы, Автономные системы
- Фриланс и предпринимательство
- Социальные сети и искусственный интеллект
- Криминальные дела
- Социальные сети, Маркетинг
- Энергетика и экология
- Технологии, Искусственный Интеллект, Полиция
- Программирование, Искусственный интеллект, Рынок труда
- Социальные сети, дезинформация, анализ данных
- Потребительские права
- Образование и наука
- Технологии и правосудие
- Технологии, Безопасность, Автомобили
- Энергетика и окружающая среда
- Личностное развитие
- Технологии и экономика
- Медиа и коммуникации
- Миграция и иммиграция
- Личностный рост
- Налоговая система
- Медиа и телевидение
- Интернет и телекоммуникации
- Технологии, Кибербезопасность
- Здоровье
- Социальные сети и карьера
- Политика и инфраструктура
- Предпринимательство
- Промышленность программного обеспечения
- СМИ и коммуникации
- Медиа и Общество
- Медицина и генетика
- Веб-разработка и дизайн
- Технологии, процессоры
- IT-индустрия
- Кинопроизводство и технологии
- Транспорт
- Текстовый анализ
- Технологии, дизайн интерфейсов
- Офисные приложения
- Технологии, Онлайн-сервисы
- Медицина и биотехнологии
- Общество и технологии
- Экономика и рынок труда
- Искусственный интеллект, программирование, аналитика
- Технологии, следствие
- Сетевые технологии
- Технологии и веб-разработка
- Программирование, Обучение, Практика
- Коммуникации и ИТ
- Технологии, Карьера, Экономика
- Технологии и транспорт
- Здравоохранение и медицина
- Технологии, Государственное управление
- IT-безопасность
- IT и разработка
- Финансы и экономика
- Социальные сети, Общество, Сообщества
- IT-разработка
- СМИ и политика
- Конфиденциальность и безопасность
- Экономика и политика
- Технологии и общественная жизнь
- Бизнес и этика
- Безопасность и защита информации
- Технологии, бизнес
- Интернет и цензура
- Государственное регулирование
- Игры, Технологии
- Технологии и оптимизация
- Технологии ИИ и машинного обучения
- Технологии, IT, карьера
- IT и программное обеспечение
- Право и преступность
- Криминал и Правоохранительные Органы
- Технологии и энергетика
- Нефтяная промышленность
- Социальные конфликты
- Преступность и безопасность
- Таможенная очистка
- Медиа и журналистика
- Технологии и разработка приложений
- Телекоммуникации
- Консалтинг и управление
- Управление человеческими ресурсами
- Онлайн-контент
- Психология и психотерапия
- Морская отрасль
- Психология и технологии
- Социальные проблемы
- Маркетинг и реклама
- Политика и власть
- Экономика и торговля
- Карьера и развитие
- Продуктивность и Управление Временем
- Технологии, Искусственный интеллект, Реклама
- Окружающая среда
- Здоровье и технологии
- Бытовая химия
- Правовая информация
- Юстиция
- Технологии и экология
- Социальные сети и безопасность
- Базы данных
- Политика и государственное управление
- Интернет и социальные сети
- Индустрия IT
- Технологии и программное обеспечение
- История и искусственный интеллект
- Рестораны и обслуживание
- Технологии и программирование
- Социология
- Телевидение и СМИ
- Психология
- Политика и бизнес
- Мобильные устройства
- Технологии и развлечения
- Экология и охрана окружающей среды
- Маркетинг и брендинг
- Медицинская индустрия
- Кибербезопасность и технологии
- Социальные сети и политика
- Развлечения
- ИТ и автоматизация
- Криптовалюты и блокчейн
- История и идеология
- Медицина и политика
- Личная жизнь миллиардеров
- Образование и Политика
- Туризм и отдых
- Психология и искусственный интеллект
- Удаленная работа и производительность
- Выживание
- Управление командами
- Разработка
- Международная торговля
- Корпоративная ответственность
- Социальные сети и общество
- Управление серверами
- Индустрия компьютерных игр
- Политика и климат
- Онлайн-игры
- Медицинская отрасль
- Искусственный интеллект и технологии
- Религия и мораль
- Путешествия
- Социальные сети и информация
- Технологии и медиа
- Технологии и свобода
- Электронная коммерция
- Бизнес и управление
- Психическое здоровье и технологии
- Технологии и устойчивое развитие
- Технологии и социальные сети
- Профессии
- Экономика и промышленность
- Технологии и трудоустройство
- Иммиграционная политика
- Продуктивность и фокус
- Технологии и робототехника
- Свобода слова
- Психология и власть
- Социальные сети и онлайн-платформы
- Технологии и Права Человека
- СМИ и журналистика
- Окружающая среда и здоровье
- Технологии и сервисы
- Индустрия игр
- Программирование и ИИ
- Медиа и пропаганда
- Социальная сфера
- Социальные сети и общественное мнение
- Поп-культура
- Сервисы потокового вещания
- Рынок развлечений
- Социальные медиа и политика
- Технологии и информация
- Медиа и развлечения
- Квантовая криптография
- Искусственный интеллект в индустрии развлечений
- Технологии и коммуникация
- Индустрия программирования
- Финансовая безопасность
- Международные отношения
- Бизнес и лидерство
- Технологические новости и аналитика
- Программное обеспечение и технологии
- Предпринимательство и малый бизнес
- Политика и общественный контроль
- Здравоохранение и политика
- Управление персоналом и эффективность разработки
- Технологии и ИТ‑управление
- Свобода слова и дезинформация
- Веб-дизайн и разработка
- Веб‑разработка и карьера